By: Tim Smith | Comments | Related: > PowerShell
Problem
We recently added a data source that provides thousands of columns per data values. Many of these columns have countless nulls, which reduces our ability to use the specific columns for our analysis. Since we have a baseline of how many values within a column must have non-null values in order for us to use for analysis, is there a way to determine how many columns have too many null values for analysis automatically, so that we can remove these values in our ETL flow as early as possible?
Solution
In order to create a useful function to do this, we want to work backwards. We'll create a table with a thousand columns allowing for NULL values in all our columns. Next, we'll populate a data point in each row in only one column of our created table. The below PowerShell script is run in two batches: the first batch creates the table and the second batch populates a thousand data values.
Function Execute-Sql {
Param(
[Parameter(Mandatory=$true)][string]$server
, [Parameter(Mandatory=$true)][string]$database
, [Parameter(Mandatory=$true)][string]$command
)
Process
{
$scon = New-Object System.Data.SqlClient.SqlConnection
$scon.ConnectionString = "Data Source=$server;Initial Catalog=$database;Integrated Security=true"
$cmd = New-Object System.Data.SqlClient.SqlCommand
$cmd.Connection = $scon
$cmd.CommandTimeout = 0
$cmd.CommandText = $command
try
{
$scon.Open()
$cmd.ExecuteNonQuery()
}
catch [Exception]
{
Write-Warning $_.Exception.Message
}
finally
{
$scon.Dispose()
$cmd.Dispose()
}
}
}
### Execute in batch 1
$start = 1
$columnlist = "CREATE TABLE tbManyColumns ("
while ($start -le 1000)
{
if ($start -lt 1000) { $columnlist += "column$start VARCHAR(1) NULL, " }
else { $columnlist += "column$start VARCHAR(1) NULL)" }
$start++
}
Execute-Sql -server "OurServer" -database "OurDatabase" -command $columnlist
### Execute in batch 2
$start = 1
while ($start -le 1000)
{
$insertnonnull = "INSERT INTO tbManyColumns (column$start) VALUES ('a')"
Execute-Sql -server "OurServer" -database "OurDatabase" -command $insertnonnull
$start++
}
Then we run a few queries in Management Studio against the database to test that the creation happened as expected.
SELECT TOP 1 * FROM tbManyColumns SELECT COUNT(*) CountoftbManyColumns FROM tbManyColumns SELECT TOP 4 column1 , column2 , column3 , column4 FROM tbManyColumns
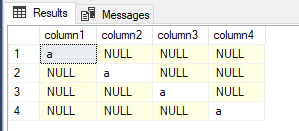
Since we know what we populated in the above PowerShell code, we know that 1 out of 1000 records per column is not null. We get this by taking the number of non-null values (1) and dividing it by the total values (1000). We'll use this table for our example, though we'll create a function in PowerShell that we can use with any table. We will want to be able to retain this information in a table so that we can quickly query it.
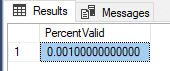
SELECT (SELECT COUNT(*) FROM tbManyColumns WHERE column1 IS NOT NULL)/CAST(COUNT(*) AS DECIMAL(13,6)) PercentValid FROM tbManyColumns CREATE TABLE tbColumnReview( ColumnName VARCHAR(100), PercentValid DECIMAL(15,7) )
For our next steps, we want to execute multiple steps in PowerShell:
- We need to loop over every column in the table and obtain the name. In our example table, we have 1000 columns.
- We will then query the amount of non-null records to total records in the table and keep this result in a decimal.
- We then will save the column and result information to our table we created in the above code, called tbColumnReview.
We'll use a derivative of the Read-Configuration script for our reader, which obtains a result from a query and saves it either to a variable, or in our case, can be saved to a string command. We'll also use the SQL Management Objects (SMO) library for iterating over the columns in a table, as this will combine with our reader faster. An alternative is to have a reader reading from INFORMATION_SCHEMA.COLUMNS; however, when I want to iterate over SQL objects, like tables, columns, views, etc., I generally prefer the SMO library. As the script loops over each column, it gets the name, queries the non-null records to total records, and saves this information (using Execute-Sql) to our table.
Function Execute-Sql {
Param(
[Parameter(Mandatory=$true)][string]$server
, [Parameter(Mandatory=$true)][string]$database
, [Parameter(Mandatory=$true)][string]$command
)
Process
{
$scon = New-Object System.Data.SqlClient.SqlConnection
$scon.ConnectionString = "Data Source=$server;Initial Catalog=$database;Integrated Security=true"
$cmd = New-Object System.Data.SqlClient.SqlCommand
$cmd.Connection = $scon
$cmd.CommandTimeout = 0
$cmd.CommandText = $command
try
{
$scon.Open()
$cmd.ExecuteNonQuery() | Out-Null
}
catch [Exception]
{
Write-Warning $_.Exception.Message
}
finally
{
$scon.Dispose()
$cmd.Dispose()
}
}
}
Function Save-Results {
Param(
[Parameter(Mandatory=$true)][string]$server
, [Parameter(Mandatory=$true)][string]$database
, [Parameter(Mandatory=$true)][string]$table
, [ValidateSet("2008R2","2012","2014","2016","2017")][string]$version
)
Process
{
switch ($version)
{
"2008R2" {
Write-Host "Adding libraries for version $version"
Add-Type -Path "C:\Program Files (x86)\Microsoft SQL Server\100\SDK\Assemblies\Microsoft.SqlServer.Smo.dll"
}
"2012" {
Write-Host "Adding libraries for version $version"
Add-Type -Path "C:\Program Files (x86)\Microsoft SQL Server\110\SDK\Assemblies\Microsoft.SqlServer.Smo.dll"
}
"2014" {
Write-Host "Adding libraries for version $version"
Add-Type -Path "C:\Program Files (x86)\Microsoft SQL Server\120\SDK\Assemblies\Microsoft.SqlServer.Smo.dll"
}
"2016" {
Write-Host "Adding libraries for version $version"
Add-Type -Path "C:\Program Files (x86)\Microsoft SQL Server\130\SDK\Assemblies\Microsoft.SqlServer.Smo.dll"
}
"2017" {
Write-Host "Adding libraries for version $version"
Add-Type -Path "C:\Program Files (x86)\Microsoft SQL Server\140\SDK\Assemblies\Microsoft.SqlServer.Smo.dll"
}
}
$sqlsrv = New-Object Microsoft.SqlServer.Management.SMO.Server($server)
foreach ($column in $sqlsrv.Databases["$database"].Tables["$table"].Columns)
{
$scon = New-Object System.Data.SqlClient.SqlConnection
$scon.ConnectionString = "Data Source=$server;Initial Catalog=$database;Integrated Security=true;"
$cmd = New-Object System.Data.SqlClient.SqlCommand
$cmd.Connection = $scon
$cmd.CommandText = "SELECT (SELECT COUNT(*) FROM $table WHERE " + $column.Name + " IS NOT NULL)/CAST(COUNT(*) AS DECIMAL(13,6)) PercentValid FROM $table"
try
{
$scon.Open()
$sqlread = $cmd.ExecuteReader()
while ($sqlread.Read())
{
$command = "INSERT INTO tbColumnReview (ColumnName,PercentValid) VALUES ('" + $column.Name + "'," + $sqlread["PercentValid"] + ")"
Execute-Sql -server $server -database $database -command $command
}
}
catch [Exception]
{
Write-Warning "Save-Results ($server.$database)"
Write-Warning $_.Exception.Message
}
finally
{
$sqlread.Close()
$scon.Dispose()
$cmd.Dispose()
}
}
}
}
Save-Results -server "OurServer" -database "OurDatabase" -table "tbManyColumns" -version 2017
The result from our initial example:
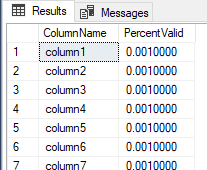
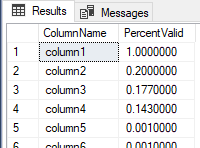
Now, we'll change four columns by updating all or some of the values to non-nulls. In the below step, we first truncate our tbColumnReview, as we'll be calling our PowerShell script again. Then we update column1 to every value being not null with a value of a. For columns column2, column3, and column4, we update a percent of them to not null values by using a CTE to do a partial table update. We then run our PowerShell script and look at our analysis table and see that the first four columns all have more not null values than 0.001.
TRUNCATE TABLE tbColumnReview UPDATE tbManyColumns SET column1 = 'a' ;WITH GetSome AS( SELECT TOP 200 column2 FROM tbManyColumns ) UPDATE GetSome SET column2 = 'b' ;WITH GetSomeAgain AS( SELECT TOP 177 column3 FROM tbManyColumns ) UPDATE GetSomeAgain SET column3 = 'z' ;WITH GetSome3 AS( SELECT TOP 143 column4 FROM tbManyColumns ) UPDATE GetSome3 SET column4 = 'w' ---- First run our PowerShell script SELECT * FROM tbColumnReview
If we determine that a column of data may not be meaningful for our analysis and that it has very few actual values compared to NULL values, we may decide to exclude it from our ETL flow. The situation will differ, as I've seen some data, like comments or text, which added no value and came with many NULLs in some data sets, while in other data sets, the exact same type of comments or text values offered significant value for analysis. Since the amount of NULLs as a portion of the overall data set may impact our decision, it's helpful to have a tool that allows us to get this information quickly.
Next Steps
- Both T-SQL or PowerShell will function to get this information quickly so that we can decide whether we want to leave out some columns if they show to have a very tiny percent of actual values compared to NULL values and the values in question may not be meaningful.
- If these data come on a schedule, such as a daily delivery of data, rather than remove columns early, I suggest tracking how often we get NULLs for some values, as it could be one or two batches of data that have missing values. Over time, we'll be able to quickly determine what's abnormal or normal.
- With frequent NULL values that may be text (like comments), during our ETL process we may move these data to a separate table, removing the NULL values by selecting only the non-NULL values and retaining the valid data with an identity that can be tracked by to our main, dimension or fact table.






About the author
 Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.
Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
