By: Arshad Ali | Comments (5) | Related: 1 | 2 | 3 | 4 | > Analysis Services Performance
Problem
In the first part of this series we looked at processing performance, query performance and hardware resources for your SSAS environment. In this tip, I am going to share best practices and performance optimization techniques for source system design and network settings for your Analysis Services environment.
Solution
In Part 1 of this tip series, I talked about a typical SSAS application architecture and different components of the SSAS internal architecture. Then I talked about roles of different components and areas for performance improvement. In this tip, I am going to share with you best practices and performance optimization techniques for source system design and network settings.
Source System Design
No matter how efficient your dimensions and cube design is if your source system is not providing data fast enough processing is definitely going to take longer than expected. So you need to spend some time designing and tuning your source system for better processing performance.
Database Design
Although there are several factors you need to consider while designing databases, here are some tips for designing your relational data warehouse database:
- Keep your data files and log files on separate drives with separate spindles
- Make use of the fastest drives possible for your data and log files
- Create data files for as many processors on the machine and distribute the files equally on the different available drives
- As we normally don't take transactional backups, set the Recovery Model of the database to SIMPLE. If it is required to do transactional backups, then you can switch to BULK LOGGED recovery model before bulk data load operations and switch back to FULL recovery model after the data load. To learn more about recovery model click here.
- Design views to pull data from base tables of relational data warehouse, in which you can specify query hints or filter conditions.
- To avoid more locks or lock escalations, you can specify the TABLOCK query hint while querying or ALLOW_ROW_LOCKS = OFF and ALLOW_PAGE_LOCKS = OFF when creating tables or indexes or pull data from a read only database.
- Sometimes when you need to aggregate fact data at the source before pulling the data you could improve performance if you create indexed (materialized) views for this and instead of doing aggregations every time, pull the data from the indexed view.
- Make sure you have resources available to SQL Server for serving your data pull requests; you can use RESOURCE GOVERNOR to control the amount of resources available to OLTP and OLAP operations. To learn more about the resource governor click here.
Index Management
Believe me there are times when proper index creation/redesign reduces the query execution time from several minutes to a few seconds. For example, as you can see the two queries below, the first one selects from DimEmployee table which has a clustered index and takes only 32% of the total cost in comparison with another query from DimEmployeeHeap table, which is a heap and takes 68% of the total cost as it uses the SORT physical operator. This is a very small table with just 296 records, now consider a table with millions of records how much different this could be.
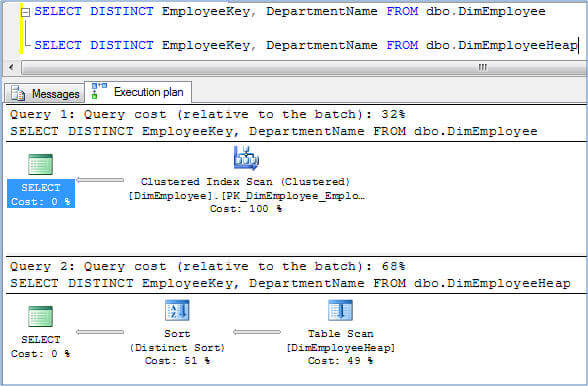
So the point is, create appropriate indexes on source tables to improve the performance of the query which SSAS fires while processing the cube or while retrieving data from the source. If you have access to the source data, you can use this DMV to identify missing indexes or you can use the Index Tuning Advisor for identifying and creating missing indexes on the source.
A word of caution, no doubt creating appropriate indexes improves the performance but creating too many indexes puts an extra overhead on SQL Server for maintaining these indexes and slows down the write/load operations. Therefore it's prudent to keep in mind "relational query performance vs extra storage/maintenance" when creating new indexes.
Often, while loading data in a relational data warehouse (if the data volume is huge), we drop indexes and recreate them after the data load. If you are following this approach, you should create indexes with FILL_FACTOR = 100, this means reading less pages and hence less I/O. If you are not following this approach, you should occasionally check the fragmentation level of the indexes and rebuild them if the level goes beyond a certain range. To learn more about checking fragmentation levels and rebuilding indexes, click here.
Table Partitioning
Partitioning allows you to decompose your huge tables into multiple manageable chunks/partitions which help improve query performance for data loading as well as for data retrieval. You should consider creating partitions, especially on fact tables, which will improve the performance several fold.
Some of the benefits of table partitioning are:
- If you have multiple partitions distributed across multiple file groups on multiple drives, then SQL Server can access it in parallel which will be faster
- You can easily switch-in and switch-out data in and out from the partitioned table
- Query performance improves as it will touch only those partitions which contain the data requested and not all the partitions or the entire table. For example, most of the time you will be accessing only the most recent data...
- Data load performance also improves as it loads data to one partition (generally in the most recent partition) or a few partitions vs. all the partitions or the entire table.
You can refer to these articles for more in depth information about table partitioning, strategies and its benefits:
- Partitioned Tables and Indexes in SQL Server 2005
- Strategies for Partitioning Relational Data Warehouses in Microsoft SQL Server
Data Compression
As we all know I/O (Input/Output) is the slowest part of the hardware resources. If I/O is a bottleneck on your source system, you should consider using Data Compression which reduces I/O, but increases CPU cycles a bit (more CPU cycles are used for data compression and decompression). SQL Server 2008 and later versions support both row and page compression for both tables and indexes. Before you decide to enable compression on a table you can use the sp_estimate_data_compression_savings system stored procedure to understand how much space savings you will get. To learn more about Data Compression click here.
Minimize Locking Overhead
When we select data from a table, shared locks are placed on row/key levels. This row/key level locking escalates to page level or table level depending on the amount of rows that are selected. To minimize the amount of effort by SQL Server to manage these locks you can specify the NOLOCK or TABLOCK query hint in the query.
Network Settings
I am not a network specialist, so I cannot talk much about this topic but you should work with your hardware vendor/team to ensure you are using the fastest network possible.
Connecting to Source System
There are a couple of things you need to be aware of when connecting to source systems using data sources in an SSAS project:
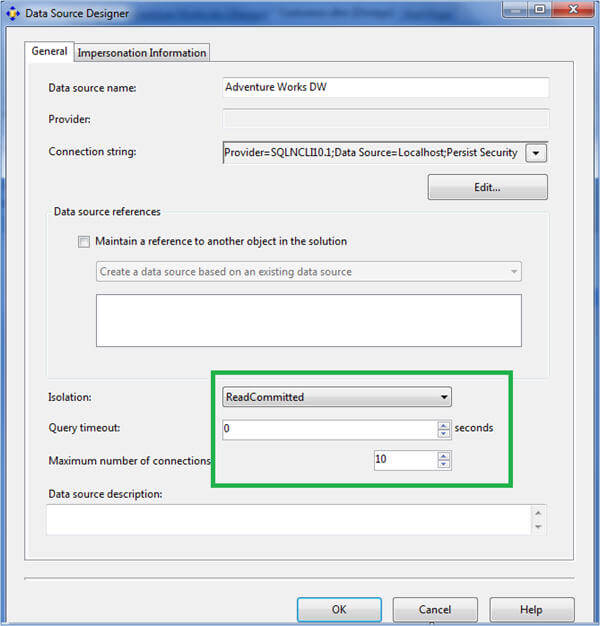
- Isolation - Sometimes when your source system is continuously changing and you want consistent data, you might need to pull data in using Snapshot isolation mode which in turns uses a version store in SQL Server. In other scenarios, use the default ReadCommitted isolation mode in order to avoid extra overhead/copies at the source system.
- Query timeout - With this property you can specify the query timeout for queries being run against the source system. If you have huge source tables with inadequate indexes or out of date statistics, your query is going to take longer, so make sure you specify the value which is appropriate or specify 0 for unlimited timeout.
- Number of connections - With this you can specify the maximum number of connections that SSAS can create in parallel to pull data from source systems during cube processing. This really helps in cube processing to run in parallel by creating multiple connections to refresh several dimensions and facts in parallel. The default value for this is 10 and you should consider increasing this if you have a cube with lots of dimensions/facts and your source supports more parallel connections. This will greatly improve the cube processing times.
- Impersonation - This allows you to specify the credentials which will be used for connecting and pulling data from source systems.
Shared Memory
If your source system (SQL Server) and SSAS are both on the same machine, you should consider using the Shared Memory net library for better performance. The performance benefit comes from the fact that it bypasses the physical network stack. It uses the Windows Shared Memory feature to communicate between SQL Server and the client/SSAS. This Net-Library is enabled by default and used when you specify either a period or (local) as your machine name or localhost or machine name or by prefixing machine\instance name with lpc: when connecting to a SQL Server instance. To learn more this click here.
Network/TDS Packet Size
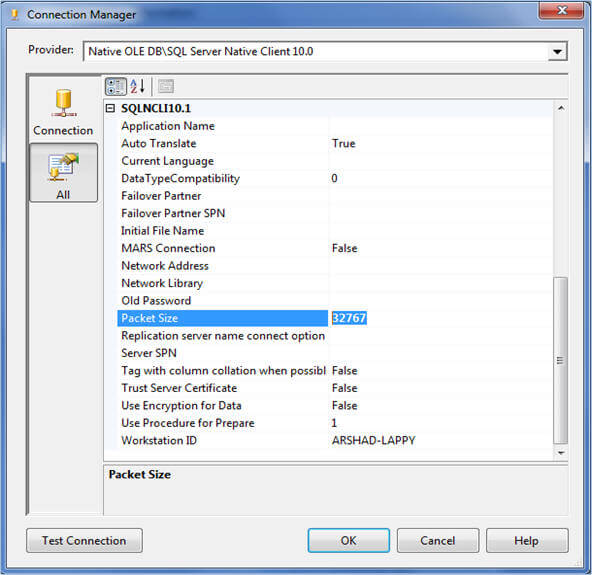
During cube processing data moves from your relational data warehouse to SSAS in TDS (Tabular Data Stream) packets. As data movement between the relational data warehouse and SSAS is normally high, we should configure this to have a bigger packet size (therefore less packets) than using a smaller size (high number of packets) to minimize the overhead of breaking data down into multiple chunks/packets and reassembling it at other end. To change the packet size you can go to connection manager, click on the All page on the left side and specify 32KB for the packet size property instead of its default value of 4KB as shown below. Please note, changing the network packet size property might be good for data warehousing scenario but not for OLTP type applications and therefore it's better to override the packet size property for your connection separately instead of changing it on SQL Server for all connections.
Next Steps
- Stay tuned for the next tip in the series.
- Review Analysis Services Performance Guide whitepaper.
- Review Analysis Services Operations Guide whitepaper.
- Review SQL Server Integration Services SSIS Best Practices tips.
- Read Part 1 of this series






About the author
 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
