By: Aaron Bertrand | Comments (5) | Related: > Database Design
Problem
An interesting scenario came up recently where a user needed to squeeze every byte out of a SQL Server table. The question they had was, how can they identify columns that are defined as, say, int or bigint, but that store much smaller values in every row? In a space-sensitive scenario, altering those columns to a more appropriate data type could be a big win.
Solution
When row and table size become a crippling limitation, my first recommendation will be to pursue other avenues – maybe removing unused indexes, adding compression, or considering clustered columnstore indexes. But sometimes you don't have those luxuries, and need to look at different approaches.
We can identify candidate columns that might be defined too large by looking at the metadata and the tables directly. If all the values in a bigint column can fit into an int column, for example, we can alter the column to int, saving 4 bytes per row. If they all fit into a smallint, we can save 6 bytes per row. That doesn't sound like much, but if you have multiple such columns across millions of rows, the difference can be staggering.
For simplicity, I'm going to stick to integer-based types: bigint, int, smallint, tinyint, and bit. You might wonder, why would you consider bit when tinyint offers the same saving? Well, if you have multiple bit columns in a table, up to 8 of them can collapse to a single byte, while each tinyint column will always take up its own byte.
Different SQL Server Data Types to Store Integer Values
Before you can analyze any columns, you need to put together the different types and their supported range of values. We know from the documentation that the following values are supported for each type:
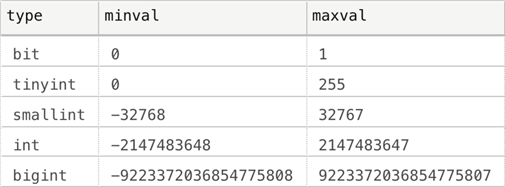
But we can generate these programmatically, which I prefer over copying and pasting from the documentation (never mind memorizing). The above results were generated by the following query:
DECLARE @src bigint = 2; SELECT [type],minval,maxval FROM (VALUES (N'bit', 0, 1), (N'tinyint', 0, 255), (N'smallint', -(POWER(@src,15)), (POWER(@src,15)-1)), (N'int', -(POWER(@src,31)), (POWER(@src,31)-1)), (N'bigint', -(POWER(@src,62)-1)*2-2, (POWER(@src,62)-1)*2+1) ) AS v([type],minval,maxval);
We can use this query as the basis for what we're going to do next: join to the catalog views for tables and columns to find all the candidate columns where we might be able to recover space. We also need to add some additional contextual information, such as the ranking of the types, whether they can be a "source" (we don't want to consider changing a bit to anything, for example) or a "target" (similarly, we don't want to consider changing anything to a bigint), the type_id, and the number of bytes that type occupies. Let's expand our initial query:
DECLARE @src bigint = 2; SELECT seq,src,trg,type_id,[type],bytes,minval,maxval FROM (VALUES (1,0,1, 104, N'bit', 1, 0, 1), (2,1,1, 48, N'tinyint', 1, 0, 255), (3,1,1, 52, N'smallint', 2, -(POWER(@src,15)), (POWER(@src,15)-1)), (4,1,1, 56, N'int', 4, -(POWER(@src,31)), (POWER(@src,31)-1)), (5,1,0, 127, N'bigint', 8, -(POWER(@src,62)-1)*2-2, (POWER(@src,62)-1)*2+1) ) AS v(seq,src,trg,type_id,[type],bytes,minval,maxval);
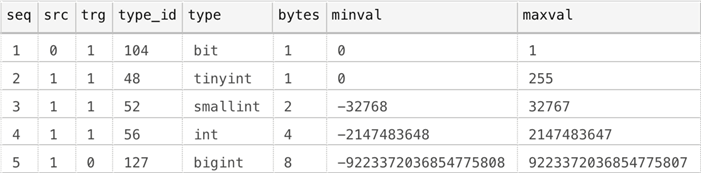
Now it gets a lot more complicated, because we need to join this set to all of the columns in all of the tables, determine how many rows are in each of those tables, and discover which of them are candidates for shrinking (in other words, all of the values in the column fit into an integer type with a lower seq value from the chart above).
Create Sample Tables to Test Different Integer Data Types
Let's say we have the following two tables:
CREATE TABLE dbo.floob(x bigint, y int, z smallint); INSERT dbo.floob(x,y,z) VALUES(1,1,1),(32766,32766,254); CREATE TABLE dbo.mort(a int, b tinyint); INSERT dbo.mort(a,b) VALUES(1,1),(32768,254);
The first table has bigint, int, and smallint columns, and all three columns could potentially be made smaller, since they contain no values that actually require the capacity of the current data type. In the second table, both columns will need to stay defined as is, since the largest value in each column will not fit into the next smallest integer type.
Finding Other Integer Data Type Candidates for Space Savings
Now let's find all of these columns that might meet our criteria into a #temp table, so we can further process them with dynamic SQL:
DECLARE @src bigint = 2;
;WITH types AS
(
SELECT * FROM
(VALUES
(1,0,1, 104, N'bit', 1, 0, 1),
(2,1,1, 48, N'tinyint', 1, 0, 255),
(3,1,1, 52, N'smallint', 2, -(POWER(@src,15)), (POWER(@src,15)-1)),
(4,1,1, 56, N'int', 4, -(POWER(@src,31)), (POWER(@src,31)-1)),
(5,1,0, 127, N'bigint', 8, -(POWER(@src,62)-1)*2-2, (POWER(@src,62)-1)*2+1)
) AS v(seq,src,trg,type_id,[type],bytes,minval,maxval)
),
cols AS
(
SELECT t.[object_id],
[schema] = s.name,
[table] = t.name,
[column] = QUOTENAME(c.name),
[type] = styp.name + COALESCE(' (alias: ' + utyp.name + ')', ''),
c.is_nullable,
trgtyp.seq,
trgtyp.type_id,
trgtype = trgtyp.[type],
savings = srctyp.bytes - trgtyp.bytes,
trgtyp.minval,
trgtyp.maxval,
[rowcount] = (SELECT SUM([rows]) FROM sys.partitions
WHERE object_id = t.object_id AND index_id IN (0,1))
FROM sys.tables AS t
INNER JOIN sys.schemas AS s
ON s.[schema_id] = t.[schema_id]
INNER JOIN sys.columns AS c
ON t.[object_id] = c.[object_id]
INNER JOIN sys.types AS styp
ON c.system_type_id = styp.system_type_id
AND c.system_type_id = styp.user_type_id
LEFT OUTER JOIN sys.types AS utyp
ON c.user_type_id = utyp.user_type_id
AND utyp.user_type_id <> utyp.system_type_id
INNER JOIN types AS srctyp
ON srctyp.type_id = c.system_type_id
INNER JOIN types AS trgtyp
ON trgtyp.seq < srctyp.seq
WHERE srctyp.src = 1
AND trgtyp.trg = 1
)
SELECT * INTO #cols FROM cols;
SELECT * FROM #cols;
The results in this case are as follows:
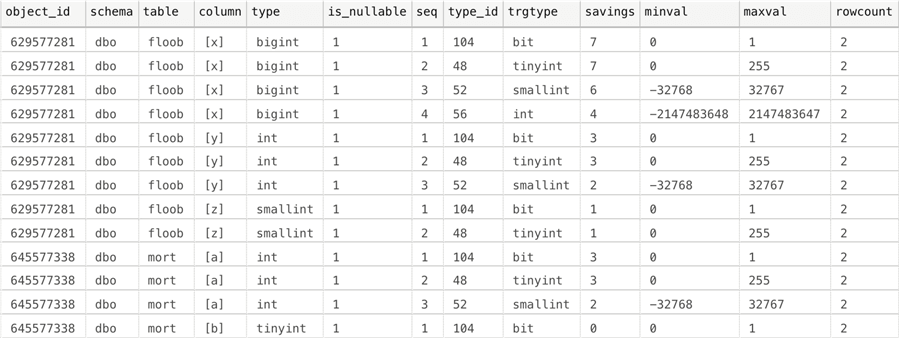
On first glance, except that this scenario is intentionally simple, I can't tell which of these are relevant or possible. I probably could have worked in a join to retrieve the smallest/largest value from each table, but I'm going to keep this in separate steps so that the initial query is not overwhelming (it would have already had to be in dynamic SQL). We can easily generate this dynamic SQL now, so that we can retrieve the min/max value from each column, compare it to our possible ranges, and weigh our options:
DECLARE @sql nvarchar(max) = N';WITH x([object_id],[column],minval,maxval)
AS (',
@core nvarchar(max) = N'
SELECT $oid, ''$c'', MIN($c), MAX($c) FROM $obj UNION ALL';
SELECT @sql += REPLACE(REPLACE(REPLACE(@core,'$oid',RTRIM(object_id)),
'$c',[column]),'$obj',QUOTENAME([schema]) + '.' + QUOTENAME([table]))
FROM (SELECT [schema],[table],[column],object_id FROM #cols
GROUP BY [schema],[table],[column],object_id) AS x;
SET @sql += N'
SELECT NULL,NULL,NULL,NULL
)
SELECT c.[schema],c.[table],c.[column],c.is_nullable,
current_type = c.[type],potential_type=c.trgtype,
space_savings=c.savings*c.[rowcount],x.minval,x.maxval,
range = RTRIM(c.minval) + '' -> '' + RTRIM(c.maxval)
FROM x
INNER JOIN #cols AS c
ON x.[object_id] = c.[object_id]
AND x.[column] = c.[column]
AND x.minval >= c.minval
AND x.maxval <= c.maxval;';
PRINT @sql;
-- EXEC sys.sp_executesql @sql;
The above code is pretty ugly, but below is the resulting query that is produced and the output from the PRINT command in the above code which is easier to read and follow:
;WITH x([object_id],[column],minval,maxval)
AS (
SELECT 629577281, '[x]', MIN([x]), MAX([x]) FROM [dbo].[floob] UNION ALL
SELECT 629577281, '[y]', MIN([y]), MAX([y]) FROM [dbo].[floob] UNION ALL
SELECT 629577281, '[z]', MIN([z]), MAX([z]) FROM [dbo].[floob] UNION ALL
SELECT 645577338, '[a]', MIN([a]), MAX([a]) FROM [dbo].[mort] UNION ALL
SELECT 645577338, '[b]', MIN([b]), MAX([b]) FROM [dbo].[mort] UNION ALL
SELECT NULL,NULL,NULL,NULL
)
SELECT c.[schema],c.[table],c.[column],c.is_nullable,
current_type = c.[type],potential_type=c.trgtype,
space_savings=c.savings*c.[rowcount],x.minval,x.maxval,
range = RTRIM(c.minval) + ' -> ' + RTRIM(c.maxval)
FROM x
INNER JOIN #cols AS c
ON x.[object_id] = c.[object_id]
AND x.[column] = c.[column]
AND x.minval >= c.minval
AND x.maxval <= c.maxval;
And if we run that query instead of print it (uncomment EXEC sys.sp_executesql @sql;), we see the following results:

We list all of the potential target data types, not just the smallest one. It may be that all of the current values in a bigint could fit into a smallint or tinyint, but you might find that int is safer. So this presents you with the full list rather than just the most optimal one. You can make your decision from there, based on how close the current values fit within the new range, how much space is actually saved, and other factors.
There are some other caveats, of course. This script is just meant to identify the columns and estimate the space savings in the base table. It doesn't check if these columns will introduce complications because they are computed, part of a constraint, are nullable, or exist in the key of any indexes. It also can't determine the intention or potential future use of any column. And since making a fixed width column smaller is usually a size-of-data operation, you have to consider the time this will take and the impact it will have on the transaction log while it is in progress. For these reasons, the script doesn't actually generate any ALTER TABLE commands – I want the actual change to be somewhat cumbersome for you because I want you to really think about what you are doing before you do it.
Summary
With just a little exploration and some dynamic SQL, you can quickly determine if there are significant space saving to be had by converting integer-based columns into smaller integer-based types. You could extend this solution to cover string-based columns, which can often have a bigger impact due, since string columns are often oversized and data size estimates are much more heavily influenced by the defined size rather than the actual data. I'll save that for a future tip.
Next Steps
Read on for related tips and other resources:
- SQL Server DateTime Best Practices
- Creating a date dimension or calendar table in SQL Server
- SQL Server Date function that determines date range based on weekday
- SQL Server 2008 Date and Time Data Types
- New Date and Time Functions in SQL Server 2012
- All SQL Server date tips






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
