By: Daniel Farina | Comments (1) | Related: > In Memory OLTP
Problem
You have migrated some tables to In-Memory OLTP, but instead of getting better performance on table operations, everything seems to be the same or even worse. What is going on? In this tip I will guide you to the answer for that question.
Solution
In my previous tips about Hekaton, I wrote about the advantages of In-Memory OLTP, but as happens with any database technology it requires some adjustments to take full advantages of new features. The more robust a product is the more adjustments you can make. I have told you about statistics and the advantages of hash indexes over range indexes for equality searches and now we are ready to go a step further. I am referring to tuning of hash indexes, more specifically, setting the right value for the number of buckets (BUCKET_COUNT).
What does BUCKET_COUNT mean and what is its importance?
The value of BUCKET_COUNT represents the number of buckets a Hash index has. We can think of a bucket as an index position in which a row address is stored. Since I explained what a bucket is in my previous tip Understanding SQL Server Memory-Optimized Tables Hash Indexes, I won't go into further details on this matter.
For a Hash index, ideally distinct row keys will match distinct buckets and equal row key hashes will match to the same bucket.
But this does not always happen and there are cases in which two different keys hash to the same bucket. This is called a "Hash collision" and the way Hekaton solves this is by chaining the existing row with the new or updated row with index pointers. Also row chaining happens when two keys are the same because they will always have the same hash value.
For the purposes of this article I will assume that index keys are unique keys because equal keys will match the same buckets, so with equal keys chaining is unavoidable.
So considering the above, the idea of setting the BUCKET_COUNT value equal to the number of distinct keys is not entirely wrong. But there are other things to take into consideration.
Even though the hash function used in SQL Server 2014 is a very good one, it is not perfect. So hash collisions will happen and that means row chaining will happen.
Also, as Hekaton has an optimistic multi-version concurrency control, in order to keep track of a row's versions, the Engine chains the inserted row (remember that Hekaton handles updates as a delete followed by an insert) at the end of the bucket chain. Of course, there is a Garbage collector within the Engine that removes versions no longer needed to shorten the chain and to free system memory.
On the other hand, you can think of establishing the value for BUCKET_COUNT to the maximum admissible (which is 1,073,741,824) just in case, but that will lead to the following problems:
- Memory waste
- For a Hash index every bucket is 8 bytes in size, we can use the following formula to determine how much memory space an index will use: [Hash index size] = 8 * [actual bucket count] (Bytes)
- So if we set the BUCKET_COUNT to 1,073,741,824 then the index will use 8.589.934.592 bytes which
is 8GB. No matter how many rows the table has.
- Increased index and table scan times
- When performing a table or index scan Hekaton needs to look at each bucket of the Hash index.
How to check if BUCKET_COUNT is too low?
The first and easiest method to check if your index is low on buckets is to divide the value specified on BUCKET_COUNT by the number of distinct keys on the index. If the result has a value less than 1 then you have low buckets. You should aim for a value between 1.5 and 2.
The next query will return the next power of two of the number of distinct keys in the table. In most cases it should be enough.
SELECT
POWER(
2,
CEILING( LOG( COUNT( 0)) / LOG( 2)))
AS 'BUCKET_COUNT'
FROM
(SELECT DISTINCT <Index Columns>
FROM <Target Table>) T
Another way is to use the new Dynamic Management View (DMV) sys.dm_db_xtp_hash_index_stats. This DMV provides some useful statistics for hash indexes.
Here is a description of its columns.
|
Column name |
Type |
Description |
|---|---|---|
|
object_id |
INT |
The object ID of table. |
|
index_id |
INT |
The index ID. |
|
total_bucket_count |
BIGINT |
The total number of hash buckets in the index.( The value specified on BUCKET_COUNT during table index creation) |
|
empty_bucket_count |
BIGINT |
The number of empty buckets. |
|
avg_chain_length |
BIGINT |
The average length of the row chain. |
|
max_chain_length |
BIGINT |
The maximum length of the row chain. |
Use the following guidelines to interpret the values:
-
With the average and maximum chain length you can get a vague idea of the chain length dispersion and gives an idea on how many keys are hashed to the same bucket.
-
A fairly empty bucket count and a high average chain length means that the Hash index has many duplicate keys.
-
If the values of average and maximum chain length are high and the empty buckets are low then the index is low on buckets, so consider re-creating the table.
-
I want to emphasize that you don't have to look only at the value of empty_bucket_count to check if the index is low on buckets.
Remember that the chain length increases if there are transactions updating rows due to Hekaton's multiversion concurrency control until the garbage collector reorganizes the index pointers.
Sample
Now I will explain with examples how to determine if your indexes are low on buckets.
First we create our sample database.
CREATE DATABASE TestDB
ON PRIMARY
(NAME = TestDB_file1,
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\Data\TestDB_1.mdf',
SIZE = 100MB,
FILEGROWTH = 10%),
FILEGROUP TestDB_MemoryOptimized_filegroup CONTAINS MEMORY_OPTIMIZED_DATA
( NAME = TestDB_MemoryOptimized,
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\Data\TestDB_MemoryOptimized')
LOG ON
( NAME = TestDB_log_file1,
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\Data\TestDB_1.ldf',
SIZE = 100MB,
FILEGROWTH = 10%)
GO
Now we create a table whose index has four buckets.
USE TestDB
GO
IF OBJECT_ID('dbo.Customers','U') IS NOT NULL
DROP TABLE dbo.Customers
GO
CREATE TABLE dbo.Customers(
CustomerId INT NOT NULL,
CustomerCode NVARCHAR(10) NOT NULL,
CustomerName NVARCHAR(50) NOT NULL,
CustomerAddress NVARCHAR(50) NOT NULL,
ChkSum INT NOT NULL
PRIMARY KEY NONCLUSTERED HASH (customerid) WITH (BUCKET_COUNT = 4)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
With this script we load our table with 99999 rows for our tests.
USE TestDB
GO
DECLARE @i int = 1
WHILE @i < 100000
BEGIN
INSERT INTO dbo.customers
SELECT @i,
CONVERT(VARCHAR(10), GETDATE() ,13 ),
CONVERT(VARCHAR(12), GETDATE() , 103 ),
CONVERT(VARCHAR(12), GETDATE() , 103 ),
CHECKSUM(GETDATE() )
SET @i = @i +1
END
To check the statistics of our Hash index I will query the sys.dm_db_xtp_hash_index_stats DMV.
USE TestDB
GO
SELECT s.object_id ,
OBJECT_NAME(s.object_id) AS 'Table Name' ,
s.index_id ,
i.name ,
s.total_bucket_count ,
s.empty_bucket_count ,
s.avg_chain_length ,
s.max_chain_length
FROM sys.dm_db_xtp_hash_index_stats s
INNER JOIN sys.hash_indexes i
ON s.object_id = i.object_id
AND s.index_id = i.index_id
The next query is very simple but effective to show the performance impact of chaining on a hash index.
USE TestDB
GO
SELECT s.object_id ,
OBJECT_NAME(s.object_id) AS 'Table Name' ,
s.index_id ,
i.name ,
s.total_bucket_count ,
s.empty_bucket_count ,
s.avg_chain_length ,
s.max_chain_length
FROM sys.dm_db_xtp_hash_index_stats s
INNER JOIN sys.hash_indexes i
ON s.object_id = i.object_id
AND s.index_id = i.index_id
WHERE s.object_id = OBJECT_ID('dbo.Customers')
GO
BEGIN TRANSACTION
UPDATE dbo.Customers WITH (SNAPSHOT)
SET ChkSum = 0
WHERE CustomerId BETWEEN 1000 AND 3000
GO 5
SELECT s.object_id ,
OBJECT_NAME(s.object_id) AS 'Table Name' ,
s.index_id ,
i.name ,
s.total_bucket_count ,
s.empty_bucket_count ,
s.avg_chain_length ,
s.max_chain_length
FROM sys.dm_db_xtp_hash_index_stats s
INNER JOIN sys.hash_indexes i
ON s.object_id = i.object_id
AND s.index_id = i.index_id
WHERE s.object_id = OBJECT_ID('dbo.Customers')
GO
ROLLBACK TRANSACTION
The query looks innocent, but has some aspects to remark.
Remember from my previous tip that hash indexes aren't optimum for range searches. Also remember that Hekaton handles updates as a delete followed by an insert. And being that the query is within the context of a transaction and the multi-version nature of Hekaton's concurrency control, the outcome is that the updated rows will create new rows on the same chain bucket and the execution loop makes the query more stressful.
As you can see on the image below the query doesn't perform very well.
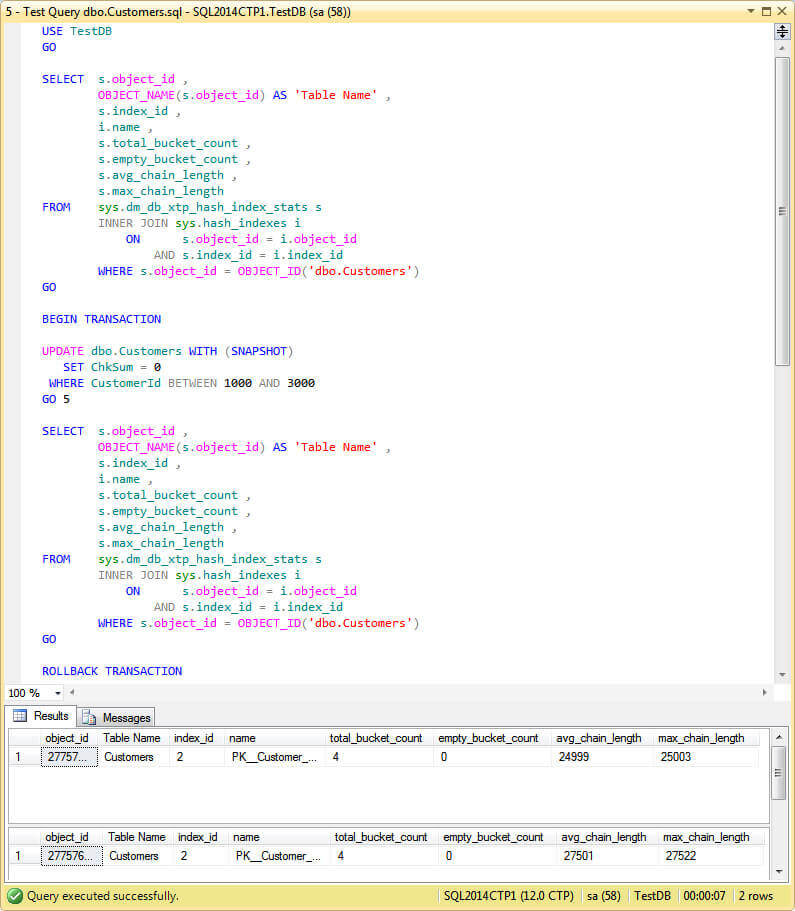
I decided to include in the script a query to sys.dm_db_xtp_hash_index_stats DMV so you can see the impact of the updates on the chain length. As you can see the maximum chain length increased from 25,003 to 27,522, a difference of 2,519.
We need to create a new table with a proper number of buckets on its Hash index.
The script below returns the value we should use on the BUCKET_COUNT of our new table index which is the next power of two of the number of distinct keys on the index.
USE TestDB GO SELECT
POWER(
2,
CEILING( LOG( COUNT( 0)) / LOG( 2)))
AS 'BUCKET_COUNT'
FROM
(SELECT DISTINCT CustomerId
FROM dbo.Customers) T
It is time to create a new table with the proper number of buckets for the Hash index.
USE TestDB
GO
IF OBJECT_ID('dbo.Customers_New','U') IS NOT NULL
DROP TABLE dbo.Customers_New
GO
CREATE TABLE dbo.Customers_New(
CustomerId INT NOT NULL,
CustomerCode NVARCHAR(10) NOT NULL,
CustomerName NVARCHAR(50) NOT NULL,
CustomerAddress NVARCHAR(50) NOT NULL,
ChkSum INT NOT NULL
PRIMARY KEY NONCLUSTERED HASH (CustomerId) WITH (BUCKET_COUNT = 131072)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
With the next script we copy the data from dbo.Customers table to dbo.Customers_New table.
USE TestDB
GO
INSERT INTO dbo.Customers_New (CustomerId,
CustomerCode,
CustomerName,
CustomerAddress,
ChkSum)
SELECT CustomerId,
CustomerCode,
CustomerName,
CustomerAddress,
ChkSum
FROM dbo.Customers
Now we execute the previous query again on our new table.
USE TestDB
GO
SELECT s.object_id ,
OBJECT_NAME(s.object_id) AS 'Table Name' ,
s.index_id ,
i.name ,
s.total_bucket_count ,
s.empty_bucket_count ,
s.avg_chain_length ,
s.max_chain_length
FROM sys.dm_db_xtp_hash_index_stats s
INNER JOIN sys.hash_indexes i
ON s.object_id = i.object_id
AND s.index_id = i.index_id
WHERE s.object_id = OBJECT_ID('dbo.Customers_New')
GO
BEGIN TRANSACTION
UPDATE dbo.Customers_New WITH (SNAPSHOT)
SET ChkSum = 0
WHERE CustomerId BETWEEN 1000 AND 3000
GO 5
SELECT s.object_id ,
OBJECT_NAME(s.object_id) AS 'Table Name' ,
s.index_id ,
i.name ,
s.total_bucket_count ,
s.empty_bucket_count ,
s.avg_chain_length ,
s.max_chain_length
FROM sys.dm_db_xtp_hash_index_stats s
INNER JOIN sys.hash_indexes i
ON s.object_id = i.object_id
AND s.index_id = i.index_id
WHERE s.object_id = OBJECT_ID('dbo.Customers_New')
ROLLBACK TRANSACTION
As we can see on the image below, the execution time has reduced remarkably.
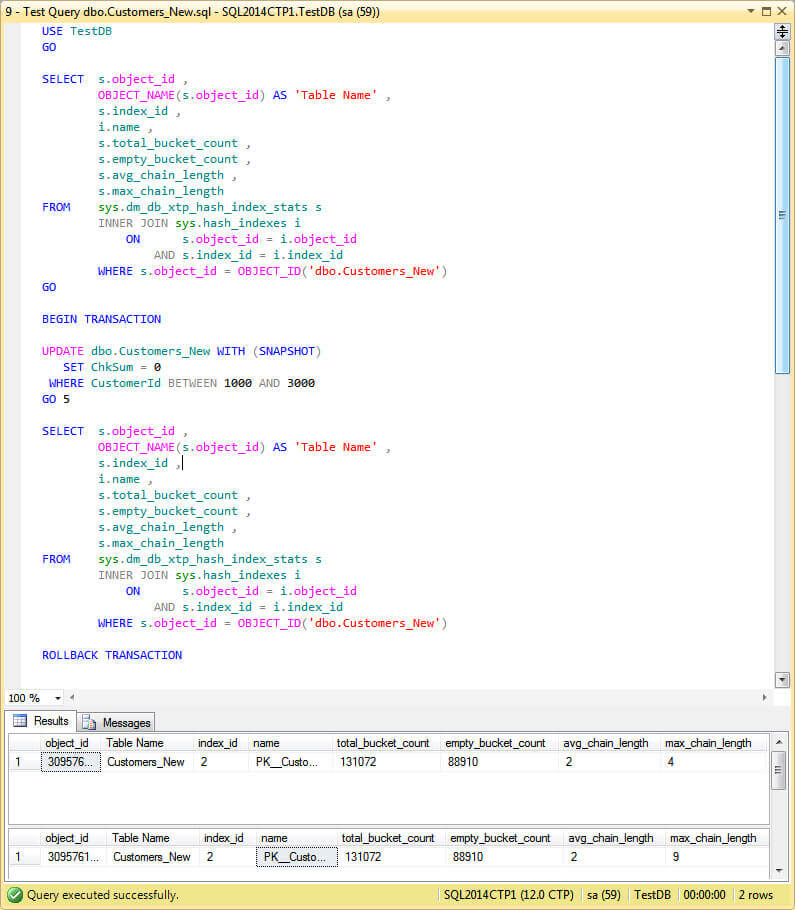
Also look at the values for max_chain_length. It increased from 4 to 9 which is a difference of 5, the numbers of execution on the loop.
Compare this value with the previous run. Remember that to get to the row to be updated the Engine follows the pointers of the chain until it reaches the row with the transaction timestamp. This is an explanation for the difference in query times.
References
- Hekaton: SQL Server's Memory-Optimized OLTP Engine, Diaconu C., Freedman
C., Ismert E, Larson P., Mittal P., Stonecipher R., Verma N., Zwilling M. (http://research.microsoft.com/pubs/193594/Hekaton%20-%20Sigmod2013%20final.pdf).
- Delaney K. SQL Server In-Memory OLTP Internals Overview for CTP2 (http://download.microsoft.com/download/F/5/0/F5096A71-3C31-4E9F-864E-A6D097A64805/SQL_Server_Hekaton_CTP1_White_Paper.pdf).
Next Steps
- If you still don't have a version of SQL Server 2014, download a trial version here.
- Take a look at my previous tip about migrating to Memory-Optimized Tables: Overcoming storage speed limitations with Memory-Optimized Tables for SQL Server.
- Read my tip about Understanding SQL Server Memory-Optimized Tables Hash Indexes.
- This is a good tip to start getting in touch with indexes: SQL Server Indexing Basics.
- Also this one would give you more insight: Understanding SQL Server Indexing.
- After those tips you are ready for this one: SQL Server Index Checklist.
- Check this out to learn about Snapshot Isolation in SQL Server 2005.
- Need to execute a TSQL batch multiple times as I done in this tip?: Executing a TSQL batch multiple times using GO.
- Read about Dynamic Management Views and Functions in SQL Server 2005.
- And also Dynamic Management Views and Functions in SQL Server 2008.
- Here you will find a deeper insight of Dynamic Management Views Dynamic Management Views and Functions Tips Category.
- Take a look at Indexing Tips Category.
- Also take a look at Performance Tuning Tips Category.






About the author
 Daniel Farina was born in Buenos Aires, Argentina. Self-educated, since childhood he showed a passion for learning.
Daniel Farina was born in Buenos Aires, Argentina. Self-educated, since childhood he showed a passion for learning.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
