By: Koen Verbeeck | Comments (3) | Related: 1 | 2 | 3 | 4 | More > Integration Services Development
Problem
In the previous two parts of this tip, an implementation of a SQL Server slowly changing dimension of type 2 was suggested. This design only uses out-of-the-box components and is optimized for performance. It doesn’t use the SCD Wizard. However, the initial design can be optimized even further. In this part, we’ll go over these optimizations.
Solution
Before you read this tip, it is advised to read part 1 and part 2 if you haven’t already.
There are three optimizations possible in the design:
- Detect type 1 changes before they are sent to the update table.
- Uses hashes to detect changes instead of comparing column values directly.
- Handle intra-day changes.
Using Hashes in SQL Server T-SQL Code to Detect Changes
In this section we’ll introduce hashes for detecting changes. At the same time, we’ll use these to detect type 1 changes in the data flow itself, combining the first two points of the optimizations.
The point of using a hash is that you create a concatenation of all the columns you want to compare them and hash them into one single column. Now you have to compare only one single value instead of multiple columns. Once one of the columns has a different value, the hash will be different and we’ve effectively detected a change. There are two options for creating a hash:
- Using T-SQL with the HASHBYTES function. In many data warehouse scenarios, data is first staged into a landing zone or staging environment. This means we read data from a relational source, so we can use T-SQL to add the hash column.
- If you don’t have a relational source for your dimension data, you can add the hash in the data flow. The tip Using hash values in SSIS to determine when to insert or update rows gives an example using a script component.
In this tip, we’ll use HASHBYTES since we read from a staging table in SQL Server. The first step is to adjust the SELECT statement that reads the data from the staging table. We need to add two hashes: one for the type 2 columns and one for the type 1 columns.
SELECT
[CustomerName]
,[Location]
,[Email]
,ValidFrom = CONVERT(DATE,DATEADD(DAY,-1,GETDATE()))
,[Hash_SCD1] = CONVERT(CHAR(66)
,HASHBYTES( 'SHA2_256'
,[Email]
)
,1)
,[Hash_SCD2] = CONVERT(CHAR(66)
,HASHBYTES( 'SHA2_256'
,[Location]
)
,1)
FROM [dbo].[CustomerStaging];
The output of this SELECT statement:

In this simple example, there is only one column for each hash. However, in reality you’ll have many more columns. Typically you can use the CONCAT function or the CONCAT_WS function (since SQL Server 2017) to concatenate all the columns together. The advantage of those functions is you don’t have to cast columns to string values and they implicitly convert NULL values to blank strings. In the example, we’re using the SHA2 hash function. We’re also converting it to a character string using binary conversion (the CONVERT function has a third parameter, which is set to 1 in this case). We’re using a string value to compare since this works better in the SSIS conditional split transformation. Not using the binary conversion leads to strange symbols instead of a nice hexadecimal string:

In the left column, the binary conversion is used while in the right column the result of the hash function is directly cast to a char(66) string.
We’ve added hashes to the source data, but we need to compare it of course. You have two options:
- Store the hash values from the source along with the other columns when loading new rows.
- Use calculated column in the dimension tables to calculate the hashes on the fly.
The disadvantage of the first option is that you’ll have to recalculate the hash for every type 1 update or every time new columns are added or removed from the dimension. With calculated columns, you only have to update their definition when the table schema changes.
Let’s add the two calculated columns to the dimension:
ALTER TABLE [dbo].[DimCustomer]
ADD [Hash_SCD1] AS CONVERT(CHAR(66)
,HASHBYTES( 'SHA2_256'
,[Email]
)
,1)
,[Hash_SCD2] AS CONVERT(CHAR(66)
,HASHBYTES( 'SHA2_256'
,[Location]
)
,1);
The dimension data now looks like this:

The SQL statement for the lookup component needs to be adapted as well:
SELECT
[SK_Customer]
,[CustomerName]
,[Hash_SCD1_OLD] = [Hash_SCD1]
,[Hash_SCD2_OLD] = [Hash_SCD2]
FROM [dbo].[DimCustomer]
WHERE [ValidTo] IS NULL;
In the Columns pane of the lookup, the two hashes need to be retrieved:
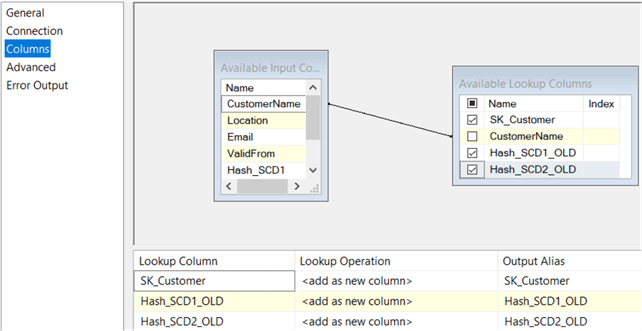
The conditional split checking for type 2 changes needs altering as well. The Location column is now removed from the data flow, so we need to replace it with the hashes in the formula:
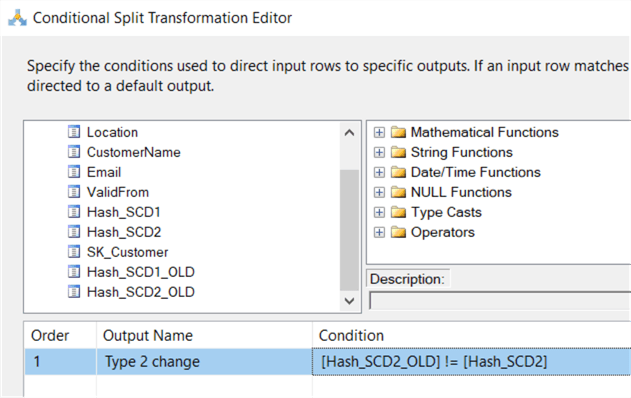
We can also add a new line that will check if there are type 1 columns with new values:
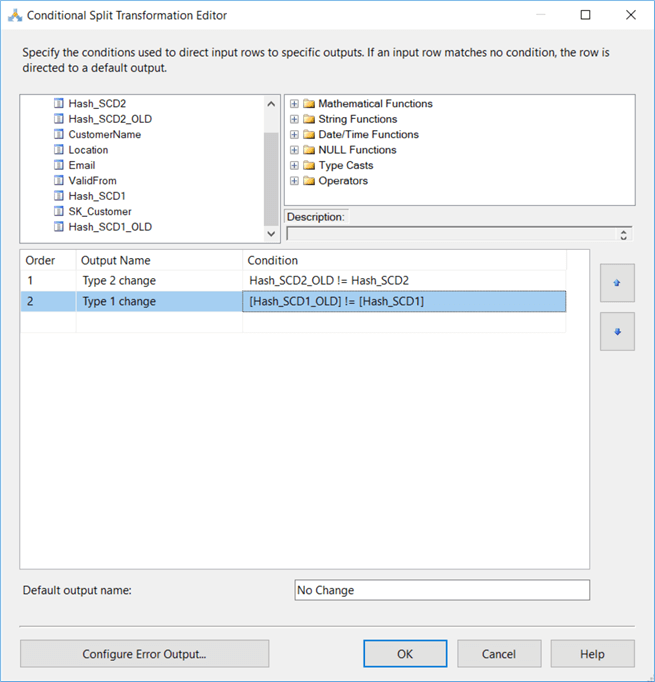
In the data flow, we have to replace the “No Change” output with the “Type 1 change” output:
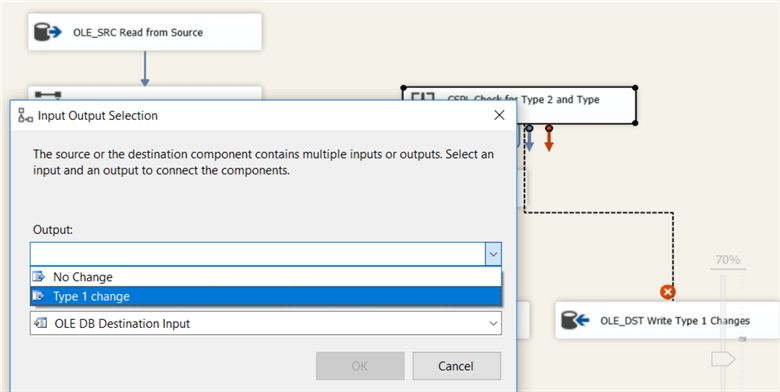
The final data flow takes the following form:
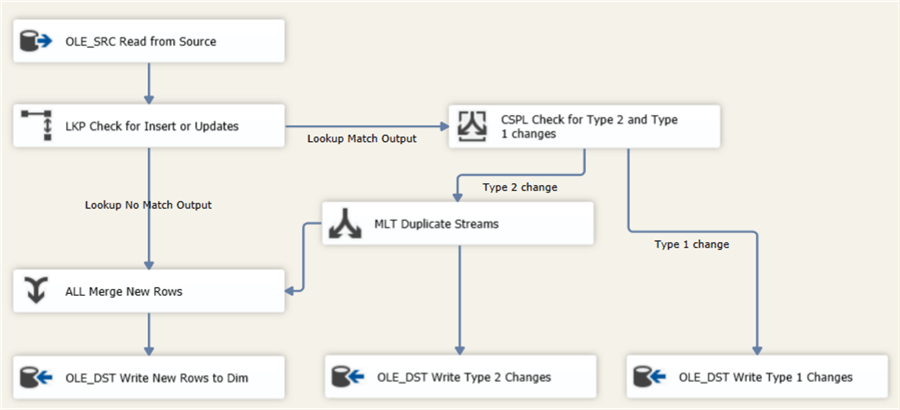
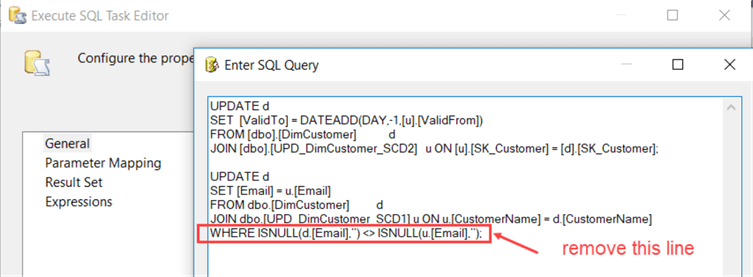
Now data will only be written to the “OLE_DST Write Type 1 changes” destination if one or more type 1 columns have new values. One last adjustment is to remove the WHERE clause of the UPDATE statement in the Execute SQL Task:
Conclusion
In this tip we introduced a mechanism using hashing of columns to easily detect changes. When one of the columns has a new value, the hash will change entirely and it will differ from the hash of the previous version of the row. We used this hash mechanism to detect changes for type 1 and type 2 attributes. Because of this, we can optimize performance by only writing rows to the type 1 update table if there is an actual change.
Next Steps
- Read part 1 and part 2 of this tip to learn more about the pattern to load a slowly changing dimension of type 2.
- The following tip explains more about the HASHBYTES function: Using Hashbytes to track and store historical changes for SQL Server data.
- If you want to know more about implementing slowly changing dimensions in SSIS, you can check out the following tips:
- You can find more SSIS development tips in this overview.






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
