By: Arshad Ali | Comments (2) | Related: 1 | 2 | 3 | 4 | > Data Quality Services
Problem
The amount of data is increasing on a regular basis and so is the responsibility to ensure the quality of data remains intact. Data quality issues consist of inconsistency, incompleteness, invalidity, inaccuracy, duplicates, etc. These data quality issues can arise from different sources like erroneous data entry, corruption in transmission or storage, data consolidation issues from different sources with different standards or formats, etc. These types of issues can lead to incorrect data analysis, data mining and reporting, which ultimately impacts the business. I have heard that SQL Server 2012 has a brand new feature called Data Quality Service (DQS) which greatly helps to ensure the data integrity and quality by data profiling, matching, cleansing, correcting data and monitoring overall status of the processes. Let's explore this feature in this tip series.
Solution
Data Quality Services (DQS) in SQL Server 2012 is new feature used for improving and maintaining the quality of your data across enterprise. But before we start digging more details of DQS, let's first understand some of the Data Quality Challenges:
- Incompleteness - Is the data value complete to have the proper meaning?
- Inconsistency - Is data value consistent throughout your organization?
- Invalid - Do the data values fall within the defined domain?
- Inaccuracy - Is your data value accurate?
- Non-conformity - Does the data value conform to the specific standard/representation or format?
- Duplicity - Is your data value is duplicated?
Now what are some of the causes of these data quality issues:
- Incorrect data entry by the entry operator or by some system.
- When consolidating or aggregating data from different sources and all these sources have different standard/representation and format defined. For example, one source might be having M, F and U values for Gender whereas other would be having value like 0, 1 and 2.
- Data gets corrupted during transmission or storage or by any other means.
- When sources are not using Master Data Services for consistent master data definitions across all the business operations then these sources have a different definition of the master data which causes inconsistencies when consolidating.
Understanding SQL Server Data Quality Services (DQS)
Now coming back to DQS, DQS is a new feature in SQL Server 2012 which provides data quality solutions to the data steward (someone who ensures data quality and makes the data useful for the business) or IT Professionals. DQS is knowledge based solution that provides both interactive or automated/batch mode approaches to manage the integrity and quality of the data. Here are a couple of the DQS features:
- Knowledge based - You can create a reusable Data Quality Knowledge Base (DQKB) which can be used to improve the integrity and quality of the data.
- Semantics - Data is mapped into data domains, which you create and can capture semantics.
- Knowledge Discovery - DQS can acquire additional knowledge from sample data and/or from user feedback.
- Open and Extensible - Not only you can use the your own knowledge base, but you can use third party reference data providers which ensures the quality of your data by comparing it to the data guaranteed by a third-party company. Integration with SSIS is possible for automated match mode execution.
- Easy to use - An intuitive and compelling user experience designed for increased productivity.
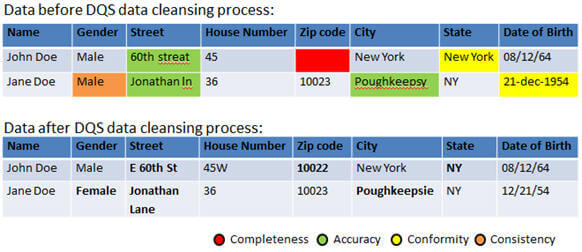
What are the different SQL Server DQS processes?
As I said, DQS is a knowledge based tool that allows us to create a knowledge base about the data and then it uses the data in the knowledge base to improve the integrity and quality of the data. DQS also supports using reference data from Windows Azure Marketplace to enable reference data providers to provide reference data services through the Marketplace. Here are some of the operations that DQS performs or allows us to perform:
- Monitoring - It allows to track and monitor the state of data quality activities and quality of data; this way you can monitor DQS activities and its progress.
- Profiling - It does the analysis of the data source to provide insight into the quality of the data and helps to identify data quality issues at every stage in knowledge discovery, domain management, matching and data cleansing processes.
- Cleansing - It can be performed interactively via the DQS Client tool or in batch mode via use of an SSIS component. It updates, amends, removes or enriches data that is incorrect or incomplete. This includes correction, standardization and enrichment. The cleansing process classifies the data to different categories as follows:
- Correct - Terms/data values that were found correct; for instance, matched a domain value or returned from the RDS (Reference Data Service) as ‘correct'.
- Corrected - Terms/data values that were automatically corrected by the DQS engine by using the knowledge base that it uses or the RDS (Reference Data Service) provider.
- Not Corrected - Terms/data values that were not recognized by the system as ‘correct' or terms/ data values that violate a domain rule.
- Auto suggested - Terms/data values that the DQS engine has found a correction for, but with medium or low confidence and require user intervention to move ahead (Approve/Reject).
- New - Terms/data values that the DQS engine has identified as new values at the data source (Approve/Reject).
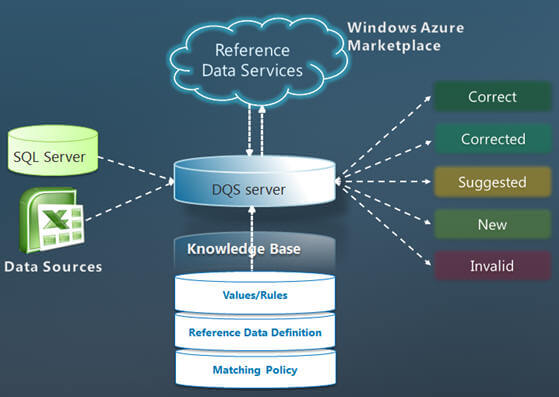
- Matching - Identifying, linking or merging related entries within or across sets of data. The goal of matching is to remove duplicates from the source. It can be done intra-source (matching a source against itself) or inter-source (matching a source against a lookup table). A matching process includes four steps:
- Matching Policy Training - To define and test the set of policy rules that govern the matching process. The matching policy rules help identifying the relevant duplicates.
- Matching - To run a matching project by matching the data at source against itself or against a lookup table.
- Auto-Approve - To define policy rules for auto-approving matching result clusters based on the match results obtained.
- Merge/Survivorship - To define the policy rules for selecting one approved record from each cluster of matched records.

Source - Combination of Gadi Peleg's presentation available here and from Elad Ziklik's presentation available here.
In this tip, we outlined the data quality challenges and its source, then I talked about Data Quality Service of SQL Server 2012 and its processes. In the next tip of this series I am going to talk about different components of DQS and how to go about installing and configuring DQS and then I will talk how DQS works.
Please note, details and example of Data Quality Services in the tip series is based on SQL Server 2012 CTP 3 release, there might be some changes in final release of the product; though RC0 release is already out and here are some of the new features and improvements.
Next Steps
- Review Introducing Data Quality Services article on MSDN.
- Review Data Quality Services "How Do I?" Videos on MSDN.
- Review SQL Server 2012 related tips
- Review all my previous tips.






About the author
 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
