By: Koen Verbeeck | Comments (11) | Related: > Integration Services Performance
Problem
I have a query that executes quite slowly in SQL Server Management Studio, but when I transfer the data with a SQL Server Integration Services data flow, it takes even more time! The source and destination are both fast and have no bottlenecks, and there are no significant transformations inside the data flow. I read some best practices on the Internet, and they told me to enlarge the buffer size used in the data flow. It is a bit faster now, but still too slow compared to the original query in SSMS. What is happening here?
Solution
The performance of an SSIS data flow is determined by many factors, for example the speed of the source, how fast the destination can write rows, the transformations used (blocking, non-blocking, synchronous and asynchronous) and the number of paths used. However, if you are using a very simple data flow and the performance is slower than is expected then one important factor that can help improve the performance is the size of the buffer. Typically if you make the buffer larger, the data flow can transfer more rows at the same time so performance goes up. This is not always the case though: Slow source? Make your data flow buffers smaller!. You also can't make the buffer too large, or the source takes too much time to fill the buffer and the destination sits idle waiting for the next buffer to show up.
In this tip we have a very simple data flow using a source query with a predictable duration. The data flow takes longer to process all the rows and even larger buffers didn't make the problem go away. What can be the cause of this and how do we solve this? Read on to find out!
The Test Scenario
Let's create a source table with a few million rows. The table structure that illustrates our problem the best is a typical name-value pair table. This kind of table stores different kinds of data in a single text column i.e. our value column and the name column describes what kind of data is stored in the value column. The value column itself is very wide - 5000 characters - to allow anything to be stored.
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[NameValuePairs]') AND [type] IN (N'U')) DROP TABLE [dbo].[NameValuePairs]; GO IF NOT EXISTS (SELECT 1 FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[NameValuePairs]') AND [type] IN (N'U')) BEGIN CREATE TABLE [dbo].[NameValuePairs] ([ID] [int] IDENTITY(1,1) NOT NULL ,[Type] [varchar](100) NOT NULL ,[Value] [varchar](5000) NULL PRIMARY KEY CLUSTERED ([ID] ASC)); END GO
Using the AdventureWorksDW2012 sample data, which you can download here, the table is filled with different types of customer information: names, gender, addresses, birth dates, email addresses and phone numbers.
INSERT INTO [dbo].[NameValuePairs]([Type],[Value]) SELECT [Type] = 'Customer Name' ,[Value] = [FirstName] + ' ' + [LastName] FROM [AdventureWorksDW2012].[dbo].[DimCustomer] UNION ALL SELECT [Type] = 'BirthDate' ,[Value] = CONVERT(CHAR(8),[BirthDate],112) FROM [AdventureWorksDW2012].[dbo].[DimCustomer] UNION ALL SELECT [Type] = 'Gender' ,[Value] = [Gender] FROM [AdventureWorksDW2012].[dbo].[DimCustomer] UNION ALL SELECT [Type] = 'Email Address' ,[Value] = [EmailAddress] FROM [AdventureWorksDW2012].[dbo].[DimCustomer] UNION ALL SELECT [Type] = 'Address' ,[Value] = [AddressLine1] FROM [AdventureWorksDW2012].[dbo].[DimCustomer] UNION ALL SELECT [Type] = 'Phone Number' ,[Value] = [Phone] FROM [AdventureWorksDW2012].[dbo].[DimCustomer]; GO 500
The DimCustomer dimension from AdventureWorks holds about 18000 rows. By string different results together using UNION ALL, the number of rows returned is about 110,000. The INSERT ... SELECT statement is terminated with the batch terminator GO, which is not official T-SQL, but is used by SSMS. If GO is followed by a number, it will execute the batch that number of times. In the script "GO 500" is used, which means the INSERT statement is executed 500 times. This results in over 55 million rows and has an uncompressed data size of about 2.3GB.

Suppose we are interested in the different email addresses of our customers. The source query would look like this:
SELECT [Customer Email] = [Value] FROM [dbo].[NameValuePairs] WHERE [Type] = 'Email Address';
On my current laptop, this query returns 9,242,000 rows in 33 seconds. This is the baseline for our package performance. Since there is overhead in SSMS to display all the results, one can expect the SSIS package to finish in at least 33 seconds, preferably less.
The email addresses are transferred to an email dimension. The column storing the email addresses is only 50 characters wide, as opposed to the 5000 characters of the source column. A smaller column width is chosen because we know email addresses will not exceed this limit in our test case.
CREATE TABLE dbo.DimEmail ([SK_Email] INT IDENTITY(1,1) NOT NULL ,[Email Address] VARCHAR(50) NOT NULL ,[InsertDate] DATE NOT NULL);
The SSIS Package
The resulting SSIS package is fairly easy. The control flow consists of 4 tasks:
- First tasks logs the start of the package into a table.
- Second task truncates the destination table. This is mainly done for testing purposes, so that the package can be run multiple times in a row under the same circumstances.
- Third task is the data flow task. We will discuss it next.
- Final task logs the end of the package
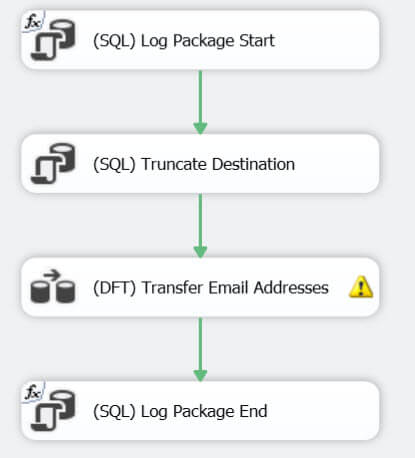
The data flow itself is also very simple: a source to read the data using the query mentioned previously, a derived column adding an audit column and the destination to write the results to the email dimension.

The destination shows a truncation warning because we are attempting to put data from a 5000-character wide column into a 50-character wide column.
Initial Performance
To limit outside effects, the data and log file of the destination database are already big enough to store all the data and to manage all the transactions. This means that no database files have to automatically grow during the data transfer.
In SSDT-BI (the development environment for SSIS packages), the package takes about 40 seconds! This is slower than the source query itself in SSMS! There is some overhead in displaying all the row counters in the user interface and the rows have to be written to the database as well; although this effect is minimal as rows can be written to the destination while the source is still reading. But this is an increase of about 21%. Time to do some optimizing!
Optimizing The Data Flow
One of the most mentioned SSIS best practices on the web is to enlarge the buffer size using the data flow properties DefaultBufferMaxRows and DefaultBufferSize. The SSIS engine uses these properties to estimate the sizes of the buffers used in the pipeline to transfer the data. Larger buffers mean more rows that can be handled at the same time. For a detailed explanation of the calculation involved, check out the TechNet article Data Flow Performance Features.
When we set the maximum number of rows to 30,000 and the default buffer size to 20MB, the package takes about 30 seconds to run. This is only slightly better than the source query performance in SSMS. There is still room for improvement though. From the TechNet article:
The data flow engine begins the task of sizing its buffers by calculating the estimated size of a single row of data.
At the source component, the estimated size of a row is determined by the maximum column sizes of all the columns returned by the source query. This is where the performance problem resides: the Value of the NameValuePairs table has a maximum size of 5000 characters. The SSIS engine will assume this column will always contain 5000 characters, even though in reality the column holds a maximum of 50 characters - only a tenth of the original size! 5000 non-Unicode characters equals 5000 bytes or 5KB. The default buffer size is 10MB, so this means there is only room for 2000 rows, a fifth of the DefaultBufferMaxRows. This all means we are just throwing buffer space away, instead of optimally using it.
By simply adjusting to source query to reflect the actual data length, a substantial performance improvement can be realized.
SELECT [Customer Email] = CONVERT(VARCHAR(50),[Value]) FROM [dbo].[NameValuePairs] WHERE [Type] = 'Email Address';
The maximum column length is now 50, so now a hundred times more rows can fit in a single buffer. When the package is now run, the data flow duration drops to a mere 12 seconds!
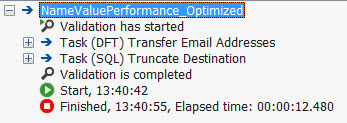
The Visual Studio user interface is not ideal for testing SSIS package performance, as the user interface has to continually update the row counters when running the package. So let's compare performance of the three packages - the package with the default settings, the package with the enlarged buffer and the final package with enlarged buffer and smaller column size - when run 20 times in the SSIS catalog, which allows us to draw more statistically correct conclusions. This following chart depicts the results:
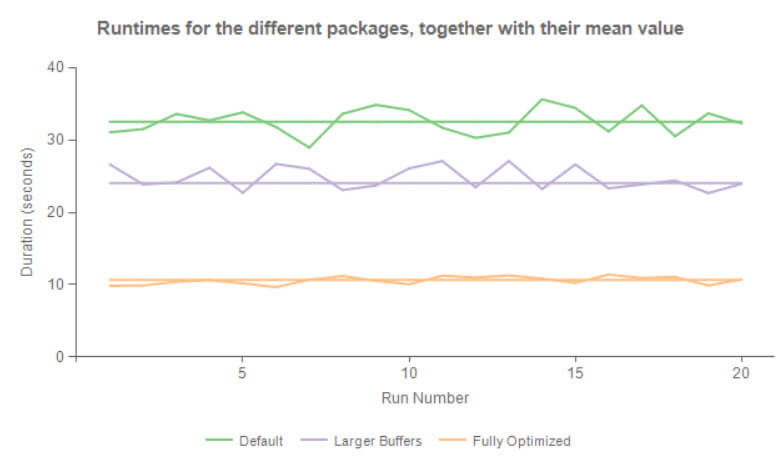
Without the overhead of the Visual Studio GUI, the package with the default settings has a runtime around 32 seconds, comparable with the source query in SSMS. The package with the larger buffer has a distinctive performance improvement with a mean of 24 seconds, while the package with the fully optimized buffer blows away the competition with a mean of 10.675 seconds! The last package also has a more predictable outcome as the durations for the different runs are very close to the mean. The other packages have more variance in their runtimes.
Conclusion
By paying attention to the width of the columns returned by the source, dramatic performance improvements can be achieved. Besides narrowing columns, leaving out unnecessary columns is a best practice. This ensures more rows can be transferred in a single buffer. Performance can be further improved by enlarging the buffer through the data flow properties DefaultBufferSize and DefaultBufferMaxRows.
Next Steps
- Try it out yourself using the T-SQL code provided in this tip and the packages which you can download here.
- For more tips about SSIS best practices:
- Also read these excellent articles:
- Top 10 SQL Server Integration Services Best Practices by the SQLCat Team
- Suggested Best Practices and naming conventions by Jamie Thomson
- Data Flow Performance Features






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
