By: Semjon Terehhov | Comments (2) | Related: > Azure Data Factory
Problem
From time to time, you have to deal with source systems where records are not timestamped, i.e. no attribute that can be used to identify whether the record has been modified. A lack of tracking information from the source system significantly complicates the ETL design. This article will help you decide between three different change capture alternatives and guide you through the pipeline implementation using the latest available Azure Data Factory V2 with data flows. The three alternatives are:
- Data Flows by ADF
- SQL Server Stored Procedures by ADF
- Azure-SSIS by ADF
Solution
ADF (Azure Data Factory) allows for different methodologies that solve the change capture problem, such as: Azure-SSIS Integrated Runtime (IR), Data Flows powered by Databricks IR or SQL Server Stored Procedures. We will need a system to work and test with: Azure SQL Databases, we can use the Basic tier which is more than enough for our purposes (use this Tip to create an Azure SQL Database) for an instance of Azure Data Factory V2. You will also require resources like SSIS and Data Bricks IRs. These are moderately expensive and depending on which solution you prefer; we will create them later.
The Resource Group should look as follows:
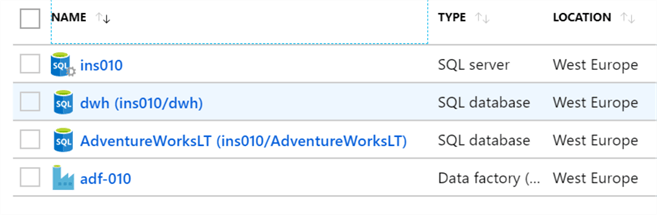
An additional database instance of AdventureWorksLT will be used in this tip to generate the source sales data, whereas dwh (data warehouse) database is the destination database. The source data AdventureWorksLT view definition is provided below:
CREATE VIEW [dbo].[view_source_data] AS SELECT Orders.SalesOrderID, DATEADD(hour,Orders.SalesOrderID,OrderHeader.OrderDate) AS OrderDateTime, Products.Name AS ProductName, Products.ProductNumber AS ProductCode, Products.Color, Products.Size, Orders.OrderQty, Orders.UnitPrice, Orders.UnitPriceDiscount AS Discount, Orders.LineTotal FROM SalesLT.Product AS Products INNER JOIN SalesLT.SalesOrderDetail AS Orders ON Products.ProductID = Orders.ProductID INNER JOIN SalesLT.SalesOrderHeader AS OrderHeader ON Orders.SalesOrderID = OrderHeader.SalesOrderID Destination table definition in dwh database: CREATE SCHEMA stg GO CREATE SCHEMA Facts GO CREATE TABLE [Facts].[SalesData] ( [HashId] [char](128) NOT NULL, -- for SHA512 algorithm [SalesOrderID] [int] NOT NULL, [OrderDateTime] [datetime2](0) NULL, [ProductName] [nvarchar](50) NOT NULL, [ProductCode] [nvarchar](25) NOT NULL, [Color] [nvarchar](15) NULL, [Size] [nvarchar](5) NULL, [OrderQty] [smallint] NOT NULL, [UnitPrice] [money] NOT NULL, [Discount] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL, [RecordTimeStamp] [timestamp] NOT NULL – keeping track of changes ) GO CREATE TABLE [stg].[SalesData] -- Staging area to Copy data to without transformation ( [SalesOrderID] [int] NOT NULL, [OrderDateTime] [datetime2](0) NULL, [ProductName] [nvarchar](50) NOT NULL, [ProductCode] [nvarchar](25) NOT NULL, [Color] [nvarchar](15) NULL, [Size] [nvarchar](5) NULL, [OrderQty] [smallint] NOT NULL, [UnitPrice] [money] NOT NULL, [Discount] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL ) -- This Table should be truncated after each upload
The purpose of the ETL will be to keep track of changes between two database tables by uniquely identifying every record using the following attributes: SalesOrderID, OrderDateTime, ProductName, ProductCode, Color and Size.
In real world terms, this will be applicable to scenarios where some order details like: quantity, unit price, discount, total are updated after the initial order line is written into the ERP database. In some cases, due to currency exchange rate differences between sales date and conversion date. This poses a challenge for ETL developers to keep track of such changes.
As there are so many identity columns using a join transformation to locate records is somewhat unpractical and IO intensive for SQL database. A more effective way will be a hash value identity column (in SalesData table it is HashId) using SHA512 algorithm. Here are the alternatives.
Solution with ADF Data Flows
This is an all Azure alternative where Dataflows are powered by Data Bricks IR in the background. Open adf-010 resource and choose "Author & Monitor". If you need more information on how to create and run Data Flows in ADF this tip will help.
Create a Source for bdo.view_source_data and Sink (Destination) for stg.SalesData.
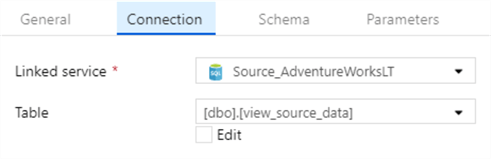
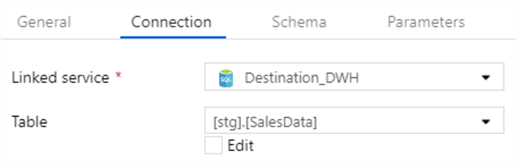
Add a new dataflow1 and add Source_SalesData as the source:
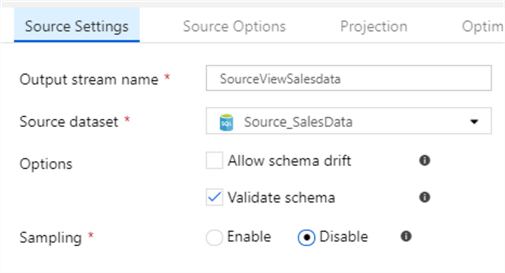
There are several options that one needs to consider depending on the behavior of the source system.
- "Allow schema drift" if enabled it will propagate metadata changes through the dataflow pipeline
- "Validate schema" if enabled it will fail if the underlying source metadata is different from the dataflow mapping
- "Sampling" is relevant for large datasets where getting part of the data is the only time feasible option
For the AdventureWorksLT dataset, none of these options are required, but you may want to adjust your choice depending on the system you are working with. The following adds a "Derived Column" transformation to calculate the HashId:

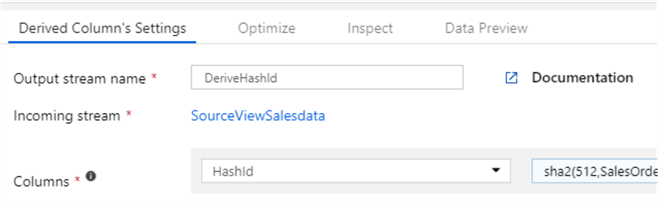
Add column HashId and open Visual Expression Builder:

The SHA-512 function definition is provided below:
sha2(512,SalesOrderID,OrderDateTime,ProductName,ProductCode,Color,Size)
The result of this function will be 128 hexadecimal character string matched by char(128) datatype in the HashId column.
Add the sink (Destination) following the derived column transformation:

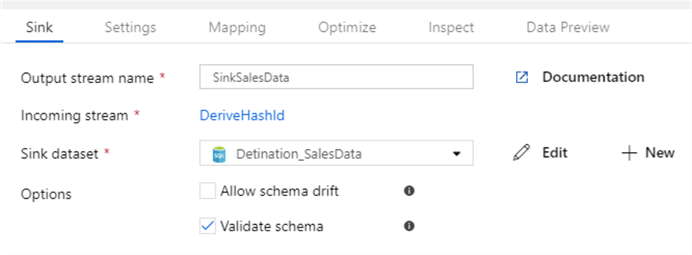
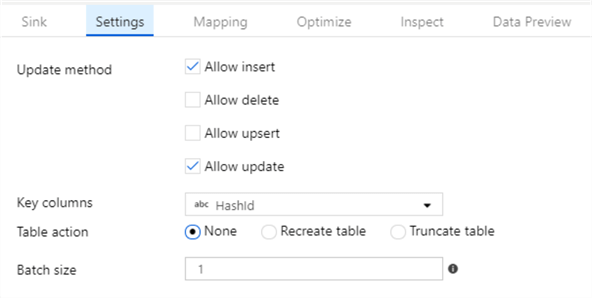
To allow data to flow smoothly between the source and destination it will update records that have equal HashIds and insert new records where HashId has no match on the Destination. We also need to setup update methods on our sink. First define the HashId column as the key column and continue with the configuration by selecting "Allow insert" and "Allow update" to get data synced between the source and destination using HashId.
Solution with SQL Server Stored Procedures
Azure data factory has an activity to run stored procedures in the Azure SQL Database engine or Microsoft SQL Server. Stored procedures can access data only within the SQL server instance scope. (It is possible to extend the scope of a stored procedure by adding a "linked server" to your instance, but from an architectural point of view this is messy, and I recommend using the Copy Data transform when it comes to 100% Azure or hybrid infrastructures). To copy data from one Azure SQL database to another we will need a copy data activity followed by stored procedure that calculates the HashId. The Pipeline will look as follows:
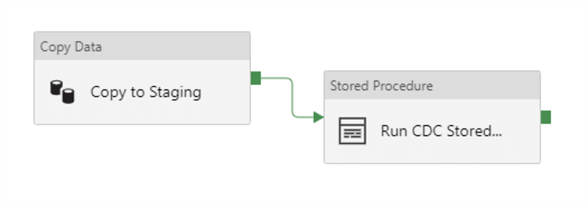
The T-SQL code for the stored procedure that calculates the HashId with the help of HASHBYTES() T-SQL function is given below:
CREATE PROCEDURE [stg].[usp_adf_cdc]
AS
BEGIN
SET NOCOUNT ON
SET IMPLICIT_TRANSACTIONS OFF
BEGIN TRANSACTION -- both changes to Fact.SalesData and truncation of staging data executed as one atomic transaction
--Microsoft: Beginning with SQL Server 2016 (13.x), all algorithms other than SHA2_256, and SHA2_512 are deprecated.
BEGIN TRY
MERGE Facts.SalesData AS DEST
USING stg.SalesData AS SRC
ON (
DEST.HashId =
HASHBYTES --HASH algorithm
(
'SHA2_512',
CAST (SRC.SalesOrderID AS nvarchar) +
CAST (SRC.OrderDateTime AS nvarchar) +
SRC.ProductName +
SRC.ProductCode +
ISNULL(SRC.Color,'') +
ISNULL(SRC.Size,'')
)
)
WHEN MATCHED THEN
UPDATE SET DEST.OrderQty = SRC.OrderQty,
DEST.UnitPrice = SRC.UnitPrice,
DEST.Discount = SRC.Discount,
DEST.Linetotal = SRC.Linetotal
WHEN NOT MATCHED THEN
INSERT (HashId, SalesOrderID, OrderDateTime, ProductName, ProductCode, Color, Size, OrderQty, UnitPrice, Discount, Linetotal)
VALUES (
HASHBYTES --HASH algorithm
(
'SHA2_512',
CAST (SRC.SalesOrderID AS nvarchar) +
CAST (SRC.OrderDateTime AS nvarchar) +
SRC.ProductName +
SRC.ProductCode +
ISNULL(SRC.Color,'') +
ISNULL(SRC.Size,'')
), SRC.SalesOrderID, SRC.OrderDateTime, SRC.ProductName,
SRC.ProductCode, SRC.Color, SRC.Size, SRC.OrderQty, SRC.UnitPrice, SRC.Discount, SRC.Linetotal);
TRUNCATE TABLE stg.SalesData
COMMIT TRANSACTION
END TRY
BEGIN CATCH
THROW -- error is returned to caller if catch block is triggered
ROLLBACK TRANSACTION -- all changes are rolled back
END CATCH
END
GO
The setup of the copy activity is given below:
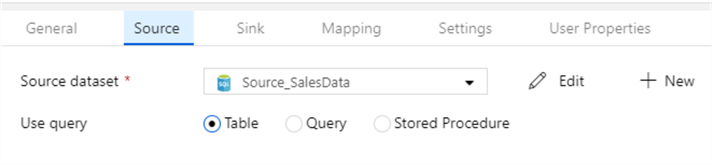
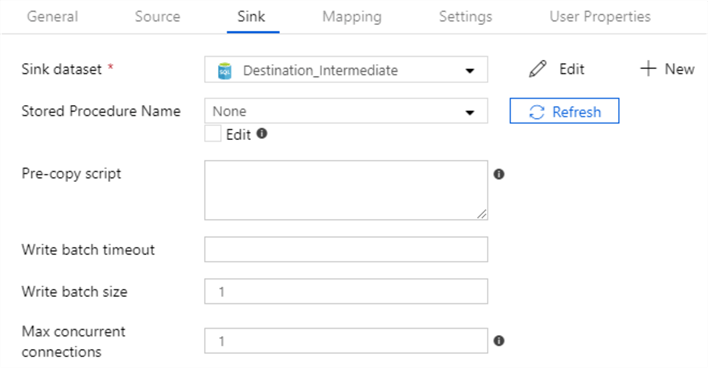
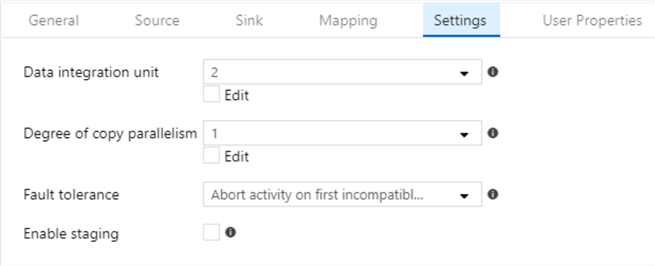
Configuration of Source and Destination are self-explanatory, but the Settings tab needs an explanation. The "data integration unit" is for performance where 2 is the least performance and 256 is the maximum performance. Tune this according to your database tier. If you are coping a lot of data, I would recommend increasing not only the data integration unit, but also the "degree of copy parallelism". The "fault tolerance" setting affects the next activity execution. This pipeline will execute the stored procedure only if all rows in the copy activity are successful, this does not have to be this way, you could change the precedence constraint to competition instead of success.
Deploy and Debug to verify the pipeline code:
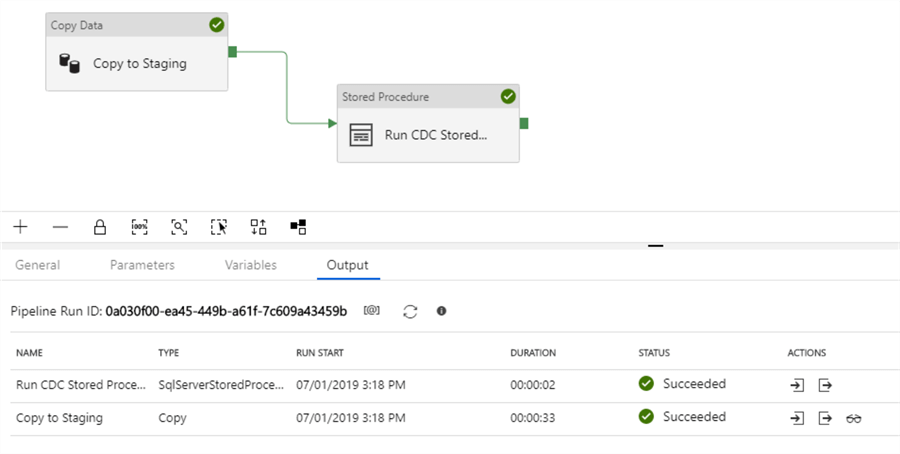
Solution with Azure-SSIS
Data Factory can orchestrate execution of SSIS packages from the SSISDB repository by setting up an Azure-SSIS Integrated Runtime on the ADF overview page:

For more help on configuration of Azure-SSIS IR environment consult this tip. Azure SSIS IR is costly when it comes to both compute resources and requires a SQL Server license. To minimize expenses, consider the resource level you need. In my experience for most small to medium size projects, one VM node of Standard_D4_v3(4vCores and 16GB memory) size is enough.
To compute the HashId with Azure-SSIS pipeline setup a project with the following data flow tasks:
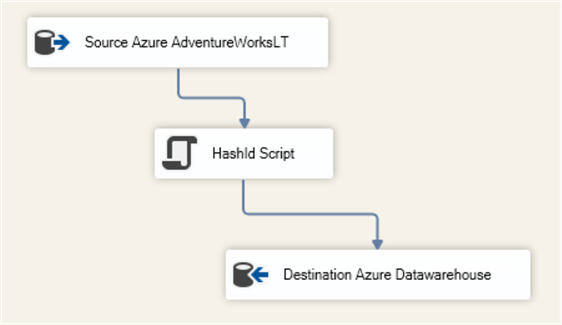
The "HashId Script" component is a C#.net SSIS script configured for "Transformation". For more help on getting started with the SSIS Script task check out this tip.
The dot.NET C# code for the script component for the HashId using SHA2_512 algorithm is given below:
#region Namespacesusing System;
using System.Text;
using System.Security.Cryptography;
#endregion
public override void Input0_ProcessInputRow(Input0Buffer Row)
{
String ProductColor;
String ProductSize;
if (Row.Color_IsNull == true) { ProductColor = ""; }
else { ProductColor = Row.Color.ToString(); }
if (Row.Size_IsNull == true) { ProductSize = ""; }
else { ProductSize = Row.Size.ToString(); }
String RowString = Row.SalesOrderID.ToString() +
Row.OrderDateTime.ToString() +
Row.ProductName.ToString() +
Row.ProductCode.ToString() +
ProductColor +
ProductSize;
HashAlgorithm sha_512 = new SHA512CryptoServiceProvider();
byte[] binary_hash = sha_512.ComputeHash(Encoding.UTF8.GetBytes(RowString));
Row.HashId = ByteArrayToHexString(binary_hash);
}
public static string ByteArrayToHexString(byte[] MyByteArray)
{
StringBuilder HexedecimalString = new StringBuilder(MyByteArray.Length * 2);
foreach (byte Byte in MyByteArray)
HexedecimalString.AppendFormat("{0:x2}", Byte);
return HexedecimalString.ToString();
}
}
}
This script performs the exactly same actions as the T-SQL stored procedure in the previous section. It calculates a SHA2_512 hash value using the same columns and handles NULL exceptions for the color and size attributes.
Debug the SSIS package.
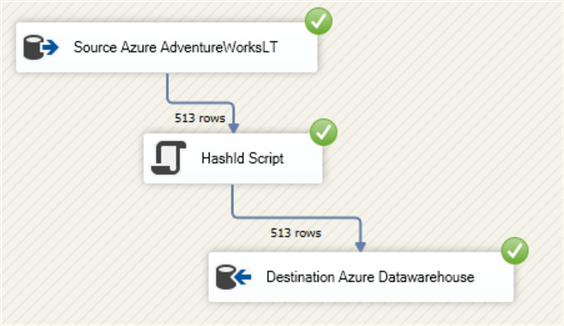
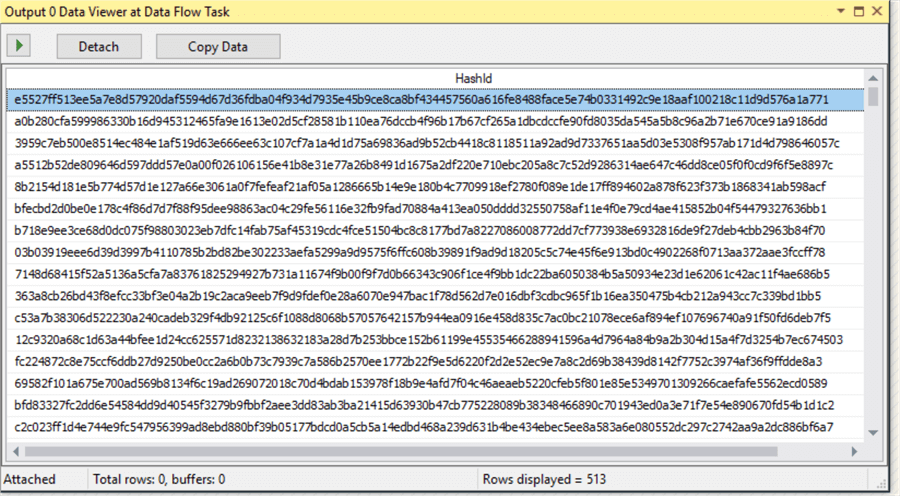
The main advantage of the Azure-SSIS architecture is the ability for live debugging and data analysis while the pipeline runs. You can examine the HashId values live by placing a Data Viewer on the output of the script component, below is what this looks like.
Conclusion
All three Azure pipeline architectures have pros and cons when it comes to change capture using hashing algorithms. When it comes to usability and scalability, the Data Flow architecture clearly stands out as a better option. It offers the cleanest (from a coding point of view) approach to hash the attribute values. Whereas, the Stored Procedure and Azure-SSIS approaches give more control over the data flow and development process.
Next Steps
- Check out how you can execute SSIS packages with ADF
- How to configure ADF Data Flow from scratch
- Datawarehouse ETL with ADF Data Flow
- Create triggers for ADF






About the author
 Semjon Terehhov is an MCSE in Data Management and Analytics, Data consultant & Partner at Cloudberries Norway.
Semjon Terehhov is an MCSE in Data Management and Analytics, Data consultant & Partner at Cloudberries Norway.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
