By: Susantha Bathige | Comments (3) | Related: > TSQL
Problem
Recently I saw a forum question about a T-SQL query which seems to be really simple, but I found some people were finding it difficult to answer. That is because I believe they do not understand the declarative nature of the SQL language. In this article I'm trying to explain the declarative nature of SQL by using the same example I saw in the forum. This is not a complete post which describes the SQL language. Please see below for the question.
Consider the below table structure:
CREATE TABLE Temp(document_name varchar(50), importyear int)
INSERT INTO Temp VALUES ('A',2013)
INSERT INTO Temp VALUES ('A',2014)
INSERT INTO Temp VALUES ('A',2015)
INSERT INTO Temp VALUES ('B',2013)
INSERT INTO Temp VALUES ('C',2014)
The question was: "I want to list all the documents imported in 2013 only. My query should only pull out document_name B and should not pull out A since it was imported in 2014 and 2015 too".
Solution
Let's discuss about how to evaluate the answer for the
above question. Let me remind you that the basic concept of the SQL language is a
declarative language meaning, it is non-procedural. This means you need to
specify what needs to be done rather than how to do it. Further,
SQL operates as sets or relations, so we should not think it as row basis rather
a set of rows. This is the reason SQL has relational operators and set
operators to manipulate relational data.
Relational and Set operators
E.F Codd originally proposed 8 operations on tables/relations. There are 3 original set operators and 5 relational operators available for SQL.
Set operators
Union, Intersection, Difference
Relational operators
Projection, Selection, Cartesian Product, Join, Division
We use some of these operators on a daily basis. They are Projection, Selection, Union and Join. They are the most widely used relational and set operators in SQL. Without Projection and Selection basically you can not do anything with the relational databases with regard to data manipulation. For the question listed above, we can simply use the set operator, Difference but the same result can be achieved using the Join relational operator too. I'm going to discuss several other options as well in this post.
Explaining all those relational operators is beyond the limit of this post.
Getting the data we need
Let's retrieve the records from the Temp table to get familiar with the data set.
SELECT * FROM Temp
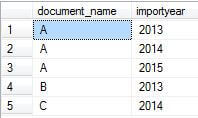
You will notice that different documents belong to different years. For example, document A belongs to years 2013, 2014 and 2015. So when we select documents belonging to only 2013, document A should not appear in the result set.
Query_A
Let's retrieve the documents belong to 2013. That is fairly a simple query.
SELECT * FROM Temp WHERE importyear=2013
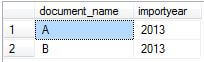
You can see documents A and B appear in the result.
However we do not want to display the documents which appeared for years other than 2013. For example, document A should not appear in the result because it is also in 2014 and 2015. How do we eliminate these rows from the result set?
Query_B
Let's get the documents which do not belong to 2013. This is also a trivial query.
SELECT * FROM Temp WHERE importyear<>2013
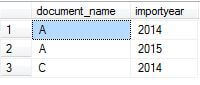
Now we have two result sets, the output of Query_A and Query_B. You can consider these two results sets as two relations, meaning derived relations for intermediate results.
Now let's try to build the final answer based on the two results of the above two queries. If we can get the documents which appear only in the result of Query A and not in the result of Query B, then we can solve the problem. So it is something like the below:
(SELECT Document_Name FROM Query_A) WHERE Document_Name DOES NOT EXISTS IN (SELECT Document_Name FROM Query_B)
Next question is, how to convert the above pseudo code to actual T-SQL. We already know the implementation for Query A and Query B, so we need to figure out what goes in the middle. There are a couple of ways this can be done.
Solution 1
Using Except:
(SELECT Document_Name FROM Temp WHERE importyear=2013) EXCEPT (SELECT Document_Name FROM Temp WHERE importyear<>2013)
There you go! The output is document B only which is the exact result we want. Now, we will look at some other alternatives to achieve the same result.
Solution 2
You can achieve the same result using a JOIN operator.
SELECT t1.document_name FROM Temp t1 LEFT JOIN (SELECT document_name FROM Temp t2 WHERE importyear<>2013) t2 ON t1.document_name=t2.document_name WHERE importyear=2013 AND t2.document_name IS NULL
Solution 3
Same result using the EXISTS operator. It specifies a subquery to test the existence of rows. In this case we want to use the negation of the EXISTS with a NOT EXISTS.
SELECT document_name FROM temp t WHERE importyear=2013 AND NOT EXISTS (SELECT document_name FROM temp WHERE importyear<>2013 AND document_name=t.document_name)
Solution 4
Same result using the IN operator. It determines whether a specified values matches any values in the subquery or a list. In this case it is subquery using NOT IN.
SELECT document_name FROM Temp t1 WHERE importyear=2013 AND document_name NOT IN (SELECT document_name FROM Temp WHERE importyear<>2013)
Solution 5
Here is another option using NOT IN.
SELECT document_name FROM Temp WHERE document_name NOT IN (SELECT document_name FROM Temp WHERE importyear<>2013)
So we have 5 different solutions for the same query.
Performance Comparison
In programming, our objective is to find the optimal query which consumes less server resources such as IO, CPU, Network and Memory. Lets compare the performance matrices of each solution and decide which one would be the best. Just for clarity, I copied the query of each solution just before the Execution Plan.
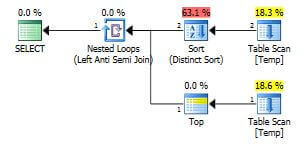
Execution Plan - Solution 1 - (Query 1)
SELECT document_name FROM Temp WHERE importyear=2013 EXCEPT SELECT document_name FROM Temp WHERE importyear<>2013
Execution Plan - Solution 2 - (Query 2)
SELECT t1.document_name FROM Temp t1 LEFT JOIN (SELECT document_name FROM Temp t2 WHERE importyear<>2013) t2 ON t1.document_name=t2.document_name WHERE importyear=2013 AND t2.document_name IS NULL
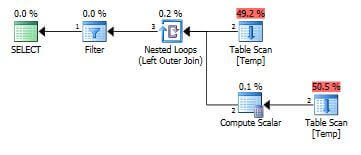
Execution Plan - Solution 3 - (Query 3)
SELECT document_name FROM temp t WHERE importyear=2013 AND NOT EXISTS (SELECT document_name FROM temp WHERE importyear<>2013 AND document_name=t.document_name)
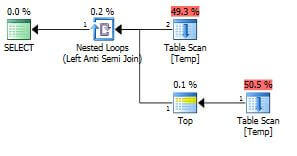
Execution Plan - Solution 4 - (Query 4)
SELECT document_name FROM Temp t1 WHERE importyear=2013 AND document_name NOT IN (SELECT document_name FROM Temp WHERE importyear<>2013)
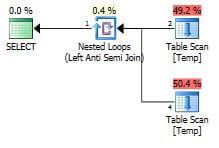
Execution Plan - Solution 5 - (Query 5)
SELECT document_name FROM Temp WHERE document_name NOT IN (SELECT document_name FROM Temp WHERE importyear<>2013)
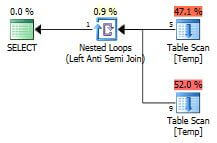
It is worth to see IO and CPU time statistics for the preceding queries. However you can do further homework by creating a load in the table and then observe the IO and CPU figures.
Below table states Estimated Cost comparison for each of the preceding execution plans:
| Statement | Est Cost | Est CPU Cost | Est IO Cost | Est Rows | Actual Rows | Sort Operations | Table Scan |
|---|---|---|---|---|---|---|---|
| Query 1 | 40.0% | 20.1% | 41.0% | 1 | 1 | 1 | 2 |
| Query 2 | 14.8% | 16.6% | 14.8% | 1 | 1 | 0 | 2 |
| Query 3 | 14.8% | 16.4% | 14.7% | 1 | 1 | 0 | 2 |
| Query 4 | 14.8% | 16.8% | 14.8% | 2 | 1 | 0 | 2 |
| Query 5 | 15.5% | 30.2% | 14.8% | 5 | 1 | 0 | 2 |
Comparing the estimated cost is sometimes meaningless, because the estimated cost is used internally to select the optimal plan and in the real world it has no meaning. As per the table, Query 2, 3 and 4 seem to be the best solutions. The highest cost is for Query 1 and that is because of the Sort Operator used in the plan.
Summary
Thinking and imagining as a set of rows or sets is really important when working with SQL. Then you can work on complex solutions to get the correct results. It takes some time and practice to get more knowledgeable about SQL.
Next Steps
- Read more about writing basic queries






About the author
 Susantha Bathige currently works at Pearson North America as a Production DBA. He has over ten years of experience in SQL Server as a Database Engineer, Developer, Analyst and Production DBA.
Susantha Bathige currently works at Pearson North America as a Production DBA. He has over ten years of experience in SQL Server as a Database Engineer, Developer, Analyst and Production DBA.
This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
