By: Aaron Bertrand | Comments (5) | Related: > Error Handling
Problem
With the advent of SQL Server 2005, many people adopted the belief that they could abandon all of their proactive error handling techniques and use this shiny new TRY/CATCH mechanism. While TRY/CATCH certainly makes for easier programming, and aligns in general with methodologies used in more mature languages, it isn't always a "free" way to perform error handling.
Solution
It is easy to determine whether we should be allowing the engine to capture all of our exceptions for us, or if it is worth the effort to prevent exceptions when we can. Let's consider a simple table with a primary key containing 100,000 unique values:
CREATE TABLE dbo.Numbers
(
n INT PRIMARY KEY
);
INSERT dbo.Numbers(n)
SELECT TOP (100000) rn = ROW_NUMBER() OVER
(ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.objects AS s2;
Now given this table, let's consider a very contrived example where we have users trying to insert numbers into the table. They may not know there's a primary key, and they may not have the ability to check what values are already there. They just know that they need to call a stored procedure called something like dbo.InsertNumber and pass the number they want to add to the table. One way that dbo.InsertNumber could be coded is to just try and insert the parameter passed in, and bubble an exception back to the caller when it fails. But most of us have procedures that are a little more user friendly than that. We probably wrap our INSERT statement inside of TRY/CATCH like the following (I'll leave out friendlier error messages, logging, etc. for the purposes of this discussion, and we can pretend that there is more than just the INSERT going on inside the transaction):
CREATE PROCEDURE dbo.InsertNumber_JustInsert
@Number INT
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRY
BEGIN TRANSACTION;
INSERT dbo.Numbers(n) SELECT @Number;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- error handling goes here
ROLLBACK TRANSACTION;
END CATCH
END
GO
In most scenarios, if you are doing performance testing, you probably don't really test the throughput for this procedure when the exception is raised, because most people think an exception is the exception (no pun intended). I've long been a believer that exception handling is expensive, and as such I've usually written the procedure this way (changes highlighted in bold):
CREATE PROCEDURE dbo.InsertNumber_CheckFirst
@Number INT
AS
BEGIN
SET NOCOUNT ON;
IF NOT EXISTS
(
SELECT 1 FROM dbo.Numbers WHERE n = @Number
)
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
INSERT dbo.Numbers(n) SELECT @Number;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- error handling goes here
ROLLBACK TRANSACTION;
END CATCH
END
END
GO
Obviously it is still possible that, even with the check, in a highly concurrent system some other session may have inserted the same number I'm attempting after I've performed the existence check but before I've actually attempted the INSERT. I've purposely left non-default isolation levels out of the discussion to keep it simple, but for now we can just assume that in some cases we will still hit our CATCH block.
Now, you may not be convinced that this is actually faster, but think about this: the EXISTS check performs a seek, but so does the code that checks for a violation against the index. So that part is essentially a wash, and then add both the transaction and error handling scaffolding, and I suspect that in cases where the value already exists, that will make the initial check negligible in comparison.
But let's not take my relatively unscientific word for it; let's test it! Let's say we want to test inserting 100,000 numbers, in four different scenarios:
- All insert succeed
- 66% of inserts succeed
- 33% of inserts succeed
- No inserts succeed
To perform this testing, we need two things: (a) a procedure that loops and tries to insert unique and non-unique rows using either of the two procedures above, and (b) a log table that will keep track of how long each batch takes. Here is the log table:
CREATE TABLE dbo.InsertLog
(
Test VARCHAR(32),
Step TINYINT,
UniqueRows INT,
dt DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP()
);
GO
And here is the procedure - which takes @Test and @UniqueRows as parameters, iterates through a cursor that combines the right mix of numbers that will and won't violate the constraint, and calls the relevant stored procedure based on the test (which, for simplicity, I'll call 'JustInsert' and 'CheckFirst'):
CREATE PROCEDURE dbo.InsertNumber_Wrapper
@Test VARCHAR(32),
@UniqueRows INT
AS
BEGIN
SET NOCOUNT ON;
-- always
DELETE dbo.Numbers WHERE n > 100000;
-- record a log entry for step 1 (start)
INSERT dbo.InsertLog(Test, Step, UniqueRows) SELECT @Test, 1, @UniqueRows;
DECLARE @n INT;
DECLARE c CURSOR LOCAL STATIC READ_ONLY FORWARD_ONLY FOR
SELECT n FROM
(
-- to generate successes; unique values come from > 100000
SELECT TOP (@UniqueRows) n = n + 100000 FROM dbo.Numbers
ORDER BY n
) AS x(n)
UNION ALL
SELECT n FROM
(
-- to generate failures; duplicate values come from <= 100000
SELECT TOP (100000 - @UniqueRows) n FROM dbo.Numbers
ORDER BY n
) AS y(n)
ORDER BY n;
OPEN c;
FETCH NEXT FROM c INTO @n;
-- trudge through cursor
WHILE (@@FETCH_STATUS <> -1)
BEGIN
IF @Test = 'JustInsert'
EXEC dbo.InsertNumber_JustInsert @Number = @n;
IF @Test = 'CheckFirst'
EXEC dbo.InsertNumber_CheckFirst @Number = @n;
FETCH NEXT FROM c INTO @n;
END
CLOSE c;
DEALLOCATE c;
-- record a log entry for step 2 (end)
INSERT dbo.InsertLog(Test, Step, UniqueRows) SELECT @Test, 2, @UniqueRows;
END
GO
Now we have a table to operate on, a procedure to call, and a log table to store results. The following batch will test the inserts in each scenario I've described:
EXEC dbo.InsertNumber_Wrapper @Test = 'CheckFirst', @UniqueRows = 100000;
EXEC dbo.InsertNumber_Wrapper @Test = 'CheckFirst', @UniqueRows = 66000;
EXEC dbo.InsertNumber_Wrapper @Test = 'CheckFirst', @UniqueRows = 33000;
EXEC dbo.InsertNumber_Wrapper @Test = 'CheckFirst', @UniqueRows = 0;
EXEC dbo.InsertNumber_Wrapper @Test = 'JustInsert', @UniqueRows = 100000;
EXEC dbo.InsertNumber_Wrapper @Test = 'JustInsert', @UniqueRows = 66000;
EXEC dbo.InsertNumber_Wrapper @Test = 'JustInsert', @UniqueRows = 33000;
EXEC dbo.InsertNumber_Wrapper @Test = 'JustInsert', @UniqueRows = 0;
On my system, this took about four minutes to run. I ran the test 3 times to smooth out any anomalies. We can now look at the log table and see how long each test took, on average:
;WITH s AS
(
SELECT Test, Step, UniqueRows, dt, rn = ROW_NUMBER() OVER
(PARTITION BY Test, UniqueRows ORDER BY dt)
FROM InsertLog
),
x AS
(
SELECT s.Test, s.UniqueRows,
[Duration] = DATEDIFF(MILLISECOND, s.dt, e.dt)
FROM s INNER JOIN s AS e
ON s.Test = e.Test
AND s.UniqueRows = e.UniqueRows
AND s.rn = e.rn - 1
AND s.Step = 1
AND e.Step = 2
)
SELECT [Test], UniqueRows, [Avg] = AVG([Duration]*1.0)
FROM x
GROUP BY [Test], UniqueRows
ORDER BY UniqueRows, [Test];
Results:
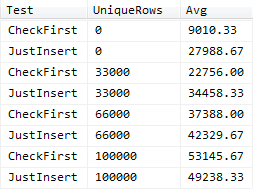
If we plot these on a graph, we can see that checking first is significantly better for our throughput performance in all but one case (at least in terms of duration; we didn't actively measure I/O or CPU utilization in order to achieve these speeds):
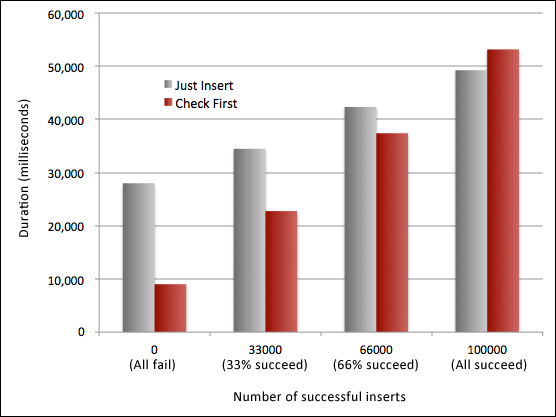
In the case where all insert attempts fail, we average over 11 inserts per MS if we check for the violations first, but only 3.5 inserts per millisecond. As the number of successful inserts increases, we see that our write times increase faster for successful inserts than the time spent dealing with failures. For the case where 33% of the insert attempts are successful, the average drops to 4.4 inserts per millisecond when we check first compared to 2.9 inserts per millisecond if we catch the error. At 66% success rate, they become very close - 2.7 inserts per millisecond when we check, and 2.4 inserts per millisecond when we don't check. Only when we get to 100% success rate (and I imagine it is somewhere in the 90% range), we see the scales tip, and finally preventing the exception costs more (1.9 inserts per millisecond) than just letting the system handle it (2.0 inserts per millisecond).
Conclusion
I've shown that while checking for errors can hamper throughput in cases where you expect a very low number of constraint violations, the impact can be quite dramatic as the failure rate goes up.I've obviously run a very isolated test here, and have used a lot of constants that should be variable in your own tests, including adjusting the isolation level, not using explicit transactions, playing with the various data types and constraints in your system, and dealing with concurrency. You should really stress test your application (on your hardware, with your schema, data and usage patterns) and specifically its error handling mechanisms in a worst case scenario in terms of failure rate. In some cases it might make sense to perform some additional checking before allowing a constraint to be violated, as the above tests should demonstrate; however, this isn't necessarily true in all cases.
Next Steps
- Review your current error handling techniques.
- Determine if you may be suffering from costly exceptions that could be avoided.
- Review the following tips and other resources:






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
