By: Armando Prato | Comments (10) | Related: > Data Types
Problem
I am executing a simple query/stored procedure from my application against a large table and it's taking a long time to execute. The column I'm using in my WHERE clause is indexed and it's very selective. The search column is not wrapped in a function so that's not the issue. It's like the optimizer doesn't even know an index exists! What could be going wrong?
Solution
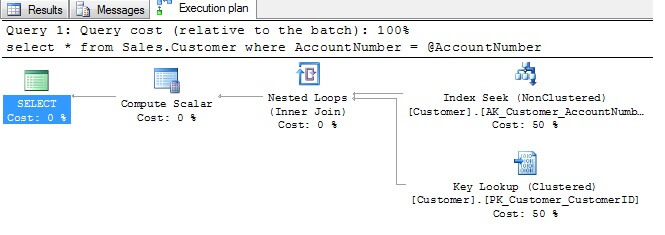
A subtlety that can cause an issue like this to arise occurs when the data type of a query search parameter you've defined in your application or declared in your stored procedure doesn't match the same data type of the column that will be searched by the query. In these cases, SQL Server will implicitly convert the data type of either the search column or the search parameter by converting the one with the lower precedence data type to the data type of higher precedence. If the search column becomes the victim of conversion, the result can be a scan (as opposed to a seek) to satisfy the query request. Let's look at a couple of examples. In this first example (the data is from AdventureWorks), we will attempt to query the Sales.Customer table by looking up a customer by their AccountNumber. The AccountNumber is varchar(10) and has a unique index assigned to it. Running a query and examining the resulting execution plan reveals an index seek using the index available on the AccountNumber as we'd expect:
create procedure dbo.PrecedenceTest ( @AccountNumber varchar(10) ) as begin set nocount on select * from Sales.Customer where AccountNumber = @AccountNumber end go exec dbo.PrecedenceTest 'AW00030113' go
Let's make a small change to the @AccountNumber parameter; we'll change it from varchar to nvarchar, re-execute the procedure, and re-examine the execution plan.
alter procedure dbo.PrecedenceTest ( @AccountNumber nvarchar(10) ) as begin set nocount on select * from Sales.Customer where AccountNumber = @AccountNumber end go exec dbo.PrecedenceTest 'AW00030113' go
The resulting plan shows that a scan was chosen by the optimizer using the index on TerritoryID:
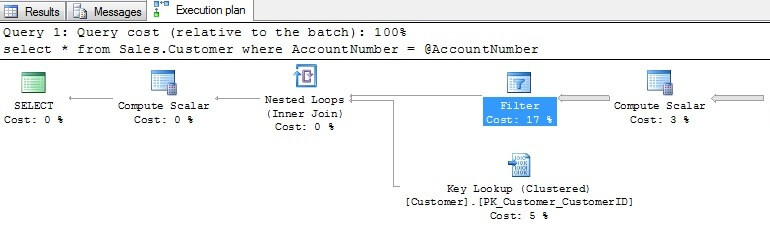
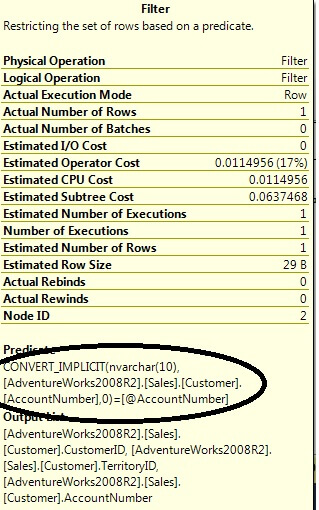
Examining the Filter operator, we can see the AccountNumber column was implicitly converted to match the data type of the search parameter since it's data type (varchar) has a lower precedence than the data type of the search column (nvarchar) which nullifies the index.
Now let's examine conversion occurring in reverse where the data type of the search parameter has lower precedence than the data type of the search column. In this case, the LastName column of the Person.Person table is nvarchar and an available index exists for it. The @LastName parameter of the stored procedure will be declared as varchar:
alter procedure dbo.PrecedenceTest( @LastName varchar(50) ) as begin set nocount on select * from Person.Person where LastName = @LastName end go exec dbo.PrecedenceTest 'Tamburello' go
The resulting plan shows that an index seek using the available index was chosen by the optimizer:
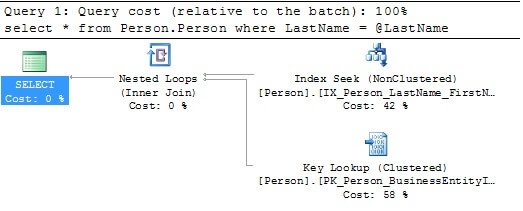
Drilling in further, we see that conversion occurred on the passed in search parameter as opposed to the search column since the data type for LastName is nvarchar which has a higher precedence than the data type of the search parameter which is defined as varchar:
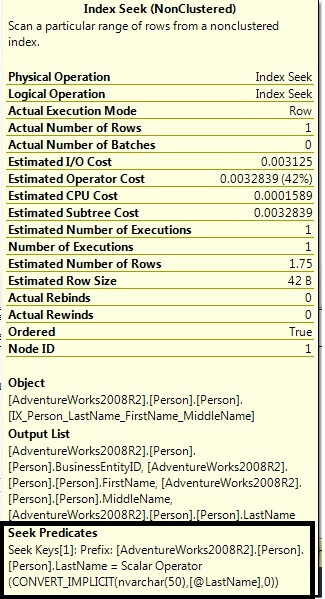
Since the indexed column was not affected by conversion, the optimizer was free to choose an optimal plan.
Whether you're defining query parameters in your application logic or declaring within them within stored procedures, prevent potential index scanning and other conversion issues by making sure the data types of all query parameters match the data types of the columns of your query.
Next Steps
- Familiarize yourself with the T-SQL Data Type Precedence Chart
- If you're unfamiliar with reading graphical plans, read this tip






About the author
 Armando Prato has close to 30 years of industry experience and has been working with SQL Server since version 6.5.
Armando Prato has close to 30 years of industry experience and has been working with SQL Server since version 6.5.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
