By: Derek Colley | Comments (13) | Related: > Replication
Problem
Replication in SQL Server simply refers to the process of copying data from one database to another. This movement of data is subject to a large number of options configured at the publisher, distributor and subscriber, but for all the complexity it is surprisingly simple to set up, providing the DBA has a solid understanding of the underlying principles.
Replication can be thought of in terms of the newspaper model - the publisher produces the newspapers and sends them to the distributor, who separates and sends them on to the subscribers (e.g. newsagents, shops) where the newspaper is 'accessed' by purchasers. Data in the replication model moves in a similar way, with some context-specific differences.
There are three main forms of replication; snapshot replication, which can be thought of as the best fit to the newspaper model - the whole newspaper is propagated each time. Merge replication incorporates changes at both the publisher and the subscriber; and transactional replication is an incremental flow of data from the publisher to the subscriber (much like a streaming news service, in this context). For further discussion on the intricacies of the different replication models, please consult Books Online.
However replication has many points of failure. This article will address two common causes of replication failure - when information in subscribers is not synchronized with information in the publication base tables and will show the reader where to look to find information on replication-specific issues. It will cover latency, stalled agents, failed jobs, replication-related tables, 'gotchas' and along the way will provide further links to replication as a data-propagation technology.
The focus of this article is transactional publication with pull subscriptions, so some information may vary depending on the model and topology you have chosen. Some familiarity with replication as a feature of SQL Server is assumed.
Solution
Suitability of Replication As A Solution
Why replicate? Replication has its uses - in a typical production-> pre-production-> development stack, for example, replication may be used to ensure live data is transferred to other servers to ensure accurate code tests by the developers; replication is also used in distributed architectures, where databases in read/write mode apply data to read-only subscribers and these read-only subscribers are used for reporting purposes. An architecture like this has several benefits, not least of which is reducing locking and blocking on the principal database and allowing sub-optimal code (i.e. such as that generated by SSRS and third-party reporting products) to run against accurate data without causing transaction processing issues.
Below is a very basic architectural example where replication could be used. As you can see, SALES_MASTER takes on the transactional load and replicates selected publication data to different databases located in different countries. For example, the REPORTS_JP database takes pub_2, which may contain articles dealing exclusively with sales in Japan - e.g. the (fictional) tables dbo.Sales_Japan, dbo.Sales_Far_East and dbo.New_Customers with a filter on customers with column Country = 'JP' may form valid and relevant articles in this context.
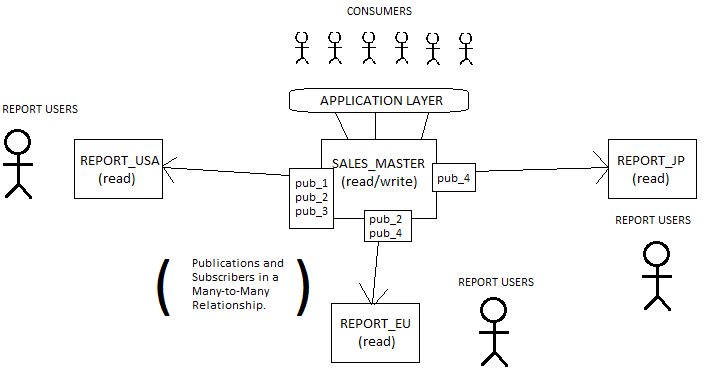
There are two types of replication subscriptions - push subscriptions, and pull subscriptions.
Push subscriptions are initiated from the publisher - that is to say, the log reader agent on the publisher scan the transaction log of the database with publications (containing articles) for replication, determines which transactions are to be replicated (log reader agent) then the distribution agent sends the transactions to the distributor, which forwards those transactions onto the subscription database, where they are applied. The subscriber does not actively query either the distribution database or the publisher; instead, it waits for inbound transactions.
Pull subscriptions are somewhat different. The subscribers, through the distribution agent, will periodically question the distribution database for unapplied transactions, gather the transaction and apply it to the subscription database. The distribution database will then be updated to show those transactions have been applied. The subscriber will not contact the publisher directly.
This article is not intended to give an in-depth discussion of replication - there is plenty of literature on this subject and some extensive articles in Books Online, which you can find in the links below. Instead, this article is intended to demonstrate some of the pitfalls of replication (not, in the author's humble opinion, the most stable feature of the SQL Server platform), identifying typical symptoms for problem diagnosis, and suggesting solutions for some replication-related problems. For the remainder of this article, the context will be transactional replication, since arguably this is the more common kind of replication model found in the wild.
Latency, Tracer Tokens and Replication Monitor
The most common, and indeed planned for, problem with replication is that of LATENCY. Latency in this context simply refers to the delay between publisher and subscriber (via distributor) and taken in isolation with no other symptoms can be perfectly normal. Latency can be caused by various factors, including geographical distance between nodes; network traffic or bandwidth constraints; transactional load on the publisher; and system resources. Less common causes, but by no means rare, are problems such as stalled agents, failed jobs and unexpected locking / other resource conflicts. Poor latency can be planned for and incorporated into an architectural plan - normally the acceptable latency will be a function of business requirements, for example in the model above, the natural latency between the UK and Japan may be 3 minutes. The Japanese management team may require data that is a maximum of 1 hour old. This will inform the architectural decision to allow for a variable latency of 20 minutes (to include contingency of an additional 17 minutes). Therefore the wise DBA can configure alerting that informs him (or her) of latency problems when latency exceeds this period as it is likely that latency exceeding this threshold is indicative of a more serious problem. Replication configuration allows the DBA to configure latency maximums, such that when the maximum is reached or exceeded, a new snapshot of each publication is required to be pushed to each subscriber to allow replication to continue.
Currently, Microsoft provides only one tool to monitor latency, and that is the ubiquitous 'Replication Monitor'. Opinions amongst DBAs on the use of this tool vary; unfortunately, while it has its uses, it is generally considered to be inaccurate, useful as a guideline only; and, more seriously, can occasionally affect the state of replication due to its intrusive methods of detection causing resource conflicts. Various examples of this have been documented by Microsoft Support and commented on in other online forums. However, as a tool it does have some uses, including drilldown dialogs that enable the DBA to see the number of unapplied transactions (and estimated time until synchronization); an 'at-a-glance' view of latency across all configured publications; last start times and statuses of various agents and jobs; and an organized view of the publisher, distributor and subscribers in one menu. For most DBAs, Replication Monitor is the first port of call when tackling a replication issue.
You can reach Replication Monitor by right-clicking on the 'Replication' subtree in Object Explorer and clicking on 'Launch Replication Monitor'.
Drill down using the menu on the left and the various tabs and options on the right to view the information you need.
Note: It is quite possible to measure latency yourself using T-SQL and a knowledge of tokenization. By inserting 'tokens' into the replication process (think putting a floating log into a fast-flowing river and measuring the time taken to flow between two predefined points), the DBA can work out the delay between one part of the replication process and another. Automatically measuring these statistics allows the DBA to create procedures that will monitor the latency and alert automatically when problems are detected. Tracer tokens are both inserted and measured at the publisher, and the procedure is straightforward, using just 4 different stored procedures:
- sp_posttracertoken -- posts a tracer token into a replication flow
- sp_helptracertokens -- returns a list of all active posted tracer tokens
- sp_helptracertokenhistory -- returns latency information given a tracer token ID and publication as parameters
- sp_deletetracertokenhistory -- deletes a tracer token given a tracer token ID and publication as parameters
You can find further information including step-by-step instructions to insert tracer tokens from Microsoft here -> http://msdn.microsoft.com/en-us/library/ms151178(v=sql.100).aspx
When latency exceeds the thresholds that you (as the DBA) have defined as normal, there are two different paths to choose for diagnosis. Either the latency is due to factors beyond your control (i.e. network outage, hardware failure) or the latency is indicative of a more serious database-related problem.
Stalled Agents and Jobs, and Finding Further Diagnostic Information
Often indicated by increased latency, it is not unusual for the agent processes governing replication to stall, and this can happen for different reasons. For example, one cause in this author's recent experience was a temporarily-high network load which caused a timeout to occur when the replication account attempted to connect to the distributor from the publisher. This caused the distribution agent at the distributor to stall, and consequently the subscription agents relying on a particular publication also stalled (since we were using a pull subscription model). This non-movement of data increased latency for the affected publications. Consequent successful attempts by the publisher to connect to the distributor were successful (likewise subscriber to distributor) but these were 'queued' behind an erroneous and entirely misleading error message that the 'initial snapshot is not yet available'. This particular situation was fixed by restarting the subscription agents and restarting the distribution agent (in particular the clean-up job). This caused a temporarily high load as replication caught up with the queued transactions and soon replication was back in synchronization. Post-event root cause analysis highlighted how the replication setup had fallen (like a set of dominoes) at the slightest hint of instability at one end of the process.
Depending on the situation you face, you may wish to restart the agents, or reinitialize the publication. Reinitialization (by using either an existing or new snapshot) may be appropriate when latency indications show a long synchronization time or when you have suspicions that an agent may be incorrectly configured (i.e. relying on a Windows account on which the permissions have recently changed) and your business priority is data resynchronization rather than addressing the root cause. It is important to note that preparation of a snapshot will normally cause exclusive table locks to be taken out on the tables in the defined publications, which can cause connection timeouts or long query execution times (propagated through the application layer as timeout errors and manifesting as increased helpdesk calls) which may impact the business. Where possible, an existing snapshot should be used (dependent on age) or reinitialization should take place during an out-of-hours or 'slow' period.
You can find the history of the replication jobs by drilling down through SQL Server Agent and examining Job History particularly on the distributor. By looking at what replication jobs have started (and indeed which are stalled) you can identify which agents to restart or which publications to reinitialize. You can view error messages relating to stalled or errored replication processes by checking the replication-specific tables on the distributor. Tables of particular interest include msrepl_errors, mspublications, mssubscriptions, msarticles, msrepl_transactions and msdistribution_history. By joining on the columns of these tables, you can easily find information on errors relating to e.g. a particular publication. A partial list of tables available in the Distribution database can be found here -> http://sqlserverpedia.com/wiki/Distribution_Databases
Here's one such query you can run which uses some of these tables. The following query will pull all information about distribution agents that are actively distributing transactions (in progress) and will provide useful information such as the delivery rate (txs/sec). I've added WITH (NOLOCK) from habit when dealing with system tables but it's not strictly necessary in this case since this is a history table. Feel free to amend and add/remove columns or filters:
SELECT da.name, da.publisher_db, da.subscription_type,
dh.runstatus, dh.delivery_rate, dh.start_time, dh.duration
FROM dbo.MSdistribution_history dh WITH (NOLOCK)
INNER JOIN dbo.msdistribution_agents da WITH (NOLOCK)
ON dh.agent_id = da.id
WHERE dh.runstatus = 3 -- 3 means 'in progress', table explanation here:
-- http://msdn.microsoft.com/en-us/library/ms179878.aspx
AND dh.start_time BETWEEN DATEADD(dd,-30,GETDATE()) AND GETDATE()
ORDER BY dh.start_time DESC
Taking Snapshots and Reinitializing Subscriptions
The difference between snapshotting data and initializing data is as follows (in the transactional model). A database snapshot (for purposes of replication) is a complete view of the schema and contents of all articles for a particular publication. Each publication has it's own snapshot. So, for example, here is the structure of a fictional publication.
-> dbo.general_sales (filter: WHERE sale_date BETWEEN '2012-01-01' AND '2012-03-31') (4328 rows)
-> dbo.q1_summary (102 rows)
-> dbo.products (filter: WHERE product_added <= '2012-03-31') (332 rows)
(total: 4762 rows)
The contents of each row in this publication will be included in the snapshot together with metadata information on the publisher's database. Database snapshots, on initialization, are created as sparse files containing the database pages that contain the articles defined for the publication. As transactions are completed on the base tables, the snapshots are updated to reflect the new information and the size of the snapshot grows. So in this context, re-snapshotting simply refers to the process of re-collecting all the data into an initial snapshot. As warned earlier, this process can be resource-intensive and it is recommended this is completed during a quiet period (the author speaks from experience!) Creating a snapshot is easy - use either sp_addpublicationsnapshot or use SSMS to drill into the subscriber, 'Reinitialize' and click on the option to 'Create a new snapshot'.
Initializing a publication is quite different. The initialization process will effectively rewrite the articles at the subscribers, overwriting the contents with the snapshot contents. As this process is effectively a series of INSERT/UPDATE/DELETE statements, some locking will occur but the overhead (locks/blocks) is minimal since the reinitialization will not lock tables simultaneously nor for an extended period of time. Reinitialization is necessary after a defined threshold period for latency/non-connection has been exceeded. Again, right-click on the subscription and hit 'Reinitialize'.
Some Notes
Some miscellaneous points and summaries which may help you on the road to replication diagnosis:
- Microsoft's Best Practices document for replication can assist you when planning/diagnosing -> http://msdn.microsoft.com/en-us/library/ms151818(v=sql.100).aspx
- Replication errors sometimes, but do not always, appear in the error logs.
- Replication Monitor can affect replication and cause erroneous errors, particularly in pre-2008 versions -> http://support.microsoft.com/kb/967192
- Latency is often indicative of an underlying problem.
- Become familiar with replication-related tables - those in Distribution, and those in MSDB on the publisher.
- In push subscriptions, the distribution agent is on the publisher. In pull subscriptions, it is on the subscriber.
- Snapshotting data has an adverse impact on data availability of the base tables.
- Replication is immediate continuous data propagation, where log-shipping is replication with differences - the 'burst' model of data transmission, the lack of a distributor, and the ability to insert artificial delays (e.g. to prevent immediate propagation of accidental errors - UPDATEs without WHEREs etc.) Choose the best strategy for your needs.
Next Steps
- I hope this article has been helpful and will encourage you to explore replication in greater detail. If you find inaccuracies or have any comments or questions, please leave a comment below and I'll get back to you as soon as possible.






About the author
 Derek Colley is a UK-based DBA and BI Developer with more than a decade of experience working with SQL Server, Oracle and MySQL.
Derek Colley is a UK-based DBA and BI Developer with more than a decade of experience working with SQL Server, Oracle and MySQL.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
