By: Chad Boyd | Comments | Related: 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | > Fragmentation and Index Maintenance
In the prior post (http://www.mssqltips.com/sqlservertip/2261/sql-server-fragmentation-storage-basics-and-access-methods-part-1-of-9/), we discussed some basics around storage structures and access methods that will play a key role in understanding the effects of fragmentation as we move forward with this series. In this 2nd post, we'll briefly talk about what fragmentation is, and the different types of fragmentation that exist in Sql Server specifically. In the following posts in the series, we'll hit on how fragmentation impacts performance (and when it doesn't), when you need to worry about it (and when you don't), how to check for fragmentation, how to address it, and how to avoid it.
Fragmentation by and of itself in the Sql Server data storage world could I guess be described as some variation of non-contiguous data, whether logical or physical. We could go into quite a discussion on what it is and where it applies, since it can apply in lots of places - for the purposes of what this blog(s) are going to discuss, we'll be talking strictly how it relates to data page fragmentation (including clustered indexes, heaps, and non-clustered indexes). It comes in a few different flavors (and probably even others that I'm not going to discuss here) - there is really no defined terminology (that I know of anyhow) for the different types, so we'll use the following 3 major topics and terms for these posts anyhow:
LOGICAL FRAGMENTATION
We're going to use this terminology for what is arguably the most common type of fragmentation - leaf pages of indexes becoming physically unordered within a given file so as to no longer match the logical left-to-right linked-list ordering of the pages. This type of fragmentation as we'll use it here relates in no way whatsoever to the physical pages being contiguous (i.e. back to back, side by side, etc.) within the given file, but only to the physical order of the pages within the file compared to the logical order in the linked list; the difference between contiguous pages and properly ordered pages would be that to be contiguous, the pages must exist physically in side-by-side positions within the file (i.e. pages 1,2,3,4,5,6,...n) with no gaps in between - to be properly ordered, the pages must exist simply in logical order and on ever-increasing physical positions within the file (i.e. pages 10, 17, 22, 23, 28, 42,...n). Contiguous pages (for purposes of these conversations) are always also properly ordered pages, but properly ordered pages aren't necessarily contiguous...
Logical fragmentation also encompasses page density, or how full a page is. We'll get into this more throughout the blog(s), but given that the page is the basic unit of storage for Sql Server, it is also the basic size of data stored in your data cache (a subset of your buffer pool, usually the largest subset); hence, the more dense the pages are, the less cache that is either used or needed to read the same amount of data - the less dense the pages, the more cache that is needed, the more pages that need to be read/inspected, and the more pages that are needed to store the same amount of data. This particular portion of logical fragmentation can actually lead to quite an interesting discussion - it's really the only kind of "fragmentation" that can actually be helpful in some cases. On the flip side, it's also the only kind of fragmentation that will cause performance degradation for data that is in cache and not on disk (all other types of fragmentation only impact performance when actual disk IO is incurred - once the data is in cache, all other types of fragmentation are totally irrelevant). When talking about reading data, or selecting data, this type of fragmentation (like all others) is bad, for all the reasons mentioned above (i.e. more pages to store the same amount of data, bloated data cache, more pages to scan/seek on when looking for records, etc.). However, since most database systems aren't read-only in nature, at some point data needs to be written to the database. When new data is written to the database and it needs to be placed in a particular location within an index (determined by the index key(s)), or if an existing row is updated to contain larger variable-length column values, that data will need space to reside within the appropriate logical location in the index. If free space exists on the page where the existing record already resides, or on the page where a new record will be inserted into, then the new data is simply written to that page and life is good. If the page is completely full (or full enough to not have the required amount of space for the new data), then a page split will occur, a new page will be created, and then the new data will be written (we will discuss page splits in more depth in a later blog). Obviously, this latter type of write operation will be significantly slower than the prior write operation where free space existed on the page. This is the case where purposely having a lower page density and actually introducing some fragmentation into the system will help - and this is the only kind of fragmentation that ever has a possible up-side. We'll discuss this a lot more in a later blog when we talk about page splits in more detail.
To show some examples, the following graphic displays a perfectly contiguous, perfectly logical ordered index structure:
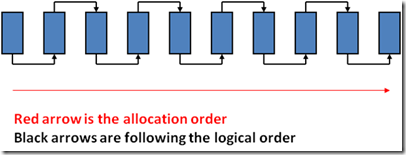
This next graphic displays what the same structure might look like with pages that aren't full, and aren't logically ordered, and also aren't contiguous:
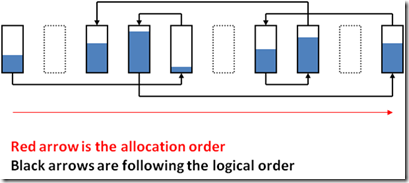
Images originally created by and courtesy of Paul Randal from SQLSkills.com from various presentations.
EXTENT FRAGMENTATION
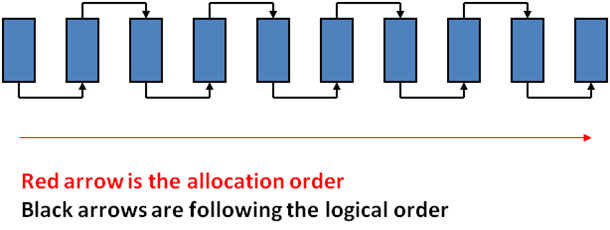
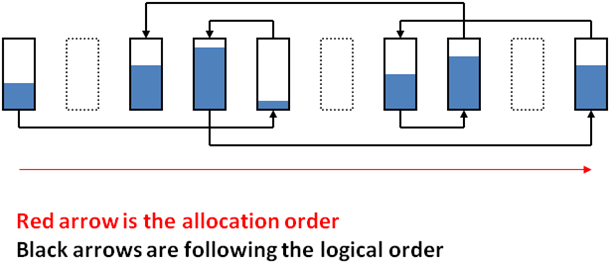
This terminology refers to the fragmentation of the actual physical location of extents/pages within Sql Server data file(s) - it's typically called extent fragmentation due to the fact that extents are the primary allocation unit for Sql Server data, and the majority of the time allocation of space within a file will occur as a full extent, which is made up of 8 contiguous pages. Therefore, arguably the majority of the time this type of fragmentation manifests itself as interleaved extents that are allocated to different structures and the pages within each of these extents are mostly contiguous. If you go back to my discussion on the differences between properly ordered pages and contiguous pages, this type of fragmentation is referring to properly ordered pages that are not contiguous, not extents that are not contiguous - given that space is allocated in extents and not pages, much of the time it can be easy to think of this type of fragmentation as only referring to out of order extents.
To provide a quick example of the extent fragmentation that is arguably most common, it occurs when data is being inserted into the database within multiple different tables, and extents are being allocated for these insertions within a given data file in a round-robin-ish fashion (i.e. extent #1 goes to index #1, extent #2 goes to index #2, extent #3 goes to index #3, then extent #4 goes to index #1, then extent #5 goes to index #3, etc., etc.). This results in properly ordered pages for the given indexes (i.e. no logical fragmentation), but not in contiguous pages, since the pages are "interleaved" with each other by nature of the extents being interleaved (you end up with 8 contiguous pages, then an extent for another object(s), then 8 more contiguous pages, etc., etc., give or take). In this case, you might end up with extents that look like the following within the SQL data file(s):

Image originally created by and courtesy of Paul Randal from SQLSkills.com from various presentations.
While this describes a common form of this type of fragmentation, I personally think the term "extent fragmentation" can be a bit deceiving, since the name tends to imply that it is only looking at the "extent" level of storage; since pages in a linked list don't necessarily have to exist on the same extent, even those that are previous/next in the linked chain (think of a page split scenario where the current extent is already full), it really comes down to where the pages exist - of course, you could make the argument that in that case, it still has to "jump" between 2 different extents, which is true...just realize that you can have extent fragmentation even if all the extents for an object are contiguous, but the pages within them are not (which is also a form of logical fragmentation).
Which brings up another interesting point that can be touched on - extent fragmentation could be coined as really just another form of logical fragmentation in one sense, since it really only manifests itself within the Sql Server data file, which Sql Server interacts with via standard APIs. A Sql Server data file is the container for data that Sql server knows about, however that data file may reside in all kinds of different sectors on the actual spindles. And, I'm not even going to start down the path of discussing multiple files in a single filegroup yet. Sql Server really has no 'direct' control over where new page allocations come from as they reside "on-disk", especially with the adoption of SAN systems in today's environments. Though Sql does do everything it can to try and ensure contiguous data on a given disk, in many systems this isn't even possible (think of SANs where a request for an extent of space can come from anywhere the SAN software sees fit, which is most likely from a variety of spindles). Additionally, think of the case where file-growths occur on a Sql data file - from the time the data file was initialized to the current state, it may have gone through many, many file-growths, and in between each of these file-growths, the storage system has allocated space for lots of other reasons, applications, etc. - in this case, the actual data physically on-disk is most likely spread all over the place - enter the next type of fragmentation:

FILE-LEVEL FRAGMENTATION
File-level fragmentation is basically what I was describing in the last paragraph above - this is your typical fragmentation of data blocks as they reside physically on-disk. SQL Server has limited control over this type of fragmentation - much of it is controlled by the disk subsystem and our decision on where to place files, how many to have, our choice of storage, etc. All SQL Server can do really is request space for the given data file(s) when it is told to do so, or when it needs to - these requests are then passed to the appropriate APIs, storage drivers, etc. which handle the allocation of new space on-disk. The best SQL can do is request this space be contiguous, but it will only at best get a full contiguous block in the size requested, and this assumes you are using a single spindle with a single file. Once you start introducing things like RAID, SANs, etc., you are now treading into a territory where it is nearly completely out of SQL Server's control. Now, this isn't to say that introducing these types of systems is bad - RAID and SANs are both good technologies that are very good at what they do. RAID is all about spreading data across multiple spindles for either performance improvements, data protection, or a combination of both - if data is being spread across multiple spindles, then you are by nature not going to have contiguous data on a single spindle - of course, the benefit here is that multiple spindles can service more requests than a single spindle, and you have data protection. SANs are even more complex in that they implement RAID (in quite a few varieties) and also provide tons of management capabilities, options, etc., etc., making it even more complex to understand where exactly your data resides on-disk. Again, I'm not trying to say that RAID and SANs are bad - just trying to give an idea of how complex understanding file-level fragmentation can be in different systems that SQL Server will be running on. Of course, if you'd like a very simple example, let's say you're running SQL on a laptop with a single LUN that is supported by a single spindle - in this scenario it is a bit easier to understand - you simply have the SQL Server data file(s) stored in blocks on this disk, and if you pre-allocate the appropriate space for the database supported by the file(s), and the contiguous space on disk is available, then you'll most likely end up with a very contiguous file on-disk. If you took the disk and sliced it into blocks, a single disk with file-level fragmentation for SQL Server data files might look something like this:

Image originally created by and courtesy of Paul Randal from SQLSkills.com from various presentations.
We could actually talk quite a bit about this and how it can impact that server, things you can do to avoid it, etc., which we will do in a future post...
Ok, that covers the different types of fragmentation at a high-level - next post we'll start talking about how these different types of fragmentation are caused, and possibly what can be done to avoid them (might be the next post after the next post)...
Enjoy!






About the author
 Chad Boyd is an Architect, Administrator and Developer with technologies such as SQL Server, .NET, and Windows Server.
Chad Boyd is an Architect, Administrator and Developer with technologies such as SQL Server, .NET, and Windows Server.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
