By: Ben Snaidero | Comments (12) | Related: 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | > Query Optimization
Problem
Most DBAs, myself included, install SQL Server with the default server collation SQL_Latin1_General_CP1_CI_AS and all of our table columns get created using this default setting. This tip will look at the performance impacts of querying data with this setting as it compares to querying columns with the collation set to SQL_Latin1_General_CP1_CS_AS.
Solution
Table Setup
In order to carry out this small test we will create a simple 3 column table with an integer primary key column as well as two varchar columns. One of the varchar columns will have the collation set to SQL_Latin1_General_CP1_CI_AS and the other will have the collation set to SQL_Latin1_General_CP1_CS_AS. We'll also create an index on both columns. If we don't have an index on the column it would have to do a table scan in both cases and we would not see any difference in performance. Also, in the real world, any heavily queried column would be indexed so it makes sense to do the same for our performance test. Below is the query to create this table and indexes as well the T-SQL to load some random string data into the table.
CREATE TABLE [dbo].[test](
[col1] [bigint] NOT NULL,
[col2] [varchar](5) COLLATE SQL_Latin1_General_CP1_CI_AS,
[col3] [varchar](5) COLLATE SQL_Latin1_General_CP1_CS_AS,
PRIMARY KEY CLUSTERED ([col1] ASC) )
GO
CREATE NONCLUSTERED INDEX [IX_test_col2] ON [dbo].[test] ([col2] ASC)
CREATE NONCLUSTERED INDEX [IX_test_col3] ON [dbo].[test] ([col3] ASC)
GO
DECLARE @i INTEGER
DECLARE @x CHAR(1),@y CHAR(1),@z CHAR(1)
DECLARE @u INT,@v INT,@w INT
SELECT @i=1
WHILE @i < 500000
BEGIN
SELECT @u=ROUND(RAND()+1,0),@v=ROUND(RAND()+1,0),@w=ROUND(RAND()+1,0)
IF @u=1
SELECT @x=CHAR((RAND()*24)+65)
ELSE
SELECT @x=CHAR((RAND()*24)+97)
IF @v=1
SELECT @y=CHAR((RAND()*24)+65)
ELSE
SELECT @y=CHAR((RAND()*24)+97)
IF @w=1
SELECT @z=CHAR((RAND()*24)+65)
ELSE
SELECT @z=CHAR((RAND()*24)+97)
INSERT INTO [dbo].[test] VALUES (@i,@x+@y+@z,@x+@y+@z)
SELECT @i=@i+1
ENDTest Scenario 1 - Case insensitive query
Let's first take a look at the results when performing a case insensitive search of each of our columns. In this scenario, for the query on the column defined with SQL_Latin1_General_CP1_CI_AS we can simply use the equality operator in our WHERE clause. For the SQL_Latin1_General_CP1_CS_AS column we have two options, either we can use the T-SQL UPPER() function or specify the collation in the WHERE clause. Here are examples of each query.
select * from test where col2='npE' select * from test where UPPER(col3)='NPE' select * from test where col3 COLLATE SQL_Latin1_General_CP1_CI_AS='NPE'
Looking at the explain plan for each of these queries we can see that both the query with the function call as well as the one where we specify the collation need to perform an index scan to execute the query. The first query uses an index seek which will most likely execute much faster using fewer resources.
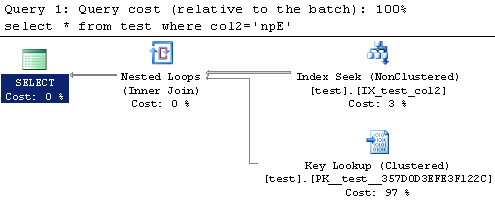


We can confirm the performance by looking at the SQL Trace results. From the chart below we can see that the first query outperforms the other two in every category.
| CPU | Reads | Writes | Duration | Rows | |
|---|---|---|---|---|---|
| CI Query - CI Column | 0 | 193 | 0 | 0 | 51 |
| CI Query - CS Column with Function | 93 | 2674 | 0 | 87 | 51 |
| CI Query - CS Column with Collation | 63 | 2674 | 0 | 62 | 51 |
Test Scenario 2 - Case sensitive query
Now let's take a look at the results when performing a case sensitive search on each of our columns. In this scenario the query of the SQL_Latin1_General_CP1_Cs_AS column is pretty straightforward as we can just use the equality operator in our WHERE clause. For the SQL_Latin1_General_CP1_CI_AS column our only option is to specify the collation in the where clause. Here are examples of each query.
select * from test where col2 COLLATE SQL_Latin1_General_CP1_CS_AS='npE' select * from test where col3='npE'
Looking at the explain plan for these queries we can see that again the query where we specify the collation needs to perform an index scan to execute the query. The later query uses an index seek which will most likely execute much faster using fewer resources.

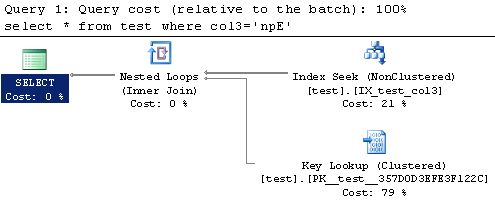
We'll again confirm the performance by looking at the SQL Trace results. From the chart below we can see that the second query which uses an index seek outperforms the other query in every category as was the case in our previous scenario.
| CPU | Reads | Writes | Duration | Rows | |
|---|---|---|---|---|---|
| CS Query - CI Column with Collation | 63 | 2674 | 0 | 64 | 7 |
| CS Query - CS Column | 0 | 24 | 0 | 0 | 7 |
Summary
These simple test scenarios above illustrate how we need to be aware of how our data is being queried by the application. Once we know this we can then design the schema correctly so we can avoid any of these unnecessary index scans.
Next Steps
- Read other tips on SQL Server Collation:
- Look for an upcoming tip on changing a database table column collation






About the author
 Ben Snaidero has been a SQL Server and Oracle DBA for over 10 years and focuses on performance tuning.
Ben Snaidero has been a SQL Server and Oracle DBA for over 10 years and focuses on performance tuning.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
