By: Ameena Lalani | Comments | Related: > Upgrades and Migrations
Problem
Your company’s business is to host databases that require uptime of 24x7x365 days per year. Your company has invested a lot in building solid infrastructure with lots of redundancy at the VM host level and network level. They ask you (the SQL Server DBA) to make sure the database servers are redundant and that you can do Windows patching and SQL Server upgrades in less than 5 minutes. You have to present to your boss the solution of how you will upgrade your SQL Servers in the future when new versions come out without taking any application down time.
Solution
This is part 4 of the ongoing series on SQL Server Upgrade Methods. Basically, what you are being asked is to have your databases in high availability (HA) mode. There are several interesting technologies available at your disposal and you have to choose one that satisfies your business RPO (Recovery Point Objective) and RTO (Recovery Time Objective). Based on RPO and RTO numbers you will decide which technology makes most sense for your circumstances. Although this series is not about HA and DR, yet we need to talk about these needs because sometimes businesses do not allow any application downtime during the upgrade or migration of databases.
Before we go into our upgrade method scenario in this tip, I think it is important to clarify a few abbreviations and terms that are used.
Disaster Recovery and High Availability
In a Disaster Recovery (DR) scenario, RPO is the amount of time for which data loss is acceptable by business and RTO is the amount of time it will take to bring the system up and running. The combination of RTO and RPO is the Total Recovery Time.
Log Shipping is a great disaster recovery solution where the secondary server sits as a warm backup. The transaction log backups are continuously being restored on the secondary database on a set schedule. In the case of a disaster of the primary database, the secondary database needs to be brought online manually. If the last log backup is available then that needs to be restored on the secondary. Otherwise, you have to accept that data loss as part of a disaster and the choice of the investment made in the data recovery solution.
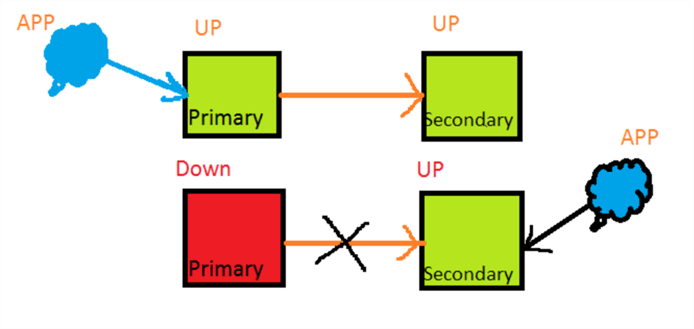
High Availability (HA), on the other hand, refers to the system that is always up and running without any data loss and almost no downtime for user applications. These definitions are very simplistic. There is redundancy and fault tolerance in this type of configuration. When things are running normally, both the Primary and Secondary systems are up and the user application is connected to the primary system. When a disaster hits the primary, the connection between the primary and secondary breaks and the Secondary system assumes the role of the Primary. The user application seamlessly redirects to the Secondary which is now the new primary. This process is totally transparent to the users.
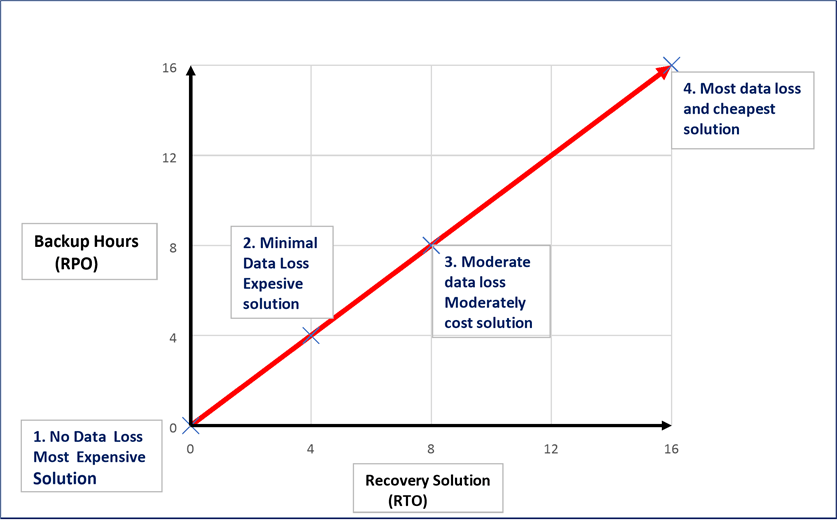
In the following chart, I am showing the approximate relationship between the RTO and RPO. The more data loss that a company can accept, the less the recovery solution will cost. For example, the backup and restore method can take the longest for a very large database, but the company will save money by not investing in any kind of DR or HA solution. The most reliable solutions such as Availability Groups or Database Mirroring will cost more, but can provide zero data loss and a few minutes of recovery time. The cost of recovery should be part of doing business and should not be thought of as optional cost. This is a decision that each business has to make.
Side by Side Upgrade Versus Rolling Upgrade
A Side by Side Upgrade, as described in Part 3, involves 2 SQL instances. These 2 instances can be on the same VM host or on different hosts. One instance has the newest SQL Server. You stop the application on the old SQL Server, backup and restore the database (or use Log Shipping) to a new instance and then connect the application to the new SQL instance. This is called side by side, because both the old and new instances of databases are available. There is application downtime involved and logins, jobs and other SQL Server objects outside of the user databases need to be scripted and created on the destination server. The advantage of this method is that if for some reason an upgrade goes wrong, you can connect your application back to the old instance. The disadvantage is there is application down time.
A rolling upgrade method also requires at the least 2 instances of SQL Server. The Primary and Secondary servers are always in sync before the upgrade. Availability Groups (AG) is one way to do rolling upgrades. By using this upgrade method, your application is always up and available. This also means logins, jobs, linked servers, etc. are all available and ready on the secondary server. The application is also configured to detect the primary database automatically. While your application is connected to the primary node, the secondary node is upgraded. As long as the secondary SQL version is the same as the Primary or later, transactions will flow from the Primary to the Secondary. Although transactions will be queued at the secondary until the upgrade finishes. You can use the asynchronous/manual AG mode in this case because you do not want automatic failover during the upgrade process. When the secondary is done upgrading, you make sure all transactions are applied (by changing the secondary to synchronous mode) and both databases are in sync, then you manually failover to the secondary instance. This step ensures zero data loss during the failover. Immediately the role changes and the upgraded secondary assumes the role of the Primary and the application starts using it and begins sending data to old primary (new secondary asynchronously). Transactions at old Primary will not be applied until its SQL version is same as the new Primary. Once the upgrade is done, it is your choice to failback to the original Primary. In a rolling upgrade, the application never goes down.
Upgrade Scenario
You have one production SQL server with 10 business critical databases ranging in size from 5 GB to 500 GB. You have setup a 2-node Availability Group (AG); SQLA and SQLB are the 2 AG nodes. According to your business process, you have created 2 AGs, AG1 and AG2 and grouped databases that needed to be failed over together to ensure the application connects and runs smoothly on the secondary when those AGs failover. These SQL Servers are running the latest Windows Operating System (OS) and SQL Server 2016 SP2. SQLB, AG secondary replica, runs in asynchronous-commit mode, and you offload client reporting needs to it. You have one disaster recovery server SQLC in a different data center, 200 miles away from your main data center. Log backups and restores happen every 5 minutes. Your company’s RPO is zero meaning no data loss is acceptable and RTO is under 5 minutes.
A few clients want their databases to be hosted on SQL Server 2017, because their applications want to take advantage of Graph database support (new in SQL Server 2017). The remaining clients have no preference.
You are required to maintain database High Availability at all times during the upgrade process.
Execution Steps
You are going to upgrade SQLA, SQLB and SQLC to SQL Server 2017. You did all your pre-upgrade tasks and testing. You are now going to follow these steps. Complete step 1 and step 2 before upgrading.
- Make sure to get extra network bandwidth, ahead of the upgrade, between the 2 servers and the second data center.
- Since the requirement of zero data loss and maintaining HA at all times, there is no point in maintaining Log Shipping. Add SQLC as a third asynchronous replica to the AGs.
| SQLA | SQLB | SQLC | |
|---|---|---|---|
| AG1 | Primary | Secondary (synchronous) | Secondary (asynchronous) |
| AG2 | Primary | Secondary (synchronous) | Secondary (asynchronous) |
- Upgrade SQLC first. While it is being upgraded, SQLA and SQLB are in sync and application is up as usual.
- Next upgrade SQLB. While it is being upgraded, SQLA and SQLC are in sync and application is up as usual.
- Once SQLB is upgraded and synced, failover AG1 and then AG2 to SQLB. SQLB assumes the role of the Primary AG. At this point application is connecting to SQLB. SQLC starts synching with SQLB. SQLA cannot sync because its version is lower than the Primary SQLB.
- Upgrade SQLA.
- Re-establish AG for SQLA and sync it with SQLB after the upgrade.
- If you prefer, failover AG1 and AG2 back to SQLA after the upgrade.
Summary
In this tip, we covered RPO and RTO and how the cost of the upgrade method depends on which DR or HA solution you choose. HA and DR are important during the upgrade process to minimize application downtime. We discussed differences in a side-by-side upgrade vs. the rolling upgrade method. Finally, we went through an upgrade scenario, simulating a real life situation and one possible way to do rolling upgrades with SQL Server.
Next Steps
- Read more Upgrade and Migration tips.
- Refer to this Microsoft documentation on how to use AG to do SQL Server upgrades.
- Read Part 1, Part 2 and Part 3 of this series.






About the author
 Ameena Lalani is a MCSA on SQL Server 2016. She is a SQL Server veteran and started her journey with SQL Server 2000. She has implemented numerous High Availability and Disaster Recovery solutions.
Ameena Lalani is a MCSA on SQL Server 2016. She is a SQL Server veteran and started her journey with SQL Server 2000. She has implemented numerous High Availability and Disaster Recovery solutions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
