By: Murali Krishnan | Comments (10) | Related: > Replication
Problem
Some time back, I was discussing multi-master database replication requirements which have data redundancy and read performance improvements. As per our need, we have multiple locations and the databases should be synchronized continuously and users can connect to any location if needed to do any kind of operation (Insert/Update/Delete) irrespective of the location. The expected functionality can be achieved with peer-to-peer (P2P) transactional replication. In this tip we look at an overview of P2P replication.
Solution
The peer-to-peer replication was introduced in SQL Server 2005. It can help scale out an application and implement high availability. When we configure P2P between the servers (called a node), all the inserts, updates and deletes are propagated to the other nodes when the command is executed. Thus all the nodes are updated and the databases stay synchronized in near real-time.Peer-to-Peer Transactional Replication
P2P replication is built on transactional replication. It maintains transactional replication between servers and allows publishers and subscribers to send data to each other. Thus participating servers are updated near real-time based on the scheduled frequency.
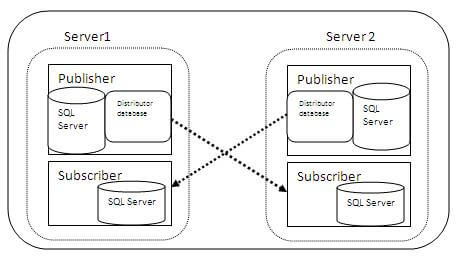
Since we know the functionality of transactional replication and the role of the publisher, distributor and subscriber, let me explain peer-to-peer in terms of transactional architecture. In the peer-to-peer transactional replication, each node acts as publisher and subscriber to one another. As specified in the below image, Server1 and Server2 are both a Publisher and Subscriber. When data are inserted/Updated/Deleted in any of the servers (node) the other one is updated through its publisher and subscriber.
Pros:
- Read performance can be improved significantly through distributing load among the servers since the peer-to-peer replication topology helps to have the same data set in multiple locations.
- Conflict detection is available with SQL Server 2008, so most of the issues can be resolved with minimal effort.
- All the participating servers in the P2P setup can be used for all types of activities since the servers have the same data. If one server is down, the other nodes continue to serve the user requests. So a single point of failure issue can be overcome.
- The peer-to-peer setup can be made as a high availability solution.
- There are administration enhancements with SQL server 2008 like nodes can be added or removed without disturbing the existing setup.
- Schema changes can be done while database is online in SQL Server 2008.
- Replication Monitor options are enhanced and Replication Agent related issues are addressed with more specific error messages in SQL Server 2008.
Cons:
- The peer-to-peer replication option is available only in the Enterprise edition.
- In the p2p setup, the write operation needs to be maintained at only one node otherwise it may lead to data conflicts.
- Performance may be an issue when there more participating servers.
- Row and Column filter options are not available.
- Participating databases must have identical schema and data.
- Identity column usage may need manual intervention.
P2P and Ring Topology
The peer-to-peer transactional replication setup can form a ring topology. The below image (from MSDN) shows three different database locations with peer-to-peer transactional replication. The locations are replicating data respectively from Location1 <- -> Location 2, Location2 <- -> Location3 and Location3 <- -> Location1. If any one of the locations is down, the other locations can still stay synchronized, because each node acts as a publisher and a subscriber.
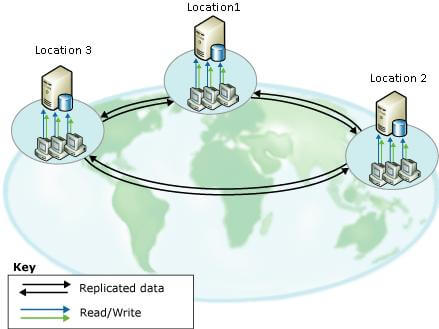
With this topology, a database implementation can be planned across multiple locations and the applications can share this setup for read functionality improvements. Also if a location is down, the application can redirect to one of the other locations, so application database availability can be managed.
Note:
In addition, peer-to-peer transactional replication can be a substitute for an "updatable subscription for transactional replication" since updatable subscriptions are a deprecated feature in SQL Server 2008. For more info refer to this link.
Next Steps
- Overview of Peer-to-Peer Transactional Replication - SQL Server 2008 from MSDN.
- Step by Step: Configure Peer-to-Peer Transactional Replication (SQL Server Management Studio)
- Administer a Peer-to-Peer Topology: Replication Transact-SQL Programming from MSDN.
- SQL Server 2005 Peer to Peer Replication






About the author
 Murali Krishnan is a Lead Consultant with vast experience in Database/BI Design, Development and Administration.
Murali Krishnan is a Lead Consultant with vast experience in Database/BI Design, Development and Administration.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
