By: Arshad Ali | Comments (23) | Related: More > Integration Services Excel
Problem
Recently while working on a project to import data from an Excel worksheet using SSIS, I realized that sometimes the SSIS Package failed even though when there were no changes in the structure/schema of the Excel worksheet. I investigated it and I noticed that the SSIS Package succeeded for some set of files, but for others it failed. I found that the structure/schema of the worksheet from both these sets of Excel files were the same, the data was the only difference. How come just changing the data can make an SSIS Package fail? What actually causes this failure? What can we do to fix it? Check out this tip to learn more.
Solution
You must be wondering why the changes in the data can cause the SSIS Package to fail. Before I can talk about this issue in detail, first let me demonstrate this issue with an example. This example should demonstrate the actual failure and solution for this problem. As you can see in the image below, I have 18 records in the Excel worksheet, when I ran my SSIS Package to load the data from this worksheet, it worked fine.
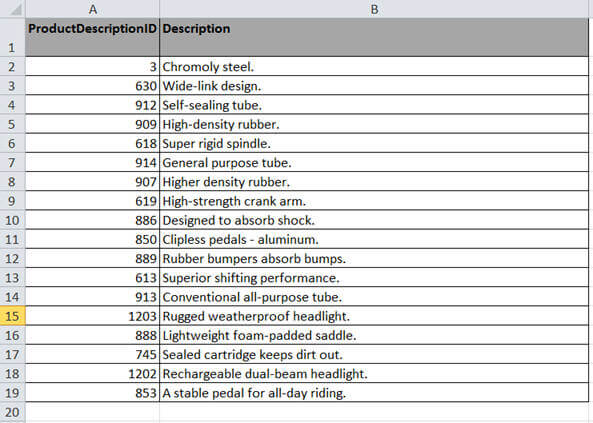
In the next image, I made some changes to row number 7. The description for ProductDescriptionId 907 is much larger than the previous data load. When I ran my SSIS package again to load the data from this worksheet, it worked fine as well.
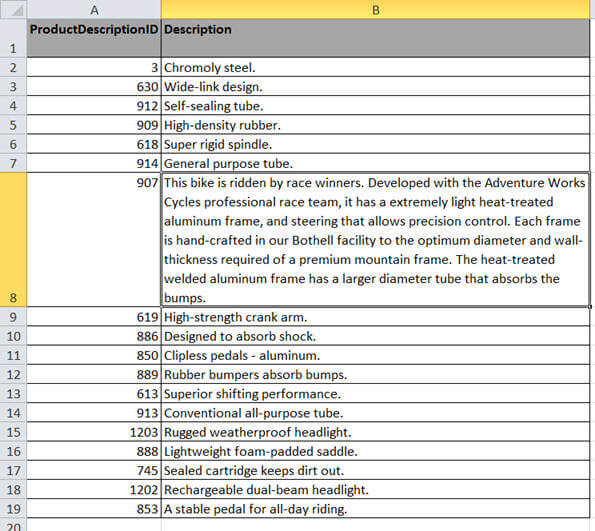
In the next image, I reverted the previous change and made some changes to the row number 14. The description for ProductDescriptionId 1203 is much larger than the previous data load. When I ran my SSIS package again to load the data from this worksheet, it failed with the following exception:
[Excel Source [1]] Error: There was an error with output column "Description" (18) on output "Excel Source Output" (9). The column status returned was: "Text was truncated or one or more characters had no match in the target code page.".
[Excel Source [1]] Error: The "output column "Description" (18)" failed because truncation occurred, and the truncation row disposition on "output column "Description" (18)" specifies failure on truncation. A truncation error occurred on the specified object of the specified component.
[SSIS.Pipeline] Error: SSIS Error Code DTS_E_PRIMEOUTPUTFAILED. The PrimeOutput method on component "Excel Source" (1) returned error code 0xC020902A. The component returned a failure code when the pipeline engine called PrimeOutput(). The meaning of the failure code is defined by the component, but the error is fatal and the pipeline stopped executing. There may be error messages posted before this with more information about the failure.
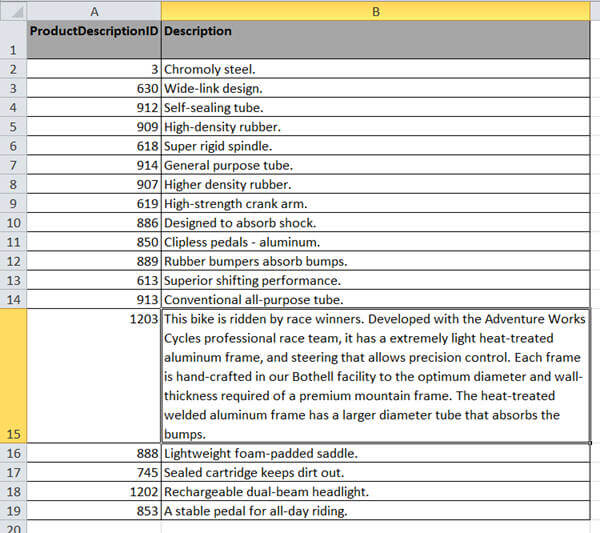
What caused the above SSIS package to fail?
SSIS Excel Connection Manager determines the data type of each column of the worksheet on the basis of the data of that particular column from the first 8 rows. This is the default behavior and the SSIS connection manager uses a value in the registry to determine the number of rows for the data type determination. Before I can explain more about the registry key and it's setting, let's see if we can do anything in the SSIS package to prevent this issue.
In your SSIS Package, right click on the Excel source in the data flow task and click on "Advance Editor for Excel Source". Next change the data type and length of the column from its default value. For example, in my case I have a "Description" column which has text data and the length is up to 500 characters. I have put max length for this column as 1000. Now click on "OK" button.
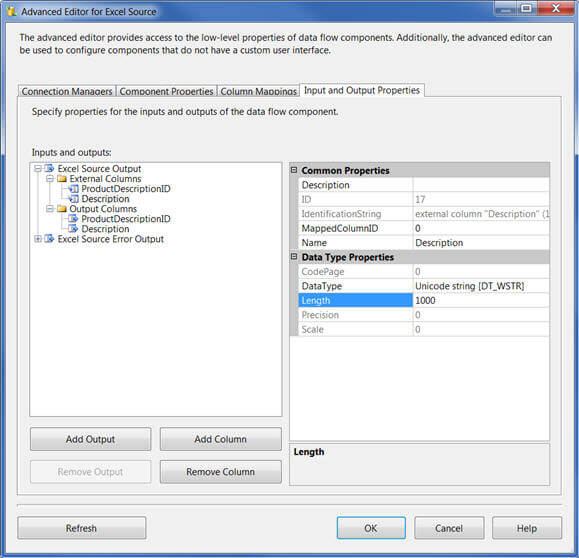
But what is this, the validation of the Excel Source failed itself as you can see below:

When you double click on the Excel Source task, it will inform that the component is not in a valid state and asks for your confirmation to fix this issue. When you click on the "Yes" button it will reset the data type and length of the column to what it was earlier, before we made the changes as above.
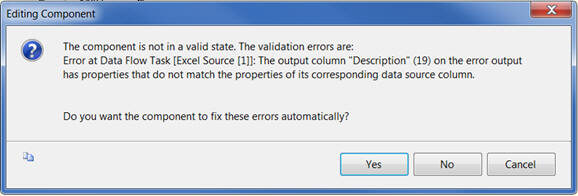
Now to summarize the whole thing : SSIS Excel Connection manager determines the data type and length of columns from the worksheet on the basis of the first eight rows of data. Even though we can change the data type and length from the Advance Editor for Excel Source, it will not be valid and the information will be reset by SSIS Excel Connection manager automatically using the same determination process.
Fixing the problem now in the registry
So as I said before, the number of rows to consider when determining the data type and length is determined by a registry key called TypeGuessRows by the SSIS Excel Connection Manager. By default its value is 8 and hence 8 rows are considered when determining the data type and length.
Now coming back to the solution, these are some of the options to address this problem:
- Configure the source system to provide your Excel file in which data is sorted on the basis of the length of the data in each column so that largest value of each column appears in the first row and alphanumeric data appears before numeric data.
- Configure the source system to provide a dummy record in your Excel file as first row with desired data type and size; then after data import you can remove/delete that dummy record from the database.
- Configure the source system to provide you a csv file instead of Excel file because with a csv file you have more control to determine data type and length of a column.
- Changing the TypeGuessRows registry key to 0 from its default value of 8. This will make the Excel connection manager consider all the rows when determining data type and length of each column.
Unfortunately, the first three options do not apply in my scenario as I do not have control on the source system providing data in worksheet. With this being said, I made the change in the TypeGuessRows registry key and updated its value from 8 to 0. After making this change, my same package worked like a charm for the same Excel worksheets for which it failed last time.
Registry Key Location - [HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Jet\4.0\Engines\Excel]
Please Note : On a 64-Bit Windows Server machine the registry key will be available here:
HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\Microsoft\Jet\4.0\Engines\Excel
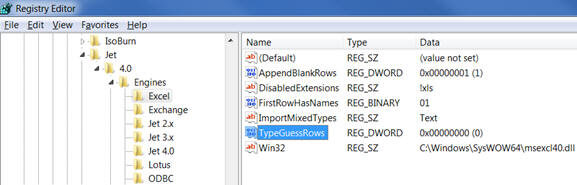
Please be cautious when changing the value for TypeGuessRows registry key and keep these points in mind:
- TypeGuessRows registry key is global setting and its not only going to impact your SSIS Package, but it will impact every place where it is referenced.
- Changing the value for TypeGuessRows registry key to 0 from its default value of 8, makes the Excel connection manager consider all the rows when determining the data type and length of each column and hence it could have a severe impact on the performance of your SSIS package if the number of rows in your Excel worksheet is large.
Now, as we saw, to fix this issue the easiest solution is to make change in the registry, but in many scenarios you will not have control in making this change as the servers are managed by the Operations Team or there might be several other applications running on the same machine. Even if you have control in changing this setting, this change might cause your SSIS Package to perform poorly, based on the amount of data you have in your Excel worksheet, and it may impact other systems as well when this registry key is being referenced. So now the question is, is there any way we can avoid making changes in the registry, but still solve the problem? Well, stay tuned for part 2 of this tip for a solution which does not require a registry change, but still solves the problem.
Next Steps
- Check out the sample project used in this tip.
- Review the Integration Services and Excel Tips.
- Review the Import Excel Unicode data with SQL Server Integration Services tip.
- Review the SQL Server Integration Services (SSIS) Tutorial.
- Review all my previous tips.






About the author
 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
