By: Greg Robidoux | Comments (47) | Related: > TSQL
Problem
Every once in awhile a table gets created without a primary key and duplicate records get entered. The problem gets even worse when you have two identical rows in the table and there is no way to distinguish between the two rows. So how do you delete the duplicate record?
Solution
One option that SQL Server gives you is the ability to set ROWCOUNT which limits the numbers of records affected by a command. The default value is 0 which means all records, but this value can be set prior to running a command. So let's create a table and add 4 records with one duplicate record.
Create a table called duplicateTest and add 4 records.
CREATE TABLE dbo.duplicateTest ( [ID] [int] , [FirstName] [varchar](25), [LastName] [varchar](25) ) ON [PRIMARY] INSERT INTO dbo.duplicateTest VALUES(1, 'Bob','Smith') INSERT INTO dbo.duplicateTest VALUES(2, 'Dave','Jones') INSERT INTO dbo.duplicateTest VALUES(3, 'Karen','White') INSERT INTO dbo.duplicateTest VALUES(1, 'Bob','Smith')
If we select all data we get the following:
SELECT * FROM dbo.duplicateTest
| ID | FirstName | LastName |
|---|---|---|
| 1 | Bob | Smith |
| 2 | Dave | Jones |
| 3 | Karen | White |
| 1 | Bob | Smith |
If we try to select the record for Bob Smith will all of the available values such as the following query:
SELECT * FROM dbo.duplicateTest WHERE ID = 1 AND FirstName = 'Bob' AND LastName = 'Smith'
We still get 2 rows of data:
| ID | FirstName | LastName |
|---|---|---|
| 1 | Bob | Smith |
| 1 | Bob | Smith |
DELETE Duplicate Records Using ROWCOUNT
So to delete the duplicate record with SQL Server we can use the SET ROWCOUNT command to limit the number of rows affected by a query. By setting it to 1 we can just delete one of these rows in the table. Note: the select commands are just used to show the data prior and after the delete occurs.
SELECT * FROM dbo.duplicateTest DECLARE @id int = 1 IF EXISTS (SELECT count(*) FROM dbo.duplicateTest WHERE ID = @id HAVING count(*) > 1 ) BEGIN SET ROWCOUNT 1 DELETE FROM dbo.duplicateTest WHERE ID = @id SET ROWCOUNT 0 END SELECT * FROM dbo.duplicateTest
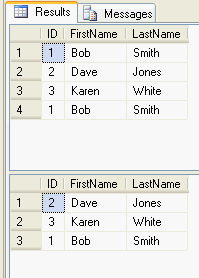
Here is a note from Microsoft about using SET ROWCOUNT:
I tested the ROWCOUNT option with SQL Server 2017 and this option still works.
DELETE Duplicate Records Using TOP
With SQL Server 2005 and later we can also use the TOP command when we issue the delete, such as the following. Note: the select commands are just used to show the data prior and after the delete occurs.
-- delete all records and add records again DELETE FROM dbo.duplicateTest INSERT INTO dbo.duplicateTest VALUES(1, 'Bob','Smith') INSERT INTO dbo.duplicateTest VALUES(2, 'Dave','Jones') INSERT INTO dbo.duplicateTest VALUES(3, 'Karen','White') INSERT INTO dbo.duplicateTest VALUES(1, 'Bob','Smith') SELECT * FROM dbo.duplicateTest DECLARE @id int = 1 IF EXISTS (SELECT count(*) FROM dbo.duplicateTest WHERE ID = @id HAVING count(*) > 1 ) DELETE TOP(1) FROM dbo.duplicateTest WHERE ID = @id SELECT * FROM dbo.duplicateTest
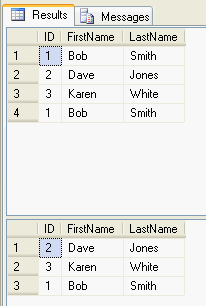
So as you can see with SQL Server 2005 and later there are two options to allow you to delete duplicate identical rows of data in your tables.
DELETE Multiple Duplicate Records Using TOP
One of the downsides to the above approaches is that they only delete one record at a time. So if there are more than two duplicates you have to rerun the commands.
Here is another option submitted by one of our readers Basharat Bhat if there are more than two duplicates.
-- delete all records and add records again DELETE FROM dbo.duplicateTest INSERT INTO dbo.duplicateTest VALUES(1, 'Bob','Smith') INSERT INTO dbo.duplicateTest VALUES(2, 'Dave','Jones') INSERT INTO dbo.duplicateTest VALUES(3, 'Karen','White') INSERT INTO dbo.duplicateTest VALUES(1, 'Bob','Smith') INSERT INTO dbo.duplicateTest VALUES(1, 'Bob','Smith') SELECT * FROM dbo.duplicateTest DECLARE @id int = 1 DELETE TOP (SELECT COUNT(*) -1 FROM dbo.duplicateTest WHERE ID = @id) FROM dbo.duplicateTest WHERE ID = @id SELECT * FROM dbo.duplicateTest
DELETE Multiple Duplicate Records Using CTE
Here is another option submitted by one of our readers. This approach checks all of the columns to make sure that each column is a duplicate versus just the ID column in the above examples. This will delete records when there are 2 or more duplicate rows.
DELETE FROM dbo.duplicateTest INSERT INTO dbo.duplicateTest VALUES(1, 'Bob','Smith') INSERT INTO dbo.duplicateTest VALUES(2, 'Dave','Jones') INSERT INTO dbo.duplicateTest VALUES(3, 'Karen','White') INSERT INTO dbo.duplicateTest VALUES(1, 'Bob','Smith') INSERT INTO dbo.duplicateTest VALUES(1, 'Bob','Smith') SELECT * FROM dbo.duplicateTest; with temp(rank1,id ,fname,lname) as ( select row_number() over ( partition by ID, FirstName, LastName order by ID, FirstName, LastName ) , * from duplicateTest ) delete from temp where rank1 > 1; SELECT * FROM dbo.duplicateTest;
DELETE Multiple Duplicate Records Using %%lockres%%
Here is another option submitted by another one of our readers. This approach checks all of the columns to make sure that each column is a duplicate versus just the ID column in the above examples. This will delete records when there are 2 or more duplicate rows.
DELETE FROM dbo.duplicateTest INSERT INTO dbo.duplicateTest VALUES(1, 'Bob','Smith') INSERT INTO dbo.duplicateTest VALUES(2, 'Dave','Jones') INSERT INTO dbo.duplicateTest VALUES(3, 'Karen','White') INSERT INTO dbo.duplicateTest VALUES(1, 'Bob','Smith') INSERT INTO dbo.duplicateTest VALUES(1, 'Bob','Smith') SELECT * FROM dbo.duplicateTest; DELETE FROM a FROM dbo.duplicateTest a JOIN ( SELECT MAX(%%lockres%%) pseudoID, id, FirstName, LastName FROM dbo.duplicateTest GROUP BY id, FirstName, LastName ) b ON b.id = a.id AND b.LastName = a.LastName AND b.FirstName = a.FirstName AND b.pseudoID <> a.%%lockres%% SELECT * FROM dbo.duplicateTest;
Next Steps
- Take a look how the ROWCOUNT command can be used to affect the results of your query
- Also take a look at the TOP command and changes that have been implemented with SQL Server
- Start using TOP instead of ROWCOUNT for SQL Server






About the author
 Greg Robidoux is the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server. He is also one of the co-founders of MSSQLTips.com. Greg has been working with SQL Server since 1999, has authored numerous database-related articles, and delivered several presentations related to SQL Server. Before SQL Server, he worked on many data platforms such as DB2, Oracle, Sybase, and Informix.
Greg Robidoux is the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server. He is also one of the co-founders of MSSQLTips.com. Greg has been working with SQL Server since 1999, has authored numerous database-related articles, and delivered several presentations related to SQL Server. Before SQL Server, he worked on many data platforms such as DB2, Oracle, Sybase, and Informix.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
