By: Ben Snaidero | Comments (16) | Related: 1 | 2 | 3 | 4 | 5 | 6 | > Locking and Blocking
Problem
At some time or another every DBA has been faced with the challenge of solving a deadlock issue in their SQL Server database. In the following tip we will look at how indexes and more specifically clustered indexes on the right columns can help reduce the chance of your applications receiving this dreaded error:
Msg 1205, Level 13, State 51, Line 3 Transaction (Process ID 56) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
Solution
Let's first setup our test scenario which we will use to demonstrate the different types of locks SQL Server will acquire based on the indexes on the table. As well we will look at under which circumstances we will encounter a deadlock. All of the following examples consist of two processes accessing different records in the same table in the following order:
Transaction 1 - BEGIN TRAN Transaction 1 - UPDATE TABLE 1 Transaction 2 - BEGIN TRAN Transaction 2 - UPDATE TABLE 2 Transaction 2 - UPDATE TABLE 1 Transaction 1 - UPDATE TABLE 2
Sample SQL Server Table and Data Population
For our example, let's setup two sample tables and populate each of the tables with data. Here is the code:
-- Table creation logic CREATE TABLE [dbo].[TABLE1] ([col1] [int] NOT NULL,[col2] [int] NULL,[col3] [varchar](50) NULL) GO CREATE TABLE [dbo].[TABLE2] ([col1] [int] NOT NULL,[col2] [int] NULL,[col3] [varchar](50) NULL) GO ALTER TABLE dbo.TABLE1 ADD CONSTRAINT PK_TABLE1 PRIMARY KEY CLUSTERED (col1) GO ALTER TABLE dbo.TABLE2 ADD CONSTRAINT PK_TABLE2 PRIMARY KEY CLUSTERED (col1) GO -- Populate tables DECLARE @val INT SELECT @val=1 WHILE @val < 1000 BEGIN INSERT INTO dbo.Table1(col1, col2, col3) VALUES(@val,@val,'TEST') INSERT INTO dbo.Table2(col1, col2, col3) VALUES(@val,@val,'TEST') SELECT @val=@val+1 END GO
SQL Server Deadlock Example
Let's run the following code in two separate SQL Server Management Studio sessions and see what happens.
Note: In all below examples SPID 55 and 56 represent the first and second transaction respectively.
-- 1) Run in first connection BEGIN TRAN UPDATE dbo.TABLE1 SET col3 = 'TEST' where col2=1 -- 2) Run in second transaction BEGIN TRAN UPDATE dbo.TABLE2 SET col3 = 'TEST' where col2=2 UPDATE dbo.TABLE1 SET col3 = 'TEST' where col2=2 -- 3) Run in first connection UPDATE dbo.TABLE2 SET col3 = 'TEST' where col2=1
After executing the last statement we receive the following message:
Msg 1205, Level 13, State 51, Line 3 Transaction (Process ID 56) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
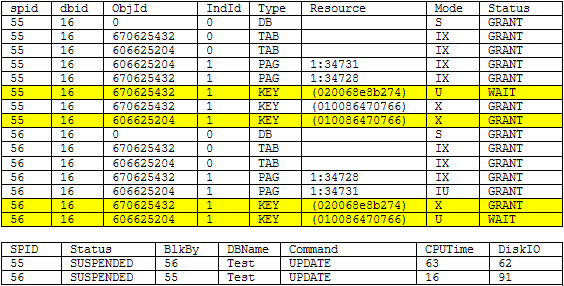
Below are the results of sp_lock and sp_who2 right before SQL Server detected the deadlock. We can see by looking at the highlighted records that we are going to have a deadlock situation as each transaction is trying to lock the same record in each table. We should be able to avoid this situation as these two processes are trying to update different records.
Be sure to commit the transactions in the earlier SQL Server Management Studio sessions. Here is the code:
COMMIT
SQL Server Deadlock Resolution - Add NonClustered Index Option
Let's first try to solve this by adding an index to col2 in each of our tables.
CREATE NONCLUSTERED INDEX IX_TABLE2 ON dbo.TABLE2 (col2) GO CREATE NONCLUSTERED INDEX IX_TABLE1 ON dbo.TABLE1 (col2) GO
Running the same scenario as above we no longer encounter a deadlock. Below are the results of sp_lock and sp_who2 right before each transaction executed the COMMIT statement. We can see by looking at the highlighted records that each transaction is only locking the rows that they are updating (pay special attention to the Resource column) so in this case there is no deadlock. Be sure to commit the records as shown above.
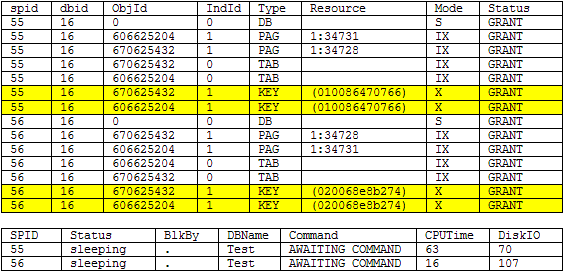
Testing the Add NonClustered Index Option to resolve the SQL Server Deadlock
Now that we have col2 indexed let's see what happens if we try to update col2. Let's run the following code in two separate SQL Server Management Studio sessions:
-- 1) Run in first connection BEGIN TRAN UPDATE dbo.TABLE1 SET col2=1 where col2=1 -- 2) Run in second transaction BEGIN TRAN UPDATE dbo.TABLE2 SET col2=2 where col2=2 UPDATE dbo.TABLE1 SET col2=2 where col2=2 -- 3) Run in first connection UPDATE dbo.TABLE2 SET col2=1 where col2=1
After executing the last statement we receive the following message:
Msg 1205, Level 13, State 51, Line 3 Transaction (Process ID 56) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
Below are the results of sp_lock and sp_who2 right before SQL Server detected the deadlock. We can see by looking at the highlighted records that we are going to have a deadlock situation as each transaction is trying to lock the same record in each table. We should also be able to avoid this situation as these two processes are trying to update different records. Be sure to commit the records as shown above.
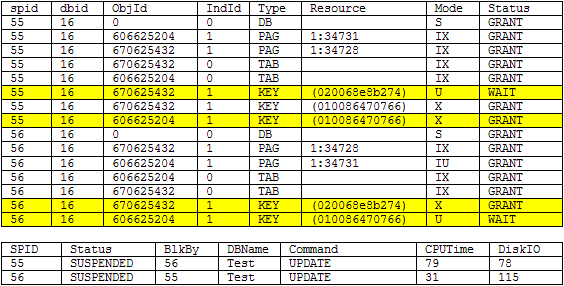
SQL Server Deadlock Resolution - Change Clustered Index Option
Now let's see if we can solve this deadlock issue by changing the clustered index on the table. We will make the primary key index nonclustered and the col2 index clustered on each table respectively.
DROP INDEX IX_TABLE1 ON dbo.TABLE1 GO ALTER TABLE dbo.TABLE1 DROP CONSTRAINT PK_TABLE1 GO ALTER TABLE dbo.TABLE1 ADD CONSTRAINT PK_TABLE1 PRIMARY KEY NONCLUSTERED (col1) GO CREATE UNIQUE CLUSTERED INDEX IX_TABLE1 ON dbo.TABLE1 (col2) GO DROP INDEX IX_TABLE2 ON dbo.TABLE2 GO ALTER TABLE dbo.TABLE2 DROP CONSTRAINT PK_TABLE2 GO ALTER TABLE dbo.TABLE2 ADD CONSTRAINT PK_TABLE2 PRIMARY KEY NONCLUSTERED (col1) GO CREATE UNIQUE CLUSTERED INDEX IX_TABLE2 ON dbo.TABLE2 (col2) GO
Running the same scenario as above we no longer encounter a deadlock. Below are the results of sp_lock and sp_who2 right before each transaction executed the COMMIT statement. We can see by looking at the highlighted records that each transaction is only locking the rows that they are updating (pay special attention to the Resource column) so in this case there is no deadlock. Be sure to commit the records as shown above.
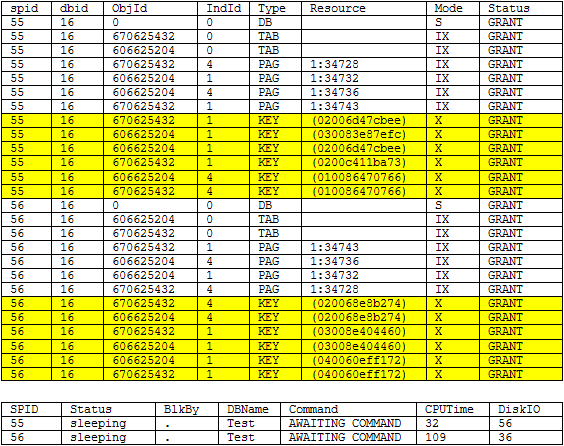
In addition to using sp_lock and sp_who2 we can use the query plan for one of the statements from our test scenario, UPDATE dbo.TABLE1 SET col2=1 where col2=1, to highlight why we see the locking that we are seeing. For the scenario with the clustered unique index we see the optimizer chose to do an index seek hence it only locked the records that it was updating allowing other processes to update other records in the table concurrently.
If we were to look at the query plan for the previous scenario we can see that in that case the optimizer chose to do an index scan hence it acquired shared locks on all the records it scanned. This means that no other processes can update any of these records until these shared locks are released. That is why we saw a deadlock in the previous scenario.
Summary
Careful consideration needs to be taken when laying out the indexes on your SQL Server tables and even more attention placed when deciding on which column(s) the clustered index should be put on as this can have a dramatic impact on locking in your database. In my experience I have found columns that are heavily used in WHERE clauses are usually a good candidate, but there are many factors (table size, heavily skewed data, other indexes, etc.) that can affect the query plan and locks that the SQL Server optimizer decides to use during execution. Testing with your application/database should be done to ensure that you are getting the best performance possible.
Next Steps
- Use query plans and profilerto provide more insight as to why you may be encountering deadlocks
- Ensure all your tables have a clustered index. Check out the SQL Server Tables without a Clustered Indextip for useful queries to diagnose the issue in your SQL Server databases.
- Identify columns in your tables that are a good candidate for clustered index






About the author
 Ben Snaidero has been a SQL Server and Oracle DBA for over 10 years and focuses on performance tuning.
Ben Snaidero has been a SQL Server and Oracle DBA for over 10 years and focuses on performance tuning.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
