By: Ray Barley | Comments (16) | Related: More > Integration Services Analysis Services Tasks
Problem
We have experimented with the Slowly Changing Dimension (SCD) Data Flow Transformation that is available in the SSIS designer and have found a few issues with it. Our major concern is the use of the OLE DB Command Data Flow Transformation for all updates (inferred, type 1 and type 2) to rows in the dimension table. Do you have any suggestions?
Solution
You have hit upon the one issue with the Slowly Changing Dimension Data Flow Transformation that likely requires an alternative approach. The issue with the OLE DB Command is that it executes a single SQL statement for each row passing through the Data Flow. When the volume of rows is substantial, this creates an unnecessary and probably unacceptable performance hit. Let's take a step back and analyze the task at hand then discuss an alternative solution.
The term slowly changing dimensions encompasses the following three different methods for handling changes to columns in a data warehouse dimension table:
- Type 1 - update the columns in the dimension row without preserving any change history.
- Type 2 - preserve the change history in the dimension table and create a new row when there are changes.
- Type 3 - some combination of Type 1 and Type 2, usually maintaining multiple instances of a column in the dimension row; e.g. a current value and one or more previous values.
A dimension that implements Type 2 changes would typically have the following housekeeping columns to identify the current row and the effective date range for each row:
- Natural Key - the unique source system key that identifies the entity; e.g. CustomerID in the source system would be called nk_CustomerID in the dimension.
- Surrogate Key (or warehouse key) - typically an identity value used to uniquely identify the row in the dimension. For a given natural key there will be an instance of a row for each Type 2 change so the natural key will not be unique in the dimension.
- CurrentMember - a bit column to indicate if the row is the current row.
- EffectiveDate - a datetime (or smalldatetime) column to indicate when the row became the current row.
- ExpirationDate - a datetime (or smalldatetime) column to indicate when the row ceased being the current row.
The effective date range columns retain the history of a natural key in the dimension, allowing us to see the column values at any point in time. Fact table rows can be joined to the dimension row where the fact row transaction date is between the effective date range of the dimension row.
When you add the SCD Data Flow Transformation to the Data Flow designer, you step through a wizard to configure the task, and you will wind up with the Slowly Changing Dimension task and everything that follows below being added to the Data Flow designer (the task names generated by the SCD wizard have been updated to add clarification):
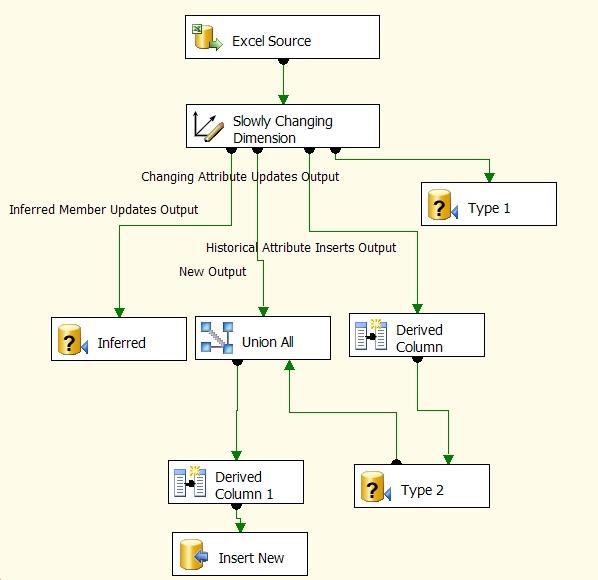
Main points about the above screen shot:
- The Excel Source is a sample data source representing data extracted from a source system that is used to update a dimension table in a data warehouse.
- The Type 1 OLE DB Command task updates dimension rows one at a time by executing an UPDATE statement on the dimension table.
- The Type 2 OLE DB Command task "expires" the current dimension rows one at a time (sets the ExpirationDate or CurrentMember flag) by executing an UPDATE statement.
- The Insert New OLE DB Destination task inserts a new row into the dimension table when there is a new row in the source system or a Type 2 change.
- The Inferred OLE DB Command task performs a Type 1 update to a dimension row that was created with default values as a result of an early arriving fact. An early arriving fact is one where the fact row has a source system key value that does not exist in the dimension; we will discuss Inferred processing in part two of this tip.
Now that we have described how the SCD transformation implements slowly changing dimension processing, we can discuss an alternative solution. As an example we will use a Customer dimension that is updated with source system data in an Excel spreadsheet. The SSIS package Control Flow looks like this:
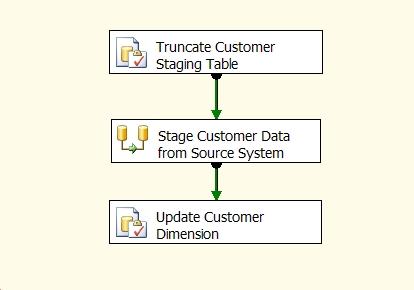
Main points about the above solution:
- Truncate Customer Staging Table is an Execute SQL task that clears out the Customer dimension staging table.
- Stage Customer Data from Source System is a Data Flow task that extracts the rows from the Excel spreadsheet, cleanses and transforms the data, and writes the data out to the staging table.
- Update Customer Dimension is an Execute SQL task that invokes a stored procedure that implements the Type 1 and Type 2 handling on the Customer dimension.
An additional detail about Type 1 and Type 2 processing is that a dimension may implement both. In other words some column changes may be handled as Type 1 and other column changes may be handled as Type 2. An elegant way to implement this is to take advantage of the SQL Server CHECKSUM function. CHECKSUM calculates a unique integer hash value based on the values of every column in a row or a subset of columns. We can use a hash value comparison to determine whether anything has changed in our list of columns in the staging table versus the dimension table.
Let's take a look at our Customer dimension table:
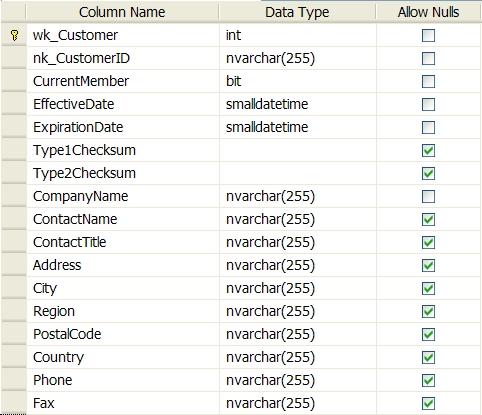
The checksum columns are defined as follows:
- [Type1Checksum]
[Type2Checksum]
AS CHECKSUM([Address],[City],[Region],[PostalCode],[Country])There is a separate CHECKSUM value calculated for the list of Type 1 columns and the list of Type 2 columns. In our staging table we have the same two CHECKSUM computed columns; the column lists must match exactly in order for this to work.
As a general rule the staging table schema mirrors the dimension table schema but includes a couple of other housekeeping columns as shown below:
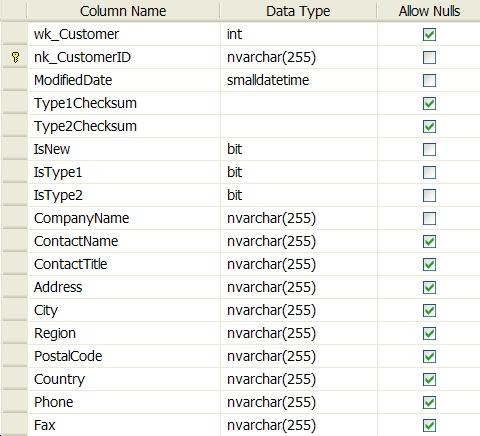
The housekeeping columns in staging are as follows:
-
IsNew is set to 1 if this is a new dimension row.
-
IsType1 is set to 1 if there is a change to any column handled as Type 1.
-
IsType2 is set to 1 if there is a change to any column handled as Type 2.
Finally let's review the single stored procedure that implements the Type 1 and Type 2 processing and is invoked in the Update Customer Dimension Execute SQL task as noted above. The first step is to update the housekeeping columns in the staging table to specify whether the row is new, has a Type 1 change, or a Type 2 change. Remember that Type 1 and Type 2 changes are not mutually exclusive; you can have one, both, or neither. We simply join the staging table to the dimension on the natural key and CurrentMember = 1 to set the housekeeping flags.
UPDATE stg SET
wk_Customer = dim.wk_Customer
,IsNew = CASE WHEN dim.wk_Customer IS NULL
THEN 1 ELSE 0 END
,IsType1 = CASE WHEN dim.wk_Customer IS NOT NULL
AND stg.Type1Checksum <> dim.Type1Checksum
THEN 1 ELSE 0 END
,IsType2 = CASE WHEN dim.wk_Customer IS NOT NULL
AND stg.Type2Checksum <> dim.Type2Checksum
THEN 1 ELSE 0 END
FROM dbo.stg_dim_Customer stg
LEFT OUTER JOIN dbo.dim_Customer dim ON
dim.nk_CustomerID = stg.nk_CustomerID
AND dim.CurrentMember = 1 |
The Type 1 changes are handled by updating the dimension table from staging where the IsType1 column = 1. Note that if there are multiple rows for the natural key in the dimension, all rows will be updated. This is typically how Type1 changes are handled but you can easily restrict the update to the current row if desired.
UPDATE dim SET [ContactName] = stg.[ContactName] ,[ContactTitle] = stg.[ContactTitle] ,[Phone] = stg.[Phone] ,[Fax] = stg.[Fax] FROM dbo.stg_dim_Customer stg JOIN dbo.dim_Customer dim ON dim.nk_CustomerID = stg.nk_CustomerID WHERE IsType1 = 1 |
The Type 2 changes are handled by expiring the current dimension row. The ExpirationDate is set to the ModifiedDate per the staging table less 1 minute.
UPDATE dim SET CurrentMember = 0 ,ExpirationDate = DATEADD(minute, -1, stg.ModifiedDate) FROM dbo.stg_dim_Customer stg JOIN dbo.dim_Customer dim ON dim.wk_Customer = stg.wk_Customer WHERE IsType2 = 1 |
A row is inserted into the dimension table for new rows as well as Type 2 changes. Typically the EffectiveDate in new rows may be set to the minimum value of the datetime column as a convenience instead of the actual ModifiedDate (i.e. created date) just so that if a fact row had a transaction date before the dimension row's EffectiveDate it would still be in the range of the earliest dimension row. The ExpirationDate is set to the maximum value of the datetime column; some folks prefer NULL which also works.
INSERT INTO dbo.dim_Customer ( nk_CustomerID ,CurrentMember ,EffectiveDate ,ExpirationDate ,CompanyName ,ContactName ,ContactTitle ,Address ,City ,Region ,PostalCode ,Country ,Phone ,Fax ) SELECT nk_CustomerID ,1 ,CASE WHEN IsNew = 1 THEN '1900-01-01' -- MIN of smalldatetime ELSE ModifiedDate END ,'2079-06-06' -- MAX of smalldatetime ,CompanyName ,ContactName ,ContactTitle ,Address ,City ,Region ,PostalCode ,Country ,Phone ,Fax FROM dbo.stg_dim_Customer stg WHERE IsType2 = 1 OR IsNew = 1 |
Let's take a look at an example of Type 2 processing in the dim_Customer table. The following query results show a customer after the region has been updated. Region is one of the columns that is handled as a Type 2 change. As you can see a new row has been inserted with CurrentMember = 1, an EffectiveDate = the MdifiedDate when the change was processed, and an ExpirationDate which is the maximum value for a smalldatetime. The original row was expired and its CurrentMember = 0 and ExpirationDate is set to the ModifiedDate from the source system less 1 minute. The 1 minute subtraction eliminates any overlap in the effective date range.

Next Steps
- Stay tuned for part two of this tip; there are some additional points to discuss such as transaction handling, using different databases and/or instances for staging and the warehouse, and handling early arriving facts (aka Inferred member processing).
- Download a copy of the sample SSIS package here to experiment with slowly changing dimensions. Note that the package assumes you have a SQL Server instance running locally with a database called MSSQLTips. Unzip the files into the folder C:\MSSQLTips to minimize changes to get the sample to run.






About the author
 Ray Barley is a Principal Architect at IT Resource Partners and a MSSQLTips.com BI Expert.
Ray Barley is a Principal Architect at IT Resource Partners and a MSSQLTips.com BI Expert.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
