By: Dattatrey Sindol | Comments (2) | Related: More > Big Data
Problem
I have read the previous tips on Introduction to Big Data and Architecture of Big Data and I would like to know more about Hadoop. What are the core components of the Big Data ecosystem? Check out this tip to learn more.
Solution
Before we look into the architecture of Hadoop, let us understand what Hadoop is and a brief history of Hadoop.
What is Hadoop?
Hadoop is an open source framework, from the Apache foundation, capable of processing large amounts of heterogeneous data sets in a distributed fashion across clusters of commodity computers and hardware using a simplified programming model. Hadoop provides a reliable shared storage and analysis system.
The Hadoop framework is based closely on the following principle:
In pioneer days they used oxen for heavy pulling, and when one ox couldn't budge a log, they didn't try to grow a larger ox. We shouldn't be trying for bigger computers, but for more systems of computers. ~Grace Hopper
History of Hadoop
Hadoop was created by Doug Cutting and Mike Cafarella. Hadoop has originated from an open source web search engine called "Apache Nutch", which is part of another Apache project called "Apache Lucene", which is a widely used open source text search library.
The name Hadoop is a made-up name and is not an acronym. According to Hadoop's creator Doug Cutting, the name came about as follows.
"The name my kid gave a stuffed yellow elephant. Short, relatively easy to spell and pronounce, meaningless, and not used elsewhere: those are my naming criteria. Kids are good at generating such. Googol is a kid's term."
Architecture of Hadoop
Below is a high-level architecture of multi-node Hadoop Cluster.
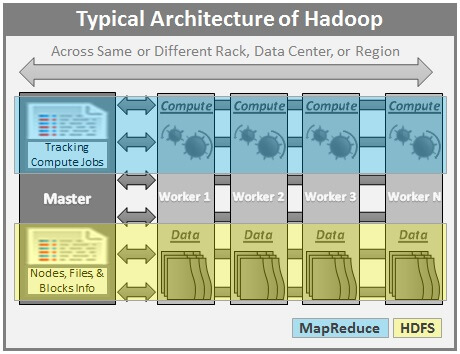
Here are few highlights of the Hadoop Architecture:
- Hadoop works in a master-worker / master-slave fashion.
- Hadoop has two core components: HDFS and MapReduce.
- HDFS (Hadoop Distributed File System) offers a highly reliable and distributed storage, and ensures reliability, even on a commodity hardware, by replicating the data across multiple nodes. Unlike a regular file system, when data is pushed to HDFS, it will automatically split into multiple blocks (configurable parameter) and stores/replicates the data across various datanodes. This ensures high availability and fault tolerance.
- MapReduce offers an analysis system which can perform complex computations on large datasets. This component is responsible for performing all the computations and works by breaking down a large complex computation into multiple tasks and assigns those to individual worker/slave nodes and takes care of coordination and consolidation of results.
- The master contains the Namenode and Job Tracker components.
- Namenode holds the information about all the other nodes in the Hadoop Cluster, files present in the cluster, constituent blocks of files and their locations in the cluster, and other information useful for the operation of the Hadoop Cluster.
- Job Tracker keeps track of the individual tasks/jobs assigned to each of the nodes and coordinates the exchange of information and results.
- Each Worker / Slave contains the Task Tracker and a Datanode components.
- Task Tracker is responsible for running the task / computation assigned to it.
- Datanode is responsible for holding the data.
- The computers present in the cluster can be present in any location and there is no dependency on the location of the physical server.
Characteristics of Hadoop
Here are the prominent characteristics of Hadoop:
- Hadoop provides a reliable shared storage (HDFS) and analysis system (MapReduce).
- Hadoop is highly scalable and unlike the relational databases, Hadoop scales linearly. Due to linear scale, a Hadoop Cluster can contain tens, hundreds, or even thousands of servers.
- Hadoop is very cost effective as it can work with commodity hardware and does not require expensive high-end hardware.
- Hadoop is highly flexible and can process both structured as well as unstructured data.
- Hadoop has built-in fault tolerance. Data is replicated across multiple nodes (replication factor is configurable) and if a node goes down, the required data can be read from another node which has the copy of that data. And it also ensures that the replication factor is maintained, even if a node goes down, by replicating the data to other available nodes.
- Hadoop works on the principle of write once and read multiple times.
- Hadoop is optimized for large and very large data sets. For instance, a small amount of data like 10 MB when fed to Hadoop, generally takes more time to process than traditional systems.
When to Use Hadoop (Hadoop Use Cases)
Hadoop can be used in various scenarios including some of the following:
- Analytics
- Search
- Data Retention
- Log file processing
- Analysis of Text, Image, Audio, & Video content
- Recommendation systems like in E-Commerce Websites
When Not to Use Hadoop
There are few scenarios in which Hadoop is not the right fit. Following are some of them:
- Low-latency or near real-time data access.
- If you have a large number of small files to be processed. This is due to the way Hadoop works. Namenode holds the file system metadata in memory and as the number of files increases, the amount of memory required to hold the metadata increases.
- Multiple writes scenario or scenarios requiring arbitrary writes or writes between the files.
For more information on Hadoop framework and the features of the latest Hadoop release, visit the Apache Website: http://hadoop.apache.org.
There are few other important projects in the Hadoop ecosystem and these projects help in operating/managing Hadoop, Interacting with Hadoop, Integrating Hadoop with other systems, and Hadoop Development. We will take a look at these items in the subsequent tips.
Next Steps
- Explore more about Big Data and Hadoop
- In the next and subsequent tips, we will see what is HDFS, MapReduce, and other aspects of Big Data world. So stay tuned!






About the author
 Dattatrey Sindol has 8+ years of experience working with SQL Server BI, Power BI, Microsoft Azure, Azure HDInsight and more.
Dattatrey Sindol has 8+ years of experience working with SQL Server BI, Power BI, Microsoft Azure, Azure HDInsight and more.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
