By: Greg Robidoux | Comments (9) | Related: > JOIN Tables
Problem
Sometimes there is a need to combine data from multiple tables or views into one comprehensive dataset. This may be for tables with similar data within the same database or maybe there is a need to combine similar data across databases or even across servers.
In this tip we will take a look at the how to use UNION vs. UNION ALL commands and how they differ.
Solution
In SQL Server you have the ability to combine multiple datasets into one comprehensive dataset by using the UNION or UNION ALL operators. There is a big difference in how these work as well as the final result set that is returned, but basically these commands join multiple datasets that have similar structures into one combined dataset.
UNION
This operation will allow you to join multiple datasets into one dataset and will remove any duplicates that exist. Basically it is performing a DISTINCT operation across all columns in the result set.
UNION ALL
This operation again allows you to join multiple datasets into one dataset, but it does not remove any duplicate rows. Because this does not remove duplicate rows this process is faster, but if you don't want duplicate records you will need to use the UNION operator instead.
Rules to UNION data
- Each query must have the same number of columns
- Each column must have compatible data types
- Column names for the final result set are taken from the first query
- ORDER BY and COMPUTE clauses can only be issued for the overall result set and not within each individual result set
- GROUP BY and HAVING clauses can only be issued for each individual result set and not for the overall result set
Tip: If you don't have the exact same columns in all queries use a default value or a NULL value such as:
SELECT firstName, lastName, company FROM businessContacts UNION SELECT firstName, lastName, NULL FROM nonBusinessContacts or SELECT firstName, lastName, createDate FROM businessContacts UNION ALL SELECT firstName, lastName, getdate() FROM nonBusinessContacts
UNION vs. UNION ALL Examples
Let's take a look at a few simple examples of how these commands work and how they differ. As you will see the final resultsets will differ, but there is some interesting info on how SQL Server actually completes the process.
UNION ALL
In this first example we are using the UNION ALL operator against the Employee table from the AdventureWorks database. This is probably not something you would do, but this helps illustrate the differences of these two operators.
There are 290 rows in table dbo.Employee.
SELECT * FROM HumanResources.Employee UNION ALL SELECT * FROM HumanResources.Employee UNION ALL SELECT * FROM HumanResources.Employee
When this query is run the result set has 870 rows. This is the 290 rows returned 3 times. The data is just put together one dataset on top of the other dataset.
Here is the execution plan for this query. We can see that the table was queried 3 times and SQL Server did a Concatenation step to concatenate all of the data.
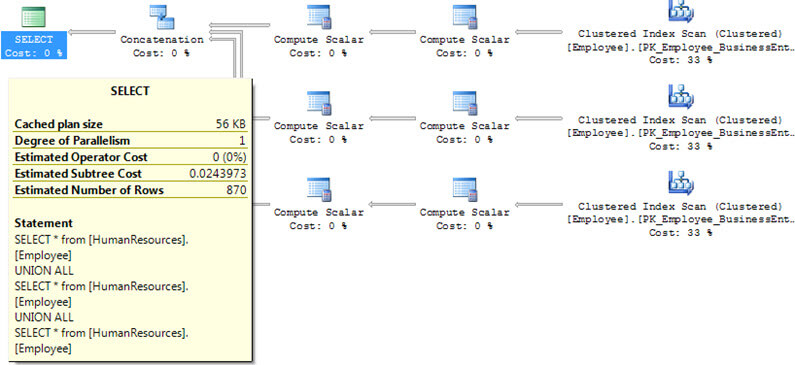
UNION
In this next example we are using the UNION operator against the Employee table again from the AdventureWorks database.
SELECT * FROM HumanResources.Employee UNION SELECT * FROM HumanResources.Employee UNION SELECT * FROM HumanResources.Employee
When this query is run the result set has 290 rows. Even though we combined the data three times the UNION operator removed the duplicate records and therefore returns just the 290 unique rows.
Here is the execution plan for this query. We can see that SQL Server first queried 2 of the tables, then did a Merge Join operation to combine the first two tables and then it did another Merge Join along with querying the third table in the query. So we can see there was much more worked that had to be performed to get this result set compared to the UNION ALL.
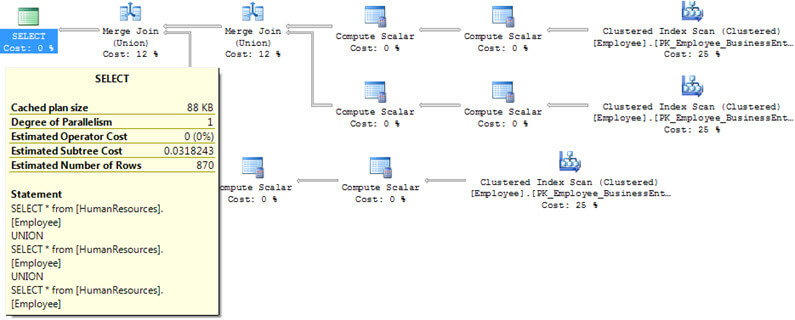
UNION vs. UNION ALL Examples With Sort on Clustered Index Column
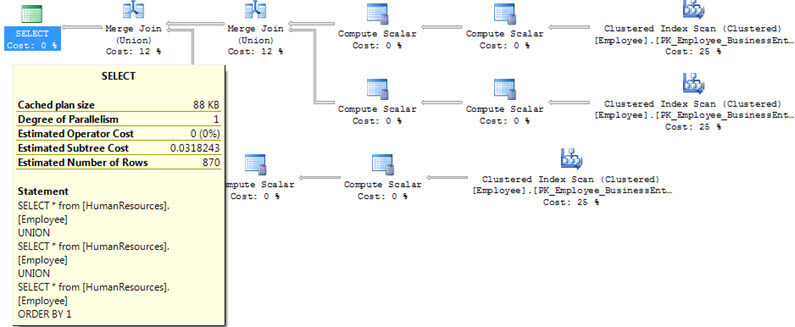
If we take this a step further and do a SORT of the data using the Clustered Index column we get these execution plans. From this we can see that the execution plan that SQL Server is using is identical for each of these operations even though the final result sets will still contain 870 rows for the UNION ALL and 290 rows for the UNION.
UNION ALL execution plan with sort on clustered index column
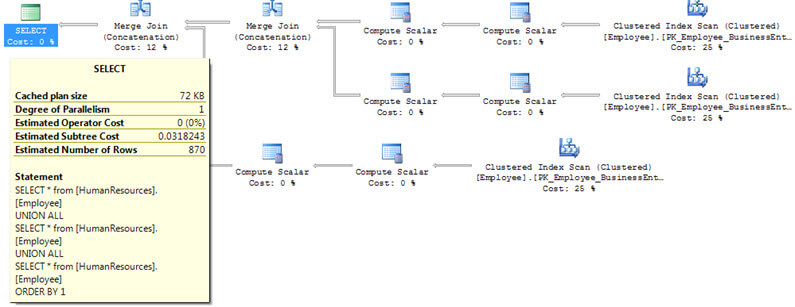
UNION execution plan with sort on clustered index column
UNION vs. UNION ALL Examples With Sort on Non-indexed Column
Here is another example doing the same thing, but this time doing a SORT on a non indexed column. As you can see the execution plans are again identical for these two queries, but this time instead of using a MERGE JOIN, a CONCATENATION and SORT operations are used.
UNION ALL execution plan with sort with a non-indexed column
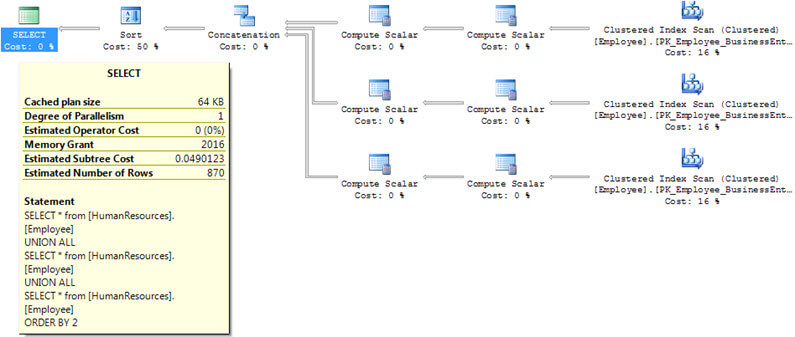
UNION execution plan with sort with a non-indexed column
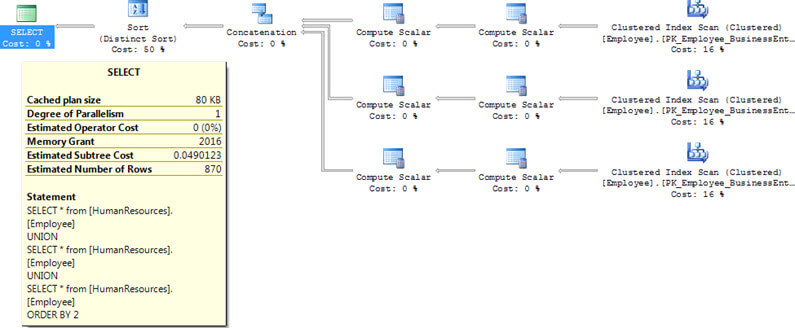
Next Steps
- Take a look at these other tips that may be useful for using the union operators






About the author
 Greg Robidoux is the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server. He is also one of the co-founders of MSSQLTips.com. Greg has been working with SQL Server since 1999, has authored numerous database-related articles, and delivered several presentations related to SQL Server. Before SQL Server, he worked on many data platforms such as DB2, Oracle, Sybase, and Informix.
Greg Robidoux is the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server. He is also one of the co-founders of MSSQLTips.com. Greg has been working with SQL Server since 1999, has authored numerous database-related articles, and delivered several presentations related to SQL Server. Before SQL Server, he worked on many data platforms such as DB2, Oracle, Sybase, and Informix.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
