By: Dattatrey Sindol | Comments (1) | Related: More > Big Data
Problem
I have read the previous tips in the Big Data Basics series and I would like to know more about the Hadoop Distributed File System (HDFS). I would like to know about relevant information related to HDFS.
Solution
Before we take a look at the architecture of HDFS, let us first take a look at some of the key concepts.
Introduction
HDFS stands for Hadoop Distributed File System. HDFS is one of the core components of the Hadoop framework and is responsible for the storage aspect. Unlike the usual storage available on our computers, HDFS is a Distributed File System and parts of a single large file can be stored on different nodes across the cluster. HDFS is a distributed, reliable, and scalable file system.
Key Concepts
Here are some of the key concepts related to HDFS.
NameNode
HDFS works in a master-slave/master-worker fashion. All the metadata related to HDFS including the information about data nodes, files stored on HDFS, and Replication, etc. are stored and maintained on the NameNode. A NameNode serves as the master and there is only one NameNode per cluster.
DataNode
DataNode is the slave/worker node and holds the user data in the form of Data Blocks. There can be any number of DataNodes in a Hadoop Cluster.
Data Block
A Data Block can be considered as the standard unit of data/files stored on HDFS. Each incoming file is broken into 64 MB by default. Any file larger than 64 MB is broken down into 64 MB blocks and all the blocks which make up a particular file are of the same size (64 MB) except for the last block which might be less than 64 MB depending upon the size of the file.
Replication
Data blocks are replicated across different nodes in the cluster to ensure a high degree of fault tolerance. Replication enables the use of low cost commodity hardware for the storage of data. The number of replicas to be made/maintained is configurable at the cluster level as well as for each file. Based on the Replication Factor, each file (data block which forms each file) is replicated many times across different nodes in the cluster.
Rack Awareness
Data is replicated across different nodes in the cluster to ensure reliability/fault tolerance. Replication of data blocks is done based on the location of the data node, so as to ensure high degree of fault tolerance. For instance, one or two copies of data blocks are stored on the same rack, one copy is stored on a different rack within the same data center, one more block on a rack in a different data center, and so on.
HDFS Architecture
Below is a high-level architecture of HDFS.
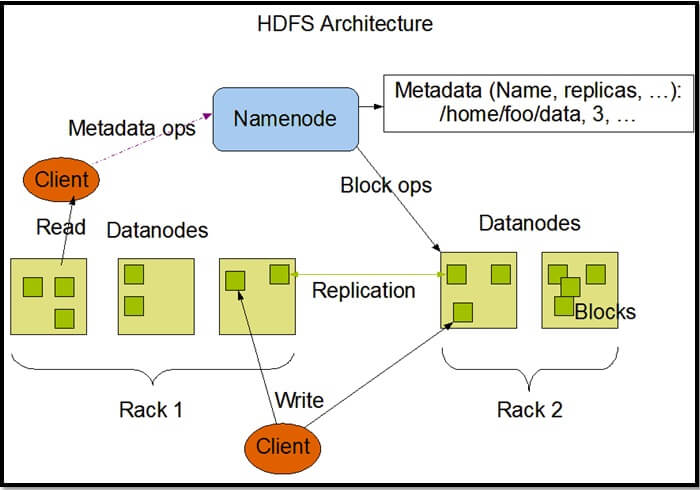
Image Source: http://hadoop.apache.org/docs/stable1/hdfs_design.html
Here are the highlights of this architecture.
Master-Slave/Master-Worker Architecture
HDFS works in a master-slave/master-worker fashion.
- NameNode servers as the master and each DataNode servers as a worker/slave.
- NameNode and each DataNode have built-in web servers.
- NameNode is the heart of HDFS and is responsible for various tasks including - it holds the file system namespace, controls access to file system by the clients, keeps track of the DataNodes, keeps track of replication factor and ensures that it is always maintained.
- User data is stored on the local file system of DataNodes. DataNode is not aware of the files to which the blocks stored on it belong to. As a result of this, if the NameNode goes down then the data in HDFS is non-usable as only the NameNode knows which blocks belong to which file, where each block located etc.
- NameNode can talk to all the live DataNodes and the live DataNodes can talk to each other.
- There is also a Secondary NameNode which comes in handy when the Primary NameNode goes down. Secondary NameNode can be brought up to bring the cluster online. This process of switching of nodes needs to be done manually and there is no automatic failover mechanism in place.
- NameNode receives heartbeat signals and a Block Report periodically from each of the DataNodes.
- Heartbeat signals from a DataNode indicates that the corresponding DataNode is alive and is working fine. If a heartbeat signal is not received from a DataNode then that DataNode is marked as dead and no further I/O requests are sent to that DataNode.
- Block Report from each DataNode contains a list of all the blocks that are stored on that DataNode.
- Heartbeat signals and Block Reports received from each DataNode help the NameNode to identify any potential loss of Blocks/Data and to replicate the Blocks to other active DataNodes in the event when one or more DataNodes holding the data blocks go down.
Data Replication
Data is replicated across different DataNodes to ensure a high degree of fault-tolerance.
- Replication Factor can be configured at a cluster level (Default is set to 3) and also at a file level.
- The need for data replication can arise in various scenarios like the Replication Factor is changed, a DataNode goes down, and when Data Blocks get corrupted, etc.
- When the replication factor is increased (At the cluster level or for a particular file), NameNode identifies the data nodes to which the data blocks need to be replicated and initiates the replication.
- When the replication factor is reduced (At the cluster level or for a particular file), NameNode identifies the data nodes from which the data blocks need to be deleted and initiates the deletion.
General
Here are few general highlights about HDFS.
- HDFS is implemented in Java and any computer which can run Java can host a NameNode/DataNode on it.
- Designed to be portable across all the major hardware and software platforms.
- Basic file operations include reading and writing of files, creation, deletion, and replication of files, etc.
- Provides necessary interfaces which enable the movement of computation to the data unlike in traditional data processing systems where the data moves to computation.
- HDFS provides a command line interface called "FS Shell" used to interact with HDFS.
When to Use HDFS (HDFS Use Cases)
There are many use cases for HDFS including the following:
- HDFS can be used for storing the Big Data sets for further processing.
- HDFS can be used for storing archive data since it is cheaper as HDFS allows storing the data on low cost commodity hardware while ensuring a high degree of fault-tolerance.
When Not to Use HDFS
There are certain scenarios in which HDFS may not be a good fit including the following:
- HDFS is not suitable for storing data related to applications requiring low latency data access.
- HDFS is not suitable for storing a large number of small files as the metadata for each file needs to be stored on the NameNode and is held in memory.
- HDFS is not suitable for scenarios requiring multiple/simultaneous writes to the same file.
References
- HDFS Architecture Guide: http://hadoop.apache.org/docs/stable1/hdfs_design.html
- For latest and up to date information, visit http://hadoop.apache.org
Next Steps
- Explore more about Big Data and Hadoop
- In the next and subsequent tips, we will look at the other aspects of Hadoop and the Big Data world. So stay tuned!






About the author
 Dattatrey Sindol has 8+ years of experience working with SQL Server BI, Power BI, Microsoft Azure, Azure HDInsight and more.
Dattatrey Sindol has 8+ years of experience working with SQL Server BI, Power BI, Microsoft Azure, Azure HDInsight and more.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
