By: Alejandro Cobar | Comments (11) | Related: > PostgreSQL
Problem
Not long ago, I was working on a SQL Server database that was growing quickly and was using a lot of disk space. After an initial check, I noticed that the amount of records in the largest table was not that many (only about 150,000) and the size of the database was a little over 100GB. The large table contained only 2 columns, an ID and a VARBINARY field that was quite wide (in terms of the amount of data stored in each row), hence the size. Eventually, I had to come up with a strategy to purge old information in chunks, because a single delete would have caused blocking and other potential issues.
I was thinking to myself, what if I run into a similar situation with other RDBMS (MySQL or PostgreSQL)? Would I see similar results if I had to delete lots of rows from tables with very wide rows? I got curious enough to give it a try and will share my results. I hope you find this as interesting as I did while doing the tests.
Solution
In this tip I will be presenting the results I compiled after performing records deletions within each respective RDBMS. The tests will be done against a set of 10,000 records in a table that only has an id column and a wide string (1,000,000 characters to be precise).
Initial considerations
As you probably already have guessed by the title of this article, I'm performing the tests against a SQL Server, MySQL and PostgreSQL database instance. To keep things as fair as possible, I'm performing each test in a Linux virtual machine that has the exact same specs; for the data type of the wide column, I tried to choose something as homologous as possible between them. One last detail for the RDBMS setup is that I tested them right out of the box, without any best practices, tuning, or specific parameter settings to possibly help improve performance.
VM Specs
- OS: Ubuntu Server 20.04 LTS
- CPU: Intel Core i7 2.7GHz (3820QM)
- RAM: 8GB DDR3 1600MHz
- Volume Size: 25GB
Information related to the RDBMSs and their respective runs
I used the latest available version of each product to keep things as fair as possible.
The scenario for the test goes like this:
1 - A simple test database is created in each DB instance and a table containing the wide column, with a structure similar to this:
CREATE TABLE test(
**id INT NOT NULL PRIMARY KEY AUTOINCREMENT,
***wide VARCHAR(MAX) NOT NULL
)
The syntax for the auto increment id varies within each RDBMS, but it is just to give you an idea.
The data type of the wide column is not exactly the same across all RDBMSs, but I tried to choose one for each that allows me to store the exact same data in each of them, to keep things as similar as possible.
2 - A round of 10,000 records is inserted and the following rounds of deletes are performed:
- Time to delete 1,000 rows, as well as the size of the respective transaction log file after its completion.
- Time to delete 2,000 rows, as well as the size of the respective transaction log file after its completion.
- Time to delete 3,000 rows, as well as the size of the respective transaction log file after its completion.
- Time to delete 4,000 rows, as well as the size of the respective transaction log file after its completion.
- Time to delete 5,000 rows, as well as the size of the respective transaction log file after its completion.
- Time to delete 10,000 rows, as well as the size of the respective transaction log file after its completion.
3 - I'm inserting a string 1,000,000 characters long, in the wide column of each row (the exact same across all of the rows), which I'm attaching as a sample in case you want to try it in your system.
4 - For the tests in each RDBMs, I made sure that only that RDBMS was running in the VM while the other two were completely shut down.
Insertion Round
These metrics were measured on a completely empty instance for each case.
| RDBMS | Version | Wide Column DataType | Time to insert 10,000 records | Size of data file after the insertion |
|---|---|---|---|---|
| SQL Server | 2019 CU6 | VARCHAR(MAX) | 18min 25sec | 9,864MB |
| MySQL | 8.0.21 | LONGTEXT | 13min 15sec | 9251.52MB |
| PostgreSQL | 12.2 | VARCHAR(1000000) | 4min 20sec | 147MB |
Deletion Rounds
After each deletion round, the log file is cleaned/wiped before the next round takes place. For each example, there's a chart for comparison to get a better sense of the results. Note, I multiplied the time results by 10 just for visualization purposes.
1,000 Records Delete Test
| RDBMS | Time to delete records | Size of log file after the deletion |
|---|---|---|
| SQL Server | 44sec | 72MB |
| MySQL | 13.8sec | 954MB |
| PostgreSQL | 0.095sec | 16MB |
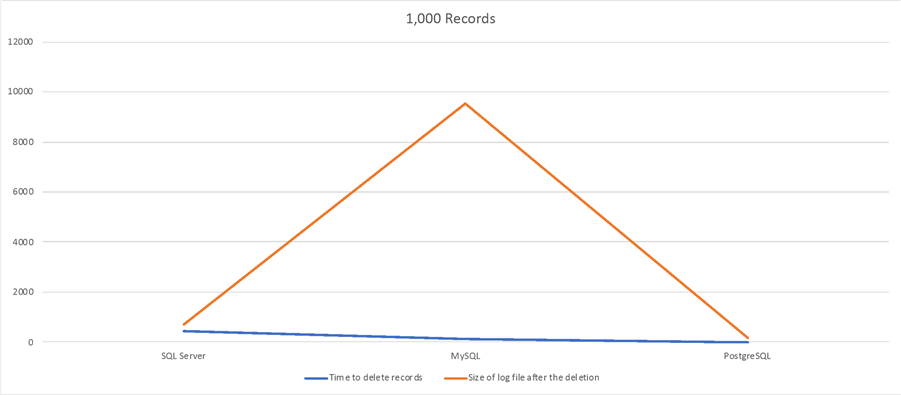
2,000 Records Delete Test
| RDBMS | Time to delete records | Size of log file after the deletion |
|---|---|---|
| SQL Server | 1min 2sec | 136MB |
| MySQL | 29.24sec | 1.9GB |
| PostgreSQL | 0.179sec | 16MB |
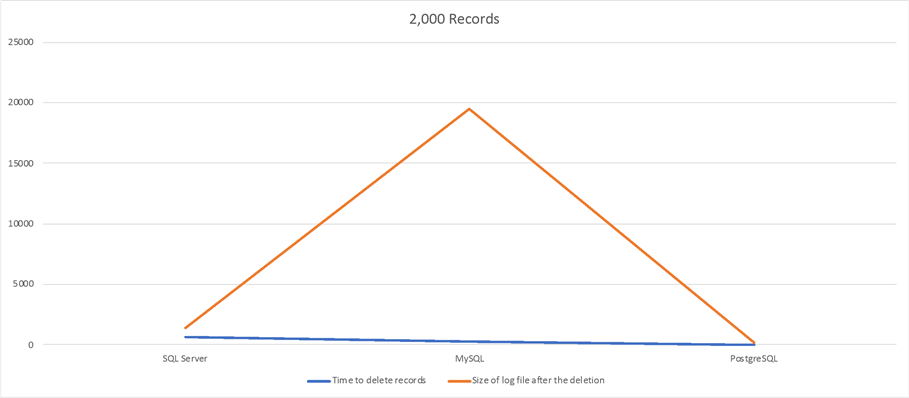
3,000 Records Delete Test
| RDBMS | Time to delete records | Size of log file after the deletion |
|---|---|---|
| SQL Server | 50sec | 200MB |
| MySQL | 2min 32sec | 2.8GB |
| PostgreSQL | 0.264sec | 16MB |
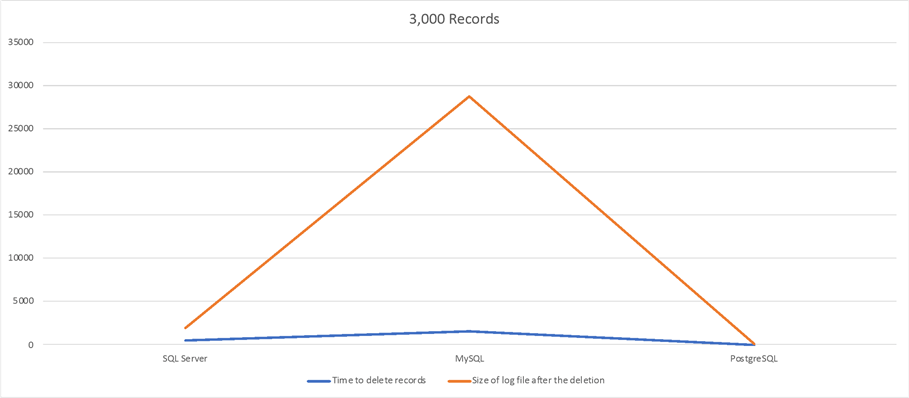
4,000 Records Delete Test
| RDBMS | Time to delete records | Size of log file after the deletion |
|---|---|---|
| SQL Server | 1min 36sec | 264MB |
| MySQL | 3min 43sec | 3.7GB |
| PostgreSQL | 0.134sec | 16MB |
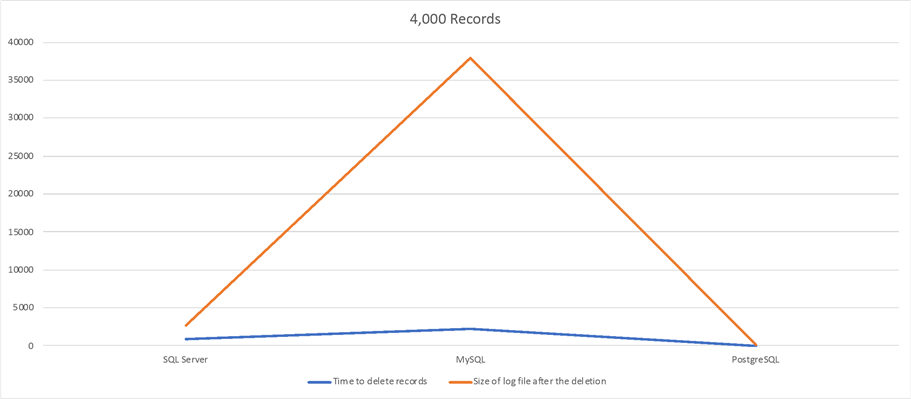
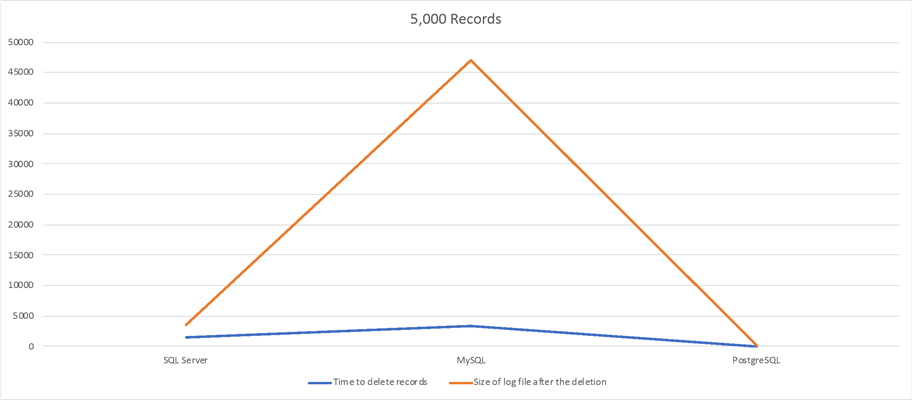
5,000 Records Delete Test
| RDBMS | Time to delete records | Size of log file after the deletion |
|---|---|---|
| SQL Server | 2min 25sec | 355MB |
| MySQL | 5min 44sec | 4.6GB |
| PostgreSQL | 0.314sec | 16MB |
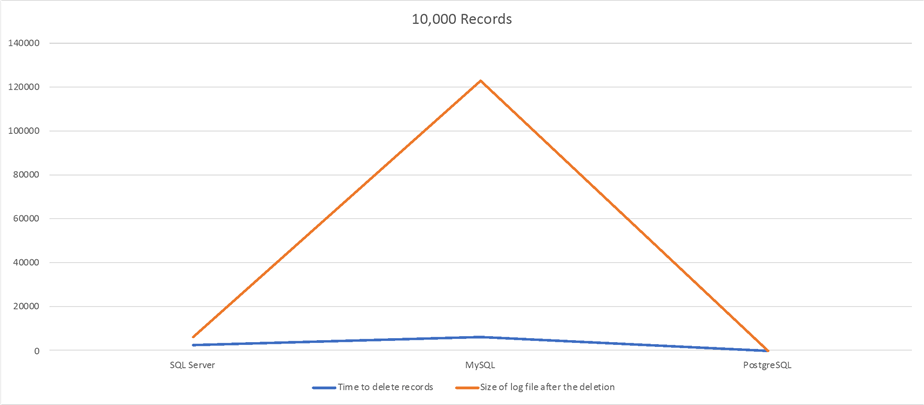
10,000 Records Delete Test
| RDBMS | Time to delete records | Size of log file after the deletion |
|---|---|---|
| SQL Server | 3min 53sec | 648MB |
| MySQL | 10min 51sec | 12GB |
| PostgreSQL | 0.639sec | 16MB |
Interesting Facts
- Without a doubt, PostgreSQL is the clear winner of this experiment. Out of the 3 RDBMSs, it was the one that made both the inserts and deletes in the least amount of time, while keeping the transaction log much smaller. It's very likely that the transaction log management of the pg_wal files and checkpoint mechanism are very well implemented, or there's something else behind the curtain that I'm just not aware of (since I'm not a PostgreSQL expert as of right now). If you have the explanation, feel free to share.
- Compared to SQL Server, MySQL has an advantage within the first 2,000 records, in terms of the time to perform the deletes. However, at every stage of the process it takes a big hit on the transaction log size which goes to the roof at the end.
- It would be interesting to perform the exact same experiment after applying best practices and properly tuning each RDBMS to see if better numbers are achieved. Although, I guess it would be a bit pointless for PostgreSQL as I don't think I would get better numbers than the ones I already got.
- In the world of RDBMSs, I have always heard that PostgreSQL is way better than MySQL. I have never used PostgreSQL in a highly transactional production environment, but after seeing the results from this experiment, I guess I can find some truth to that.
- I know for a fact that managing delete operations like these in SQL Server, by chunks, plays a whole lot better in terms of the transaction log usage. Also, locks on the table are way more relaxed and it allows you to interact with the table even if the deletes are taking place, something that doesn't happen on larger deletes.
- If you have to perform something similar in a real production system and you are working with MySQL, I guess a well thought out strategy has to be applied. Of course, after conducting several test runs to see the results first.
- It would have been interesting to throw more RDBMSs in the mix like Oracle, DB2, or jump into the NoSQL space and toss MongoDB, Cassandra, Redis, etc.
Next Steps
- Here's an article of mine that presents a script to delete a bunch of records in chunks and shows you useful information such as the amount of time to complete each batch, and the size of the transaction log file during the delete operation.
- Here are more articles, from the community, that you might find interesting
around the topic of delete data from a table:
- SQL Server Performance Issue for Single Row Delete or Update Operations – by Simon Liew
- Fastest way to Delete Large Number of Records in SQL Server – by Aaron Bertrand
- Deleting Historical Data from a Large Highly Concurrent SQL Server Database Table – by Daniel Farina
- PowerShell Script to Delete All Data in a SQL Server Database – by Jeffrey Yao






About the author
 Alejandro Cobar is an MCP, SQL Server DBA and Developer with 10+ years of experience working in a variety of environments.
Alejandro Cobar is an MCP, SQL Server DBA and Developer with 10+ years of experience working in a variety of environments.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
