By: Ian Fogelman | Comments (8) | Related: More > Import and Export
Problem
Have you ever wanted to quickly aggregate massive amounts of CSV files with a similar data structure into a master dataset in a SQL Server database? AWS has a service called Athena that will accomplish this and there are many Microsoft products and scripting languages to do the task, but today we look at how to accomplish it in pure T-SQL.
Solution
We will look at how this can be done using BULK INSERT and some system stored procedures to process and import all files in a folder.
Step 1 – Check Service Account Permissions
Also be sure that your SQL Server service account has access to the drive and folder your attempting to load from. If you are unsure the name of your service account it can be checked by opening the appropriate version of SQL Server Configuration Manager >>SQL Server Services and looking at the account name:
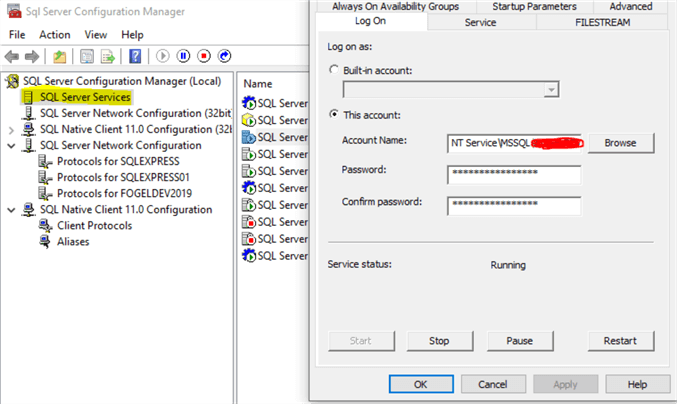
Step 2 - Preview CSV files
Here is our working directory, we have two csv files 1.csv and 2.csv with a single column.

1.csv

2.csv
Our goal is to take all of our .csv files in our directory and dynamically bulk insert the data from each of those CSV files into a SQL Server temp table. To find the files inside of our directory we will use the xp_DirTree system stored procedure which will return the names of each file in a directory, we load those results to a temporary table.
Step 3 - Create temp table structure for file names
Below we will get all files in folder "C:\Test\".
IF OBJECT_ID('TEMPDB..#TEMP_FILES') IS NOT NULL DROP TABLE #TEMP_FILES
CREATE TABLE #TEMP_FILES
(
FileName VARCHAR(MAX),
DEPTH VARCHAR(MAX),
[FILE] VARCHAR(MAX)
)
INSERT INTO #TEMP_FILES
EXEC master.dbo.xp_DirTree 'C:\Test\',1,1
Then we delete from that temp table where the file extension is not .csv.
DELETE FROM #TEMP_FILES WHERE RIGHT(FileName,4) != '.CSV'
Step 4 - Create result table and insert data
Next, we construct another temp table which has the same schema as the csv files we are going to load. In this case it’s a single column “A”.
Now we iterate over the remaining records in our first temp table which should be the .csv file names we are attempting to load data from. We assign a filename variable each iteration of the while loop to pick up the file name and pass it to our dynamic SQL variable then execute it.
IF OBJECT_ID('TEMPDB..#TEMP_RESULTS') IS NOT NULL DROP TABLE #TMP
CREATE TABLE #TEMP_RESULTS
(
[A] VARCHAR(MAX)
)
DECLARE @FILENAME VARCHAR(MAX),@SQL VARCHAR(MAX)
WHILE EXISTS(SELECT * FROM #TEMP_FILES)
BEGIN
SET @FILENAME = (SELECT TOP 1 FileName FROM #TEMP_FILES)
SET @SQL = 'BULK INSERT #TEMP_RESULTS
FROM ''C:\Test\' + @FILENAME +'''
WITH (FIRSTROW = 2, FIELDTERMINATOR = '','', ROWTERMINATOR = ''\n'');'
PRINT @SQL
EXEC(@SQL)
DELETE FROM #TEMP_FILES WHERE FileName = @FILENAME
END
When the execution is finished all data from 1.csv and 2.csv is inside of our #temp_results table.
SELECT * FROM #TEMP_RESULTS
Step 5 - Improve the insert process with a try catch block
This strategy can be a cheap and easy way to get your data loaded into your SQL Server database. You could script this job to run and check nightly for new files and append your result set to your production data. Things to bear in mind with the bulk insert in any delimited form could have data that will break the insert. A try catch statement will allow a chance for each file to be processed even if the first file fails.
WHILE EXISTS(SELECT * FROM #TEMP_FILES)
BEGIN
BEGIN TRY
SET @FILENAME = (SELECT TOP 1 FileName FROM #TEMP_FILES)
SET @SQL = 'BULK INSERT #TEMP_RESULTS
FROM ''C:\Test\' + @FILENAME +'''
WITH (FIRSTROW = 2, FIELDTERMINATOR = '','', ROWTERMINATOR = ''\n'');'
PRINT @SQL
EXEC(@SQL)
END TRY
BEGIN CATCH
PRINT 'Failed processing : ' + @FILENAME
END CATCH
DELETE FROM #TEMP_FILES WHERE FileName = @FILENAME
END
Step 6 - A more complex example
Let’s apply the logic we have created to a more complex data set.
In these 3 csv files we have housing data for 3 separate streets dealing with square footage, number of bedrooms and bath rooms and a garage indicator field. This time we will change the directory for the script, it will be updated to C:\Test\Houses.



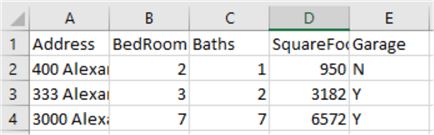
Here is the code for this example.
IF OBJECT_ID('TEMPDB..#TEMP_FILES') IS NOT NULL DROP TABLE #TEMP_FILES
CREATE TABLE #TEMP_FILES
(
FileName VARCHAR(MAX),
DEPTH VARCHAR(MAX),
[FILE] VARCHAR(MAX)
)
INSERT INTO #TEMP_FILES
EXEC master.dbo.xp_DirTree 'C:\Test\Houses\',1,1
DECLARE @FILENAME VARCHAR(MAX),@SQL VARCHAR(MAX)
IF OBJECT_ID('TEMPDB..#TEMP_RESULTS') IS NOT NULL DROP TABLE #TEMP_RESULTS
CREATE TABLE #TEMP_RESULTS
(
[Address] VARCHAR(MAX),
[BedRoom] VARCHAR(MAX),
[Baths] VARCHAR(MAX),
[SquareFootage] VARCHAR(MAX),
[Garage] VARCHAR(MAX)
)
WHILE EXISTS(SELECT * FROM #TEMP_FILES)
BEGIN
BEGIN TRY
SET @FILENAME = (SELECT TOP 1 FileName FROM #TEMP_FILES)
SET @SQL = 'BULK INSERT #TEMP_RESULTS
FROM ''C:\Test\Houses\' + @FILENAME +'''
WITH (FIRSTROW = 2, FIELDTERMINATOR = '','', ROWTERMINATOR = ''\n'');'
PRINT @SQL
EXEC(@SQL)
END TRY
BEGIN CATCH
PRINT 'Failed processing : ' + @FILENAME
END CATCH
DELETE FROM #TEMP_FILES WHERE FileName = @FILENAME
END
We can take a look at the data we loaded as the original VARCHAR(MAX) data type.
--ORIGINAL DATA TYPES SELECT * FROM #TEMP_RESULTS
We can also type cast the data type to something that makes more sense for this data set.
--DATA CAST AFTER LOAD SELECT [Address], CAST(BEDROOM AS INT) AS BedRooms, CAST(BATHS AS Decimal(3,2)) AS BathRooms, CAST(SQUAREFOOTAGE AS INT) As SquareFootage, CAST(CASE WHEN GARAGE = 'Y' THEN 1 ELSE 0 END AS BIT) as GarageIndicator FROM #TEMP_RESULTS
Lastly to avoid reprocessing a file that may exist in two separate directories where you run this process create a PreviouslyProcessed table and in the while loop select exclude filenames of that name.
IF OBJECT_ID('TEMPDB..#TEMP_FILES') IS NOT NULL DROP TABLE #TEMP_FILES
CREATE TABLE #TEMP_FILES
(
FileName VARCHAR(MAX),
DEPTH VARCHAR(MAX),
[FILE] VARCHAR(MAX)
)
--CREATE A TABLE FOR LOGGING PROCESSED RECORDS.
IF OBJECT_ID('dbo.PreviouslyProcessed') IS NOT NULL DROP TABLE PreviouslyProcessed
CREATE TABLE PreviouslyProcessed
(
FileName VARCHAR(MAX)
)
insert into PreviouslyProcessed
values('Budapest_Ln.csv')
INSERT INTO #TEMP_FILES
EXEC master.dbo.xp_DirTree 'C:\Test\Houses',1,1
DECLARE @FILENAME VARCHAR(MAX),@SQL VARCHAR(MAX)
IF OBJECT_ID('TEMPDB..#TEMP_RESULTS') IS NOT NULL DROP TABLE #TEMP_RESULTS
CREATE TABLE #TEMP_RESULTS
(
[Address] VARCHAR(MAX),
[BedRoom] VARCHAR(MAX),
[Baths] VARCHAR(MAX),
[SquareFootage] VARCHAR(MAX),
[Garage] VARCHAR(MAX)
)
WHILE EXISTS(SELECT * FROM #TEMP_FILES WHERE FILENAME NOT IN(SELECT FILENAME FROM PreviouslyProcessed)) --AVOID PROCESSING FILES ALREADY PROCESSED
BEGIN
SET @FILENAME = (SELECT TOP 1 FileName FROM #TEMP_FILES WHERE FILENAME NOT IN(SELECT FILENAME FROM PreviouslyProcessed))
SET @SQL = 'BULK INSERT #TEMP_RESULTS
FROM ''C:\Test\Houses\' + @FILENAME +'''
WITH (FIRSTROW = 2, FIELDTERMINATOR = '','', ROWTERMINATOR = ''\n'');'
PRINT @SQL
EXEC(@SQL)
DELETE FROM #TEMP_FILES WHERE FileName = @FILENAME
INSERT INTO dbo.PreviouslyProcessed
VALUES(@FILENAME)
END
Next Steps
- Download the sample CSV files
- Next time you need to quickly import a bunch of files that have the same format, remember to use this technique to quickly import the data.






About the author
 Ian Fogelman is professional DBA with a hunger and interest for data science and application development. Ian enjoys leveraging cloud-based technologies and data to solve and automate tasks. Ian holds a MS in computer science with a concentration in software development. Ian is also a member of his local SQL Server user group and a member of his local data science user group in Columbus Georgia.
Ian Fogelman is professional DBA with a hunger and interest for data science and application development. Ian enjoys leveraging cloud-based technologies and data to solve and automate tasks. Ian holds a MS in computer science with a concentration in software development. Ian is also a member of his local SQL Server user group and a member of his local data science user group in Columbus Georgia.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
