By: Rick Dobson | Comments (2) | Related: 1 | 2 | 3 | > Functions System
Problem
My company receives sets of names in a variety of different formats from business partners. Are there any special tips for processing a whole set of name source strings instead of parsing them individually? Furthermore, what are some tips for parsing name source strings into one consistent format when the strings from different partners arrive in different formats?
Solution
The initial tip in this multi-part series on name parsing reviewed T-SQL string functions that are especially useful for parsing names. The last example in the initial tip demonstrated how to use the functions to extract and format names from name strings no matter whether the name source strings contained one, two, three, or four name parts. However, there was no special focus on how to process a set of name source strings from a business partner nor how to integrate result sets with different name formats from different partners into one consistent format. This second tip specifically addresses these issues.
Because extracting name parts from name source strings is a specialized kind of activity, you may find it convenient it to pump the name source strings into a temporary table that can also store the extracted name parts along with any tracking information for identifying name source strings. You can then create a series of nested sub-queries based initially on the temporary table that perform successive steps in extracting names parts from the name source strings. The examples within this tip demonstrate the approach with three nested sub-queries.
- The innermost query references the temporary table with name source strings and extracts the location of delimiters, such as a space or a comma, between strings within the name source string on a row of the temporary The strings within a name string do not necessarily represent name parts -- just string parts within the name source string.
- The middle query uses the result set from the innermost query as its source and extracts strings separated by delimiters in the name source string for a row.
- The outermost query takes the extracted strings from the second query and maps them to name parts based on the string values and prescribed formats for mapping string parts to name parts, such as first name, middle name, last name, and suffix.
Your application logic controls the process for mapping extracted strings to name parts. The approach illustrated in this tip allows for different formats for name source strings from different vendors. Furthermore, the name source strings from different vendors can relied on different rules for mapping extracted strings to name parts. This tip concludes with an example demonstrating how to combine parsed names from different vendors into one consistently parsed set of name parts.
Extracting Name Parts In One Order from a Vendor
The initial example for this tip illustrates how to take the name source strings from a client, extract string parts, and insert the extracted strings into different name parts. The programming illustrates how to extract up to four string parts and assign the extracted parts to any of up to four name parts.
The T-SQL code for the first example appears below. Before diving into its detail, it is advantageous to review the structure of the script. The initial part creates and populates a temporary table for storing name strings and their parsed parts. This initial part also includes comments on the rules for mapping extracted strings to name parts. The second part of the script includes the three nested queries. The innermost query has the name SourceAndDelimiters. The middle subquery has the name SourceAndExtractedStrings. T-SQL does not require a name for the outermost query. However, if it did, the name would be something like SourceAndNameParts.
The code for the initial part has two main elements: a CREATE TABLE statement and an INSERT INTO statement. The CREATE TABLE statement makes a temporary table named ##NamesFromDifferentClients_1. The INSERT INTO statement populates the temporary table with four name source strings from client A. The four name source strings have different formats. The first one has just two strings within it. The second and third name source strings each have three strings. The fourth source string has four within it. With each new name source string entered by the INSERT statement, the ID column in the ##NamesFromDifferentClients_1 temporary table receives a new value dictated by its IDENTITY property settings.
In order for the CREATE TABLE statement to operate successfully, there cannot be a currently existing table with the name used in the CREATE TABLE statement. A preceding IF statement followed by a DROP TABLE statement conditionally drops the ##NamesFromDifferentClients_1 table if it already exists. These two statements ensure there is no table named ##NamesFromDifferentClients_1 prior to the operation of the CREATE TABLE statement.
The four name source strings used to populate the ##NamesFromDifferentClients_1 table have different formats. The first source name string has just two strings within it. The second and third name source strings each have three strings within them. The fourth name source string has four strings. The strings within each name source string map to different name parts depending on the number of strings in the name source string. The commented lines between /* and */ at the end of the initial part of the first example describes how the code maps the strings to name parts.
- If there are just two strings, the first string maps to the FirstName field, and the second string maps to the LastName field.
- If there are three strings, the first string maps to the FirstName field, the second string maps to the MiddleName field, and the third string maps to the LastName field.
- If there are four strings, the first three strings map to the same name fields as name source strings with just three strings within then, and the fourth string maps to the Suffix field.
There are two right parentheses at the bottom of the script. These parentheses denote the end of the innermost and middle layer queries. Recall that the innermost query has the name SourceAndDelimiters, the middle layer query has the name SourceAndExtractedStrings. The result set from the innermost query is the source for the middle layer query, and the result set from the middle layer query is the source for the outermost query; recall that T-SQL does not require a name for the outermost query.
The source for the innermost query is the ##NamesFromDifferentClients_1 temporary table, which was previously created and populated in the initial part of the example. The role of the innermost query is to populate three fields in its result set, whose contents are the source for the middle layer query. The three populated fields have the names space_1_loc, space_2_loc, and space_3_loc, which are the names for the first, second, and third space delimiters in a name source string. If there is no second or third space delimiter within a name source string, the values of space_2_loc, and space_3_loc are set equal to 0 implicitly for space_2_loc and explicitly for space_3_loc.
-- create temporary table for storing source name strings
-- and their associated name parts
IF OBJECT_ID('tempdb..##NamesFromDifferentClients_1') IS NOT NULL
DROP TABLE ##NamesFromDifferentClients_1
CREATE TABLE ##NamesFromDifferentClients_1
(
ID BIGINT IDENTITY(1,1),
ClientID varchar(20),
SourceString varchar(75),
FirstName varchar(20),
MiddleName varchar(20),
LastName varchar(30),
Suffix varchar(5)
)
-- populate temporary table with source name strings
INSERT INTO ##NamesFromDifferentClients_1
(
ClientID,
SourceString
)
VALUES
('A', 'Tim Bits'),
('A', 'Ken dePaul Jones'),
('A', 'Sally S Cats'),
('A', 'Mike George Mountains JR')
/*
-- Mapping rules for going from string parts to name parts
first_string second_string
as FirstName LastName
first_string second_string third_string
as FirstName MiddleName LastName
first_string second_string third_string fourth_string
as FirstName MiddleName LastName Suffix
*/
-- map extracted strings to name parts
SELECT
ID
,ClientID
,SourceString
,first_string FirstName
,CASE
WHEN third_string = '' THEN CAST('' AS varchar(20))
ELSE CAST(second_string AS varchar(20))
END MiddleName
,CASE
WHEN third_string = '' THEN CAST(second_string AS varchar(30))
ELSE CAST(third_string AS varchar(30))
END LastName
-- Remove leading blank
,LTRIM(CASE
WHEN fourth_string = '' THEN CAST('' AS varchar(5))
ELSE CAST(fourth_string AS varchar(5))
END) Suffix
FROM
(
-- extract strings
SELECT
ID
,ClientID
,SourceString
,LEFT(SourceString,space_1_loc-1) first_string
,CASE
WHEN space_2_loc > 0
THEN
CAST(
SUBSTRING(SourceString,
space_1_loc+1,space_2_loc-space_1_loc)
AS varchar(20)
)
ELSE
CAST(
RIGHT(SourceString,
DATALENGTH(SourceString)-space_1_loc)
AS varchar(20)
)
END second_string
,CASE
WHEN space_2_loc = 0
THEN CAST('' AS varchar(30))
WHEN space_3_loc = 0
THEN SUBSTRING(SourceString,space_2_loc+1,
DATALENGTH(SourceString))
WHEN space_3_loc > 0
THEN
CAST(
SUBSTRING(SourceString,
space_2_loc+1,
space_3_loc-space_2_loc)
AS varchar(30)
)
END third_string
,CASE
WHEN space_2_loc = 0
THEN CAST('' AS varchar(30))
WHEN space_3_loc = 0
THEN CAST('' AS varchar(30))
ELSE
CAST(
SUBSTRING(SourceString,
space_3_loc,
DATALENGTH(SourceString))
AS varchar(5))
END fourth_string
FROM
(
-- extract delimiter locations
SELECT
ID, ClientID, SourceString,
CHARINDEX(' ',SourceString,1) space_1_loc,
CHARINDEX(' ',SourceString,
CHARINDEX(' ',SourceString,1)+1) space_2_loc,
CASE
WHEN
CHARINDEX(' ',SourceString,
CHARINDEX(' ',SourceString,1)+1)=0
THEN 0
ELSE
CHARINDEX(' ',SourceString,
CHARINDEX(' ',SourceString,
CHARINDEX(' ',SourceString,1)+1)
+1)
END space_3_loc
FROM ##NamesFromDifferentClients_1
) SourceAndDelimiters
) SourceAndExtractedStrings
The following screen shot shows the appearance of the result set from the innermost query. You can easily tell from the row with an ID value of 1 that the first space in the name 'Tim Bits' is at the fourth character in the name source string. The fact that both space_2_loc and space3_loc confirm that the name string for ID 1 has just two strings within it. In contrast, the name string for ID 4 has four parts because there are values for space_1_loc, space_2_loc, and space_3_loc. The third space within the name string for ID 4 separates the third and fourth string parts.

The result set for the middle layer query, SourceAndExtractedStrings, retains, ID, ClientID, and SourceString from the result set of its source query, SourceAndDelimiters. In addition to retained fields, the SourceAndExtractedStrings query also adds four new fields named first_string through fourth_string. The code assumes that there are always at least two strings with a blank space between them in a name source string. This first and second strings are assigned to first_string and second_string in the query's results set. The third_string, and fourth_string field values receive the values of the third or fourth strings, respectively, in a name source string or an empty string if there is no string corresponding to one of these remaining fields in the result test.
The next screen shot shows the values in the result set for the SourceAndExtractedStrings query. Because the string order corresponds generally to the name part order, there is no strict requirement for a third query that assigns the extracted strings to name parts (especially if all the name source strings had the same number of strings within them). However, if your source data requires different rules for parsing data from different clients and/or any of your business partners send name strings containing strings in a different order than their name parts, then your name parsing applications will benefit from a middle layer query which merely extracts strings, and then an outermost query that assigns the strings to name parts.

The outermost query accepts the SourceAndExtractedStrings result set as its source. The role of the outermost query is to assign the string parts to name parts. Although the strings within a name source string for the first example always occur in the same order as the name parts, the second_string field from the source result set does not always populate the same name part. For example, when there are just two strings in a name string, the second string maps to the LastName field, but when there are three string parts within a name string, then the second string maps to the MiddleName field. The following screen shows the result set from the outermost query.
Notice that the code for the Suffix is embedded within an LTRIM function. This function strips leading blanks from a string. The RTRIM function removes trailing spaces from a string in the same way that the LTRIM function removes leading spaces. When implementing name parsing it is not uncommon to encounter unwanted leading or trailing blanks. This can happen because a source name string has more than one blank between strings within it or you do not perfectly account for the precise positions of all characters in a string within a name source string. In code meant for production applications, I regularly encapsulate expressions for extracted strings within both LTRIM and RTRIM functions.

Extracting Name Parts from a Second Vendor Who Formats Names Differently
One powerful feature of the preceding approach to name parsing is the re-usability of key elements of the code when processing names in different formats. Consider the case of a second vendor who submits names in the order of last name and optionally a suffix followed by a comma and then the remaining name parts -- namely, first name and optionally a middle name. In addition, this second vendor allows for the input of some name parts that are comprised of two strings, such as the name Mary Anne being comprised of the strings Mary and Anne.
Very minor code tweaks can accommodate a different order for the names, the use a comma as well as spaces to separate strings in a name, and even differentially process names comprised of two strings versus just one string. After you extract the strings from a name field comprised of multiple strings with different separators between the strings, then you can combine the strings in any order that your application logic requires. You can even specify conditional logic for mapping strings to name parts, such as first name.
The T-SQL code for the second example appears below. This code handles results from another vendor with names formatted differently than in the first example. Before diving into the details, please note that the structure of the code is the same as in the preceding example although it processes names with a radically different format. For example, the code still uses three queries nested within one another.
- The innermost query still discovers the locations of delimiters between the strings in name field. However, instead of just reporting the location of space delimiters, this second example reports on the location of space and comma delimiters.
- Just as in the first example, the middle query extracts the strings within a name field. In this second example, the extraction of strings needs to account for space and comma delimiters.
- Again, the outermost query has the role of mapping strings within a name source string to name parts. However, this second example allows for the possibility of first names being comprised of either one string or two strings.
The code sample commences by creating a temporary table with the name source strings. With one exception for an added name, the names are the same as in the first example. However, the formatting is different so that last name and optionally a suffix start the string followed by a comma and the first name and optionally a second name. The new name is for a person with a first name comprised of two strings, which are Mary and Anne.
-- create temporary table for storing source name strings
-- and their associated name parts
IF OBJECT_ID('tempdb..##NamesFromDifferentClients_1') IS NOT NULL
DROP TABLE ##NamesFromDifferentClients_1
CREATE TABLE ##NamesFromDifferentClients_1
(
ID BIGINT IDENTITY(1,1),
ClientID varchar(20),
SourceString varchar(75),
FirstName varchar(20),
MiddleName varchar(20),
LastName varchar(30),
Suffix varchar(5)
)
INSERT INTO ##NamesFromDifferentClients_1
(
ClientID,
SourceString
)
VALUES
('B', 'Bits, Tim'),
('B', 'Jones, Ken dePaul'),
('B', 'Cats, Sally S'),
('B', 'Mountains JR, Mike George'),
('B', 'Mountains, Mary Anne Bits')
/*
String formats
first_string, second_string
as LastName, FirstName
first_string, second_string third_string
as LastName, FirstName MiddleName
first_string second_string, third_string fourth_string
as LastName Suffix, FirstName MiddleName
first_string, second_string third_string fourth_string
as LastName, FirstName MiddleName
*/
SELECT
ID
,ClientID
,SourceString
,CASE
WHEN space_3_loc = 0 THEN second_string
WHEN comma_loc < space_1_loc AND space_3_loc > 0
THEN second_string + ' ' + third_string
ELSE third_string
END FirstName
,LTRIM(CASE
WHEN space_2_loc = 0 THEN ''
WHEN space_3_loc = 0 THEN third_string
ELSE fourth_string
END) MiddleName
,first_string LastName
,CASE
WHEN comma_loc > space_1_loc THEN second_string
ELSE ''
END Suffix
FROM
(
-- extract strings
SELECT
ID
,ClientID
,SourceString
,comma_loc
,space_1_loc
,space_2_loc
,space_3_loc
-- Remove trailing comma from either first or second string
,REPLACE(LEFT(SourceString,space_1_loc-1)
,',','') first_string
,REPLACE(
CASE
WHEN space_2_loc > 0
THEN
CAST(
SUBSTRING(SourceString,
space_1_loc+1,space_2_loc-space_1_loc)
AS varchar(20)
)
ELSE
CAST(
RIGHT(SourceString,
DATALENGTH(SourceString)-space_1_loc)
AS varchar(20)
)
END,
',','') second_string
,CASE
WHEN space_2_loc = 0 THEN CAST('' AS varchar(30))
WHEN space_3_loc = 0 THEN
SUBSTRING(SourceString,
space_2_loc+1,DATALENGTH(SourceString))
WHEN space_3_loc > 0 THEN
CAST(
SUBSTRING(SourceString,
space_2_loc+1,
space_3_loc-space_2_loc)
AS varchar(30)
)
END third_string
,CASE
WHEN space_2_loc = 0 THEN CAST('' AS varchar(30))
WHEN space_3_loc = 0 THEN CAST('' AS varchar(30))
ELSE
CAST(
SUBSTRING(SourceString,
space_3_loc,
DATALENGTH(SourceString))
AS varchar(20))
END fourth_string
FROM
(
-- extract delimiter locations
SELECT
ID, ClientID, SourceString,
CHARINDEX(',',SourceString,1) comma_loc,
CHARINDEX(' ',SourceString,1) space_1_loc,
CHARINDEX(' ',SourceString,
CHARINDEX(' ',SourceString,1)+1) space_2_loc,
CASE
WHEN
CHARINDEX(' ',SourceString,
CHARINDEX(' ',SourceString,1)+1)=0
THEN 0
ELSE
CHARINDEX(' ',SourceString,
CHARINDEX(' ',SourceString,
CHARINDEX(' ',SourceString,1)+1)
+1)
END space_3_loc
FROM ##NamesFromDifferentClients_1
) SourceAndDelimiters
) SourceAndExtractedStrings
The innermost query, SourceAndDelimiters, is identical to the first example, except for one function call. The function is a CHARINDEX function that returns the location of a comma in the name source string. All the source name strings in this example contain at least two strings separated by a comma, and the comma's location can indicate how to assign a string within a name source string to a name part. In accordance with its name, this query returns the name source strings along with the comma and space delimiter locations for each row in the input record set, ##NamesFromDifferentClients_1.
The middle query, SourceAndExtractedStrings, focuses on extracting each of up to four strings from the name source string on each row in its input result set. The key difference between the middle query in the second example and the first example is the need to remove the comma at the end of either the first or second string. A REPLACE function accomplishes this objective. The function is the outer function for both the first and second string extraction expressions. The REPLACE function replaces a comma in the input source with an empty string (''). The output from this middle query retains the information about delimiter locations along with the actual strings in an input source.
The outermost query uses the delimiter locations to map the strings within a name source string to name parts. This query is most different between the first example and the second example. This is so because the outermost query in the second example maps strings to name parts based on a string's order and the location of delimiters within an input source while the outermost query in the first example ignores the location of delimiters when assigning strings within a name field to name parts.
- The first name can receive one of three assignments within a CASE...END statement. For the sample of names in the input sources when there is no third space delimiter, the first name equals the second string. When there is a third space delimiter and a comma occurs before the first space, then the first name equals the second string followed by a space and then the third string; this second condition parses two-part names, such as Mary Anne. For other names in the sample, the first name is always the third string.
- The middle name can also be one of three values, but the assignment logic is less complex. When there is no second space delimiter, then the middle name is set equal to an empty string. When there is no third space delimiter, then the CASE...END statement assigns the third string to the middle name. In other cases for the sample input name sources, the middle name equals the fourth string.
- The last name is always the first string because it is to the left of the comma in input source string.
- The suffix is conditionally populated with the second string if the comma location is after the first space delimiter. Otherwise, the suffix is set equal to an empty string.
Notice that the discussion of the outermost query referred several times "to the sample of names provided". The design of the parsing rules for this outermost query may vary depending on the sample of input name source strings. In my experience, a new sample or adding more names in different formats can easily result in improper parsing. An automated name parsing implementation may not always result in a successful parsing for all input source names. In such cases, there are at least a couple of remedies. One is to design a new parsing rule and use it for name source strings that do not parse successfully with your current parsing rule. Another approach is to filter out name source strings that can not be parsed successfully with your parsing code. You can later recover unparsed name source strings and return them for either manual parsing or pre-processing for automated re-formatting so that the re-formatted name source strings can be successfully parsed by an automated parsing implementation.
Reviewing the result sets from each of the three queries can clarify the operation of the T-SQL code for the second example. The following screen shows the result set from the innermost query. Notice how this result set adds a column to the first result set from the first example. In particular, the query adds the location of a comma in the name source. The innermost query in this example is optimized to handle name sources that start with the last name and optionally a suffix followed by a comma. The query also uses the location of space delimiters for strings within the name source.
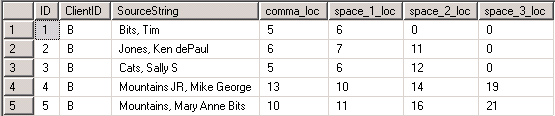
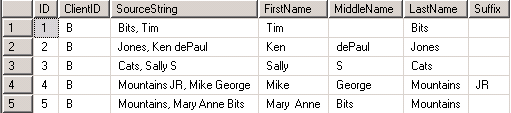
The result set from the middle query appears next. Recall that the primary role of this query is to extract strings from within a name source string. However, the second example relies on more complex logic for parsing name parts from a name source string than the first example. As a result the middle query from the second example returns the strings along with the locations of the comma and space delimiters. The outermost query requires this extra information to assign strings within the name source string to name parts.

The final result set, which appears below, is for the outermost query. I especially urge you to notice how the fifth row combines two strings into the first name field. All the other rows in this example and the preceding example insert a single string into the first name field value. You can use the result sets from the middle query and the outermost query along with the code listing to discover for yourself the details of how the code implements its name parsing. All the field values you need for the parsing transformation from the middle query to the outermost query are in the result set for the second example's middle query.
Extracting Name Parts from Two Vendors to One Consistent Format
When your application requires name parsing from multiple vendors, then the parsing code must somehow combine the parsed names from different vendors. Even if you have a single business partner providing name source strings, it is not uncommon to have name source strings with name parts in different orders or with other special conditions that require special parsing. In any of these situations, you can parse differently formatted names to one consistent format. Finally, you can concatenate the result sets from each set of parsed names into one overall result set.
The general approach is to implement a separate three-tiered query set for each parsing rule that your data require. For the innermost query in each query set, add a WHERE clause that filters just the name source strings that can be parsed by the rules within that query set. You must specify an equal number of output columns from each query set. Perform the concatenation with a UNION statement between each query set so that the parsed names are output as one result set across all the unioned result sets for each parsing rule.
The third example in this tip concatenates the name source strings from the first example with the name source strings from the second example. A WHERE clause added to the innermost query of the three-tiered query set from each example filters by ClientID value. Rows with a ClientID value of A are parsed by the first example code, and rows with a ClientID value of B are parsed by the second example code.
The following short script, which commences the code for the third example, pumps the name source strings with ClientID values of A and B into a temporary table. These name source strings are the same as those used in the first and second examples. The only unique feature of this code is that it contains name source strings from two different vendors who each use a different name format.
-- create temporary table for storing source name strings
-- and their associated name parts
IF OBJECT_ID('tempdb..##NamesFromDifferentClients_1') IS NOT NULL
DROP TABLE ##NamesFromDifferentClients_1
CREATE TABLE ##NamesFromDifferentClients_1
(
ID BIGINT IDENTITY(1,1),
ClientID varchar(20),
SourceString varchar(75),
FirstName varchar(20),
MiddleName varchar(20),
LastName varchar(30),
Suffix varchar(5)
)
INSERT INTO ##NamesFromDifferentClients_1
(
ClientID,
SourceString
)
VALUES
('A', 'Tim Bits'),
('A', 'Ken dePaul Jones'),
('A', 'Sally S Cats'),
('A', 'Mike George Mountains JR'),
('B', 'Bits, Tim'),
('B', 'Jones, Ken dePaul'),
('B', 'Cats, Sally S'),
('B', 'Mountains JR, Mike George'),
('B', 'Mountains, Mary Anne Bits')
After inputting the name source strings, the third example includes the three-tiered queries from the first and second examples with a WHERE clause inserted into the innermost query of each query set. The WHERE clause selects just the name source strings that are appropriate for the parsing rules implemented by its query set. The following excerpt from the third example illustrates the format of the WHERE clause for rows with a ClientID value of A. With the exception of the WHERE clause, these rows are parsed by the code in the first example. Therefore, you can compare this code excerpt from the third example to the innermost query listed above for the first example. This comparison will illustrate with a specific example how to formulate and position the WHERE clause within a previously developed query set for name parsing.
SELECT
ID, ClientID, SourceString,
CHARINDEX(' ',SourceString,1) space_1_loc,
CHARINDEX(' ',SourceString,
CHARINDEX(' ',SourceString,1)+1) space_2_loc,
CASE
WHEN
CHARINDEX(' ',SourceString,
CHARINDEX(' ',SourceString,1)+1)=0
THEN 0
ELSE
CHARINDEX(' ',SourceString,
CHARINDEX(' ',SourceString,
CHARINDEX(' ',SourceString,1)+1)
+1)
END space_3_loc
FROM ##NamesFromDifferentClients_1
WHERE ClientID = 'A'
The result set from the outermost query in the third example appears below. For each of the nine rows of name source strings, the output shows an identity value, the ClientID value, the original name source string, and four more columns with parsed results from the source string. This output confirms that you can devise and code an exceptionally broad range of parsing rules for data from multiple vendors into one consistent set of names.
The result set below illustrates another advantage of converting names provided in different formats into one consistent format. Notice that the source strings for rows 1 and 2 are for a person with the same name. This is evident after parsing. However, a simple comparison with an equal operator of the name source strings 'Tim Bits' and 'Bits, Tim' would not indicate the two names are for the same person. When you have an account record matching requirement for records with differently formatted name source strings, name parsing can contribute to the goal of identifying records for the same person.
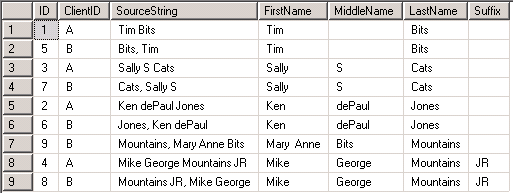
Next Steps
This tip is an extension of an earlier tip on name parsing. The first tip covered the basics of string functions and included three examples of how to use the functions for name parsing. It also had an associated scripts file that you can download to modify as you build your understanding of T-SQL string functions and how to use them for name parsing. If you find the use of string functions in this tip outside your normal T-SQL coding experience, the prior tip is likely to be a good resource to study.
The focus of this second installment on name parsing is how to perform name parsing separately for a set of name source strings. When processing a result set containing name source strings, multiple parsing rules may be appropriate, such as how to handle names with and without suffixes or how to handle first names comprised of one or two strings. Sometimes it is not easily possible to parse a set of name source strings with a single set of parsing rules. For such cases, the tip illustrates how to devise separate parsing rules for name source strings that require different rules but yet need to be combined into one set. One recommended way to start building your own complex name parsing applications is to download the three sample applications described by this tip and then start modifying them according to your own special application and/or learning requirements.






About the author
 Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.
Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
