By: Rajendra Gupta | Comments (20) | Related: 1 | 2 | 3 | 4 | > Functions System
Problem
SQL Server 2012 introduces new analytical functions FIRST_VALUE and LAST_VALUE. These new functions allow you to get the same value for the first row and the last row for all records in a result set. In this tip we will explore these functions and how to use them.
Solution
SQL Server 2012 introduces two new analytical functions FIRST_VALUE and LAST_VALUE.
- FIRST_VALUE returns the first value in an ordered set of values and
- LAST_VALUE returns the last value in an ordered set of values
The syntax for these functions are:
FIRST_VALUE \LAST_VALUE ( [scalar_expression )
OVER ( [ partition_by_clause ] order_by_clause rows_range_clause )
Let me explain this using an example.
The following script creates a test table and some test data.
CREATE DATABASE [TestDB]
--Create testable to hold some data
CREATE TABLE [dbo].[Test_table](
[id] [int] IDENTITY(1,1) NOT NULL,
[Department] [nchar](10) NOT NULL,
[Code] [int] NOT NULL,
CONSTRAINT [PK_Test_table] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
--Insert some test data
insert into Test_table values('A',111)
insert into Test_table values('B',29)
insert into Test_table values('C',258)
insert into Test_table values('D',333)
insert into Test_table values('E',15)
insert into Test_table values('F',449)
insert into Test_table values('G',419)
insert into Test_table values('H',555)
insert into Test_table values('I',524)
insert into Test_table values('J',698)
insert into Test_table values('K',715)
insert into Test_table values('L',799)
insert into Test_table values('M',139)
insert into Test_table values('N',219)
insert into Test_table values('O',869)
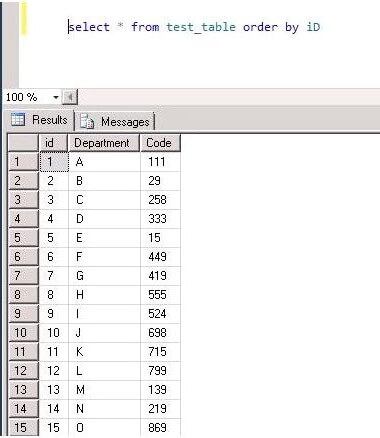
So our table data will look like:
Now the query for FIRST_VALUE and LAST_VALUE will be:
SELECT id,department,code, FIRST_VALUE(code) OVER (ORDER BY code) FstValue, LAST_VALUE(code) OVER (ORDER BY code) LstValue FROM test_table
Here are the results:
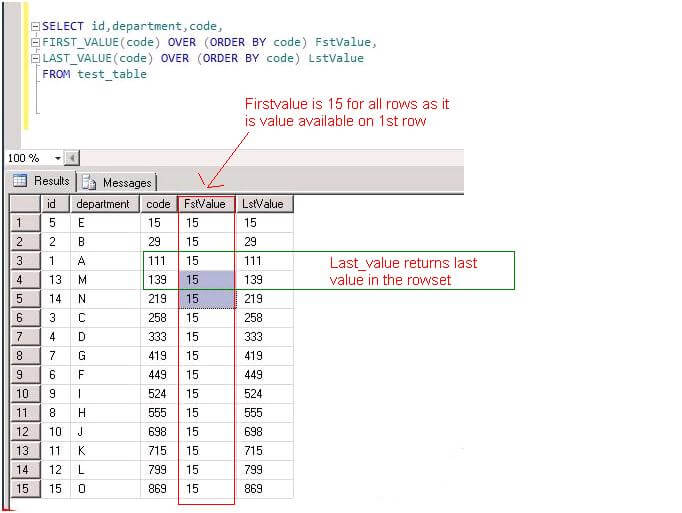
In the above example FIRST_VALUE is the same and equal to the value in the first row (i.e. 15) for the entire result set. While the LAST_VALUE changes for each record and is equal to the last value that was pulled (i.e. current value in the result set).
Get Same Last Value for All Records
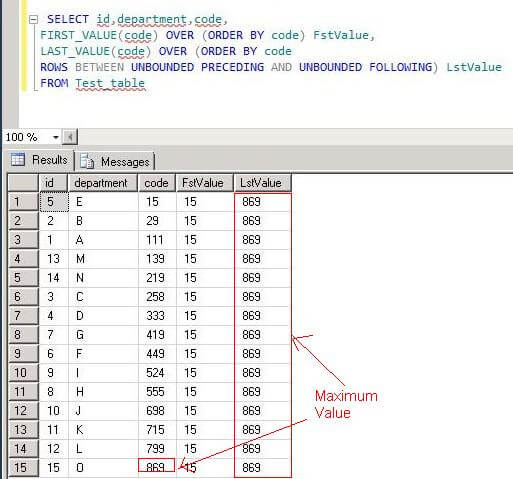
If we want the Last Value to remain the same for all rows in the result set we need to use ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING with the LAST_VALUE function as shown below.
SELECT id,department,code, FIRST_VALUE(code) OVER (ORDER BY code) FstValue, LAST_VALUE(code) OVER (ORDER BY code ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) LstValue FROM test_table
Here are the results:
Getting Different First And Last Values By Groups
Now let's use these functions with the PARTITION BY clause. The partition by clause divides the result set produced by the FROM clause into partitions to which the function is applied. If not specified, the function treats all rows of the query result set as a single group, as we saw in last example. To test this we will insert some more test data where values for department will be duplicated.
insert into Test_table values( 'A',51) insert into Test_table values( 'A',111) insert into Test_table values( 'A',169) insert into Test_table values( 'A',514) insert into Test_table values( 'B',5331) insert into Test_table values( 'B',12211) insert into Test_table values( 'B',101) insert into Test_table values( 'B',135)
Now the query will look like this:
SELECT id,department,code, FIRST_VALUE(code) OVER (PARTITION BY department ORDER BY code) FstValue, LAST_VALUE(code) OVER (PARTITION BY department ORDER BY code) LstValue FROM test_table
So the output would be:
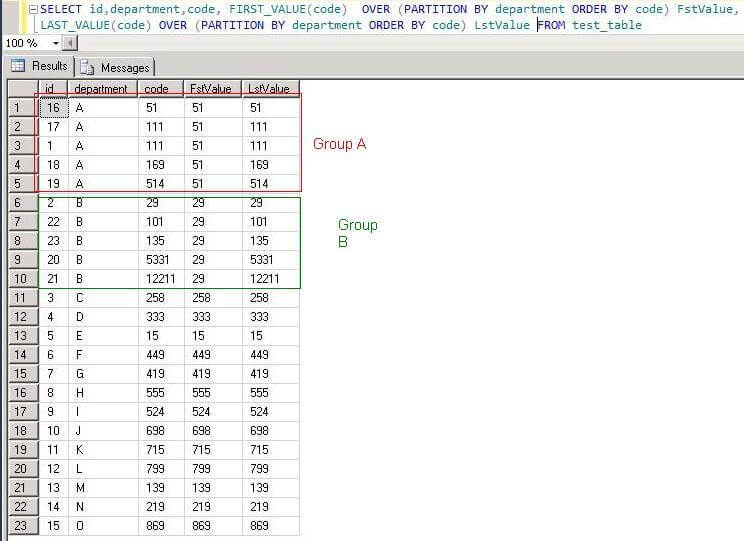
Now the result set is divided into partitions based on the department, so the FIRST_VALUE is different but the same for each partition, while the LAST_VALUE changes for the last row in that partition.
Next Steps
- Review more tips on functions






About the author
 Rajendra Gupta is a Consultant DBA with 14+ years of extensive experience in database administration including large critical OLAP, OLTP, Reporting and SharePoint databases.
Rajendra Gupta is a Consultant DBA with 14+ years of extensive experience in database administration including large critical OLAP, OLTP, Reporting and SharePoint databases.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
