By: Tim Wiseman | Comments | Related: > Application Development
Problem
When accessing a SQL Server database from within a programming environment, some tools allow the option of retrieving the results of a query one row at a time or fetching all rows at once. When is each option a better choice?
Solution
When querying a SQL Server database, many programming environments allow the programmer to select whether they want to retrieve the result sets one row at a time, or to retrieve all of the rows at once. In most cases, especially if the program will iterate over the rows or the number of rows to be retrieved is unknown, it is far better to retrieve the rows one at a time. This option is generally faster (we will look at some examples below) and may allow the program to avoid retrieving all of the rows or else release some of them once they are processed. However, there are occasions especially when dealing with a small number of rows, where it can be more efficient to retrieve all of the rows at once.
A Brief Example in PowerShell
PowerShell is a powerful scripting language that can be used for numerous purposes. It has access to ADO.NET and other tools for interacting with SQL server. Using ADO.NET gives the programmer the option of how they would like the rows returned. A programmer can either return results one row at a time with a DataReader or they can call all of the rows at once using a DataTable populated by SQLDataAdapter.
An simple example of using a DataReader to pull in the rows one at a time using PowerShell might look like this:
$connStr = "server=YOURSERVER;integrated security=sspi;database=Test"
$watch = [system.diagnostics.stopwatch]::StartNew()
$conn = new-object System.Data.SqlClient.SqlConnection($connStr)
$conn.open()
$sql = "select top 1000 * from dbo.IntTbl"
$cmd = new-object "System.Data.SqlClient.SqlCommand" ($sql, $conn)
$results = $cmd.ExecuteReader()
while ($results.read()) {
$val1 = $results.GetValue(0)
$val2 = $results.GetValue(1)
$val3 = $results.GetValue(2)
}
write-Host $val1, $val2, $val3
Write-Host $watch.Elapsed.Hours : $watch.Elapsed.Minutes : $watch.Elapsed.Seconds : $watch.Elapsed.Milliseconds
$results.close()
$conn.close()
And using a SQLDataAdapter to pull in the rows all at once and populate a DataTable object looks like this:
$connStr = "server=YOURSERVER;integrated security=sspi;database=Test"
$watch = [system.diagnostics.stopwatch]::StartNew()
$conn = new-object System.Data.SqlClient.SqlConnection($connStr)
$conn.open()
$dataset = new-object "System.Data.Dataset" "test"
$sql = "select top 1000 * from dbo.IntTbl"
$dataadapter = new-object "System.Data.SqlClient.SqlDataAdapter" ($sql, $conn)
$dataadapter.Fill($dataset)
foreach ($row in $dataset.tables["IntTbl"].rows) {
$val1 = $row.col1
$val2 = $row.col2
$val3 = $row.col3
}
write-Host $val1, $val2, $val3
Write-Host $watch.Elapsed.Hours : $watch.Elapsed.Minutes : $watch.Elapsed.Seconds : $watch.Elapsed.Milliseconds
$conn.close()
In both of these examples, which do essentially the same thing with different techniques, I used the stopwatch to get a sense for how long they were taking. The version that retrieved all rows was generally faster, though the times varied, sometimes substantially, each time I repeated it. However, one test tells you very little, so it would be helpful to take a look at it a different way. I turned to Python to run additional tests.
Examples in Python
There are several methods of using Python to interact with SQL Server. Generally, I use pyodbc which is primarily maintained by Michael Kleehammer. After pyodbc executes a query, the results can be returned individually by calling fetchone or they can be returned all at once by calling fetchall. The cursor object itself can also be treated as an iterator and used directly in Python for loops and other constructs. When used this way, it retrieves the rows as it is called. Pyodbc also provides a fetchmany option to retrieve the rows in batches of a controlled size.
I set up some comparisons between retrieving the rows one by one and retrieving them all at once. I used timeit it to time each test, and set it to repeat each test over a thousand times, returning only the shortest time for each variation to try to minimize the impact of background process or other vagaries such as the location of the disk heads. It was also set to clear the SQL cache between each time test using DropCleanBuffers.
I should note that these tests have been highly variable, with the details of the results changing with each repetition, sometimes quite substantially and occasionally reversing the trend I would expect. These graphs should thus be taken as less than definitive. However, the general trend has been that for relatively small numbers of rows, returning all of them has been slightly faster. It also has the advantage of ending the connection sooner and freeing up the cursor. When dealing with rather large numbers of rows, returning them one by one has generally been faster and may consume less memory.
For a simple example, I wrote two short functions that simply places all the values into a list, retrieving them either one by one or all at once. I timed it with different top values that limited the number of rows returned. The functions look like this:
def putIntoList_OBO(curs, topX):
sql = 'select top ' + str(topX) + ' * from dbo.IntTbl'
curs.execute(sql)
NewList = []
for row in curs:
NewList.append(row[0])
return NewList
def putIntoList_All(curs, topX):
sql = 'select top ' + str(topX) + ' * from dbo.IntTbl'
curs.execute(sql)
NewList = []
for row in curs.fetchall():
NewList.append(row[0])
return NewList
The timing results for various numbers of rows returned (note that the graphs use different scales). OBO is row by row retrieval and ALL returned all records at once.
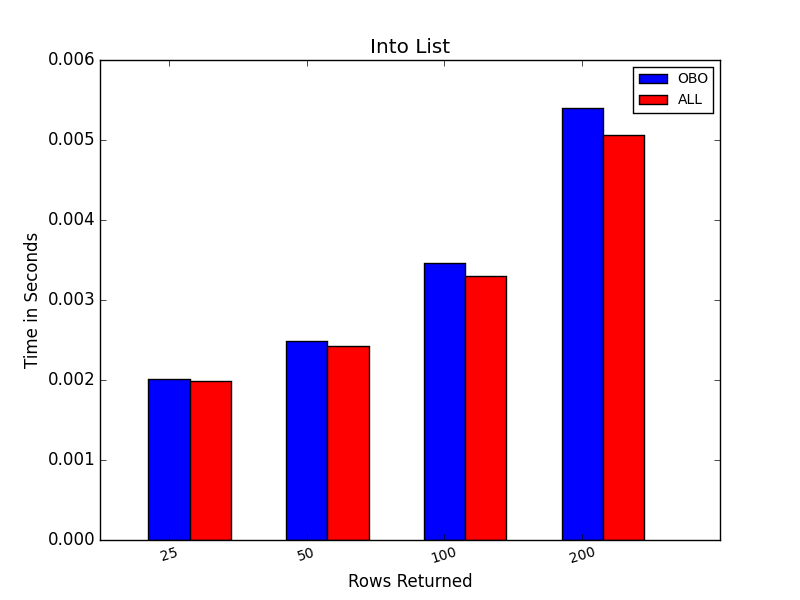
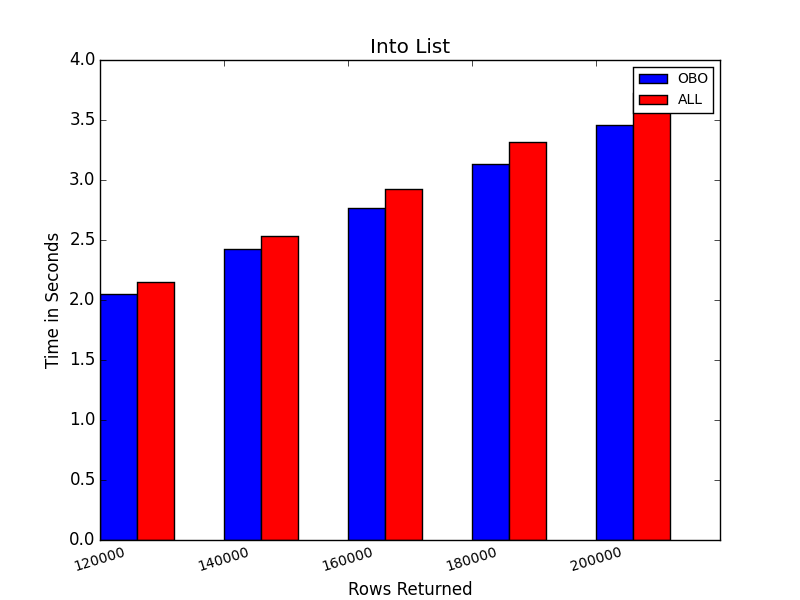
Of course, one significant advantage of retrieving the rows one by one is that you never have to retrieve all of the rows available if they are unnecessary. Ideally, you would construct the query to only return precisely the rows that you need, but that may be difficult at times. You may, for instance, be responding to a user's request, and they may decide they are finished long before all rows are processed so that the program can stop requesting the rows. For an example, here are short procedures that stop processing the rows at an arbitrary cutoff.
def putIntoList_OBO_Use100(curs, topX):
sql = 'select top ' + str(topX) + ' * from dbo.IntTbl'
curs.execute(sql)
NewList = []
for x in range(100):
row = curs.fetchone()
NewList.append(row[0])
return NewList
def putIntoList_All_Use100(curs, topX):
sql = 'select top ' + str(topX) + ' * from dbo.IntTbl'
curs.execute(sql)
NewList = []
values = curs.fetchall()
for x in range(100):
NewList.append(values[x][0])
return NewList
Here, the one-by-one versions runs substantially faster than the version that retrieves all of the rows.
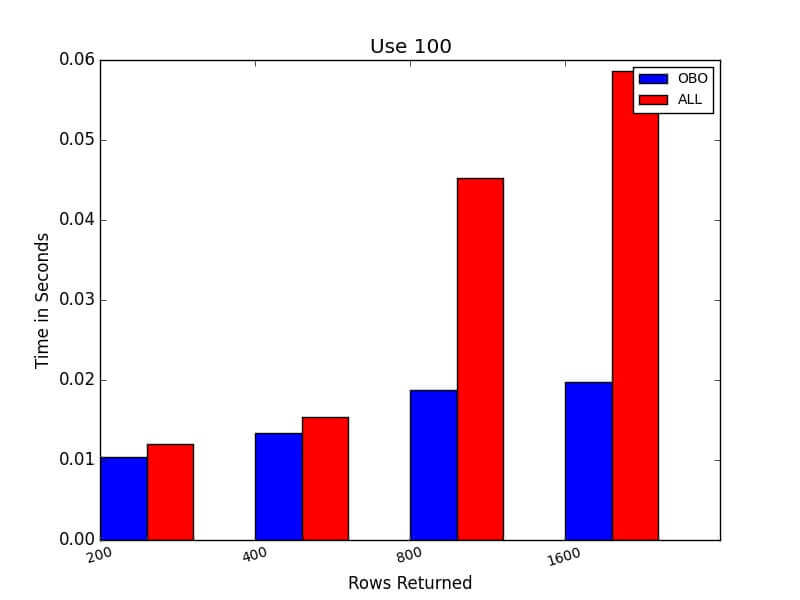
Conclusions
There are advantages to both retrieving all of the rows at once or pulling them into the program one by one as they are needed. Requesting all of the rows at once can allow the query to be fully ended sooner and may provide a performance advantage under some circumstances, especially with a small result set. At other times, processing the rows one by one can lead to a performance advantage in other cases and may allow for many rows to be skipped if it can be determined during execution that they are not needed. Ideally, which technique to use should be determined on a case by case basis taking into account all factors. However, if a rule of thumb is useful, I believe that it is more often a better choice to pull all the rows over one by one.
Next Steps
- MSSQLTips has more PowerShell Tips.
- MSSQLTips has more Performance Tips.






About the author
 Tim Wiseman is a SQL Server DBA and Python Developer in Las Vegas.
Tim Wiseman is a SQL Server DBA and Python Developer in Las Vegas.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
