By: Aaron Bertrand | Updated: 2022-07-07 | Comments (3) | Related: > Performance Tuning
Problem
Many of us deal with logging tables that grow unchecked for years, while reporting queries against them are expected to continue running quickly regardless of the size of the table. A common issue when querying by a date range is that the clustered index is on something else (say, an IDENTITY column). This will often result in a full clustered index scan, since SQL Server doesn't have an efficient way to find the first or last row within the specified range. This means the same query will get slower and slower as the table grows.
Solution
Gradual query time increases may not be a symptom your users notice (yet). They could be swimming along, not realizing that over the past year their query has gone from 4 seconds to 6 seconds. Eventually, though, they're going to notice, or queries are going to start hitting application timeouts. Changing expectations or increasing timeouts are not solutions.
You're probably wondering, "Aaron, why wouldn't you just change the clustered index, add partitioning, or put an index on the datetime column?" There are a few potential reasons (and this list is not exhaustive):
- I might not be able to change the clustered index (and it may be columnstore, which can add other complications).
- I might not have enough space to rebuild online, or a large enough window to rebuild offline.
- I can't always easily implement partitioning (and this would depend on a clustering key based on the datetime column anyway, since partitioning on an IDENTITY column still won't let a query eliminate partitions based on another column).
- It may not be possible due to space or other concerns to create a covering non-clustered index keyed on datetime, and a narrower index that will require key lookups could be just as bad or worse.
Let's assume that index changes are not going to be a practical solution for one or more of these reasons, and we're stuck with the clustered index on a different column, so our range queries based on date/time must scan the entire table.
One technique I have found to work well is to pay for that expensive scan once by correlating ID values with points in time, then storing those relationships in what I call a "goal posts" table.
Let's start with an example of the original logging table:
CREATE TABLE dbo.HippoLog ( LogID bigint IDENTITY(1,1) PRIMARY KEY, EventDateTime datetime2(3) NOT NULL, filler char(400) NOT NULL DEFAULT '' );
Now we can use a query to generate about 30K rows or so for each day in the month of July 2022 (with a few stragglers on either end). Basically, we are just taking a million row numbers from catalog views, evenly distributing a million rows across 30 days, with each row having a one-second increment from the previous row until we're out of rows for that day:
DECLARE @start datetime2(3) = '20220630',
@TotalRows int = 1000000,
@DaySpread int = 33;
DECLARE @RowsPerDay int = @TotalRows / @DaySpread * 1.0;
;WITH TotalRows AS
(
SELECT TOP (@TotalRows) n = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2
)
INSERT dbo.HippoLog(EventDateTime)
SELECT DATEADD(SECOND, n % @RowsPerDay, DATEADD(DAY, n / @RowsPerDay, @start))
FROM TotalRows;
This may look over-engineered, but there are even more complicated ways to do it – say if you wanted more random-ish distribution, skew toward weekdays or business hours, or more variance per day. This produces exactly 30,303 rows per day, which brings each day's data to about 8:25 AM. We could spread it out more evenly, but my goal here was simply to produce a bunch of data across a date range, and the actual timestamps don't matter.
Next, we have this stored procedure, taking start and end as input parameters, returning all the rows in that range:
CREATE PROCEDURE dbo.GetHippoLogs
@start datetime2(7), -- use (7) so .9999999
@end datetime2(7) -- doesn't round up
AS
BEGIN
SET NOCOUNT ON;
SELECT LogID, EventDateTime, filler
FROM dbo.HippoLog
WHERE EventDateTime >= @start
AND EventDateTime <= @end;
END
GO
When we call that stored procedure:
EXEC dbo.GetHippoLogs @start = '20220705 22:14',
@end = '20220706 03:31';
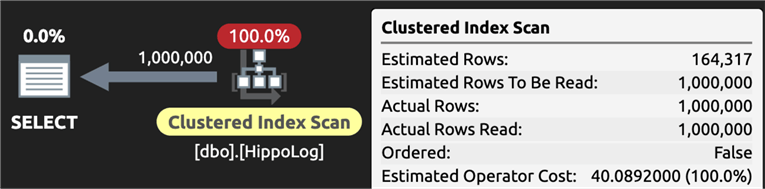
We get a plan that looks like this, including a full clustered index scan, even though only 1.2% of the table is returned:

And here are the costs:
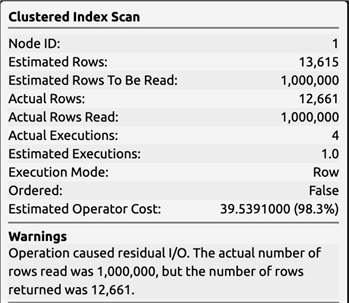
What if we're able to help SQL Server out by narrowing it to a seek and range
scan? If we think about how this could work, imagine if – in addition to the
start and end range – we could provide SQL Server with a
LogID that would be guaranteed to be within a day
before the start of the range, and another LogID that
would be guaranteed to be within a day after the end of the range? In query form,
we find the MIN and MAX
LogID for every day in the table:
SELECT TheDate = CONVERT(date, EventDateTime),
FirstLogID = MIN(LogID),
LastLogID = MAX(LogID)
FROM dbo.HippoLog
GROUP BY CONVERT(date, EventDateTime);
Truncated results will look something like this:
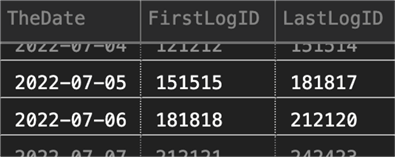
This is a slightly uglier plan, of course, but the goal is to only find all these goal posts once:

We can change the query slightly to put those results into their own table (which we will keep around):
SELECT TheDate = CONVERT(date, EventDateTime),
FirstLogID = MIN(LogID),
LastLogID = MAX(LogID)
INTO dbo.HippoLogGoalPosts
FROM dbo.HippoLog
GROUP BY CONVERT(date, EventDateTime);
CREATE UNIQUE CLUSTERED INDEX CIX_GoalPosts
ON dbo.HippoLogGoalPosts (TheDate);
Now our stored procedure can go grab the opening and closing goal posts to add to the query:
ALTER PROCEDURE dbo.GetHippoLogs
@start datetime2(7),
@end datetime2(7)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @lo bigint, @hi bigint,
@s date = @start, @e date = @end;
-- get the lowest ID on the day at the beginning,
-- and the highest ID on the day at the end:
SELECT @lo = MIN(CASE WHEN TheDate = @s THEN FirstLogID END),
@hi = MAX(CASE WHEN TheDate = @e THEN LastLogID END)
FROM dbo.HippoLogGoalPosts
WHERE TheDate IN (@s, @e);
-- now add those to the query:
SELECT LogID, EventDateTime, filler
FROM dbo.HippoLog
WHERE LogID >= @lo
AND LogID <= @hi
AND EventDateTime >= @start
AND EventDateTime <= @end;
END
GO
Running the same query as above:
EXEC dbo.GetHippoLogs @start = '20220705 22:14',
@end = '20220706 03:31';
The plan is now much better (and I'm not overly concerned about the query against the goal posts table, since that is relatively tiny):
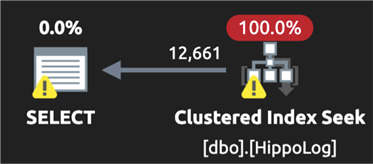
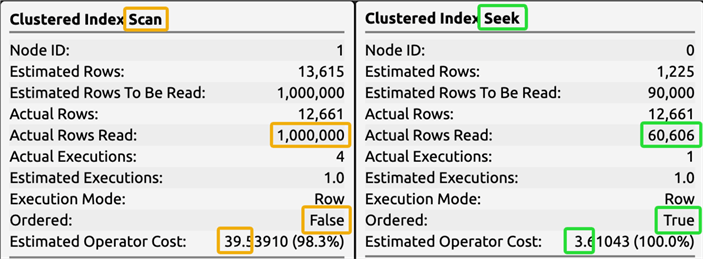
Comparing the costs:
Note that we'll want to handle start and end dates that are outside the
data we've actually captured in the goal posts table, both because users may
do unpredictable things and cast wide nets, and also because they may be querying
for part of today. We can still make the stored procedure work just fine if the
start of the range is earlier than the data in the goal posts table, or if the end
is later. We just change the WHERE clause to use the
lower or upper bound of the bigint type in the event
the data on either end is missing:
WHERE LogID >= COALESCE(@lo, 1)
AND LogID <= COALESCE(@hi, 9223372036854775807)
AND EventDateTime >= @start
AND EventDateTime <= @end;
Using token values can feel a little dirty, but it's a perfectly acceptable way to put a catch-all in there to cover an out-of-range scenario.
By first narrowing down the range of rows we want based on ID, we really reduce the cost for SQL Server to further narrow down on the specific date range. The benefit will be less substantial as our range gets larger, but this is already downplayed in our initial example because we will typically have more than 30 days' worth of data in the table (in other words, the scan against "all of time" will be much worse than what I've shown here). Gradually the savings over the old approach improves, assuming the typical range of the query doesn't change. Even if you select the whole table, you'll still technically get a seek, but it will have an incrementally more expensive cost:
EXEC dbo.GetHippoLogs @start = '19000101',
@end = '20501231';
This returns a million rows in 11 seconds. Here is the plan:

Meanwhile, if we add a WITH (FORCESCAN) hint to
the table, we can see that the resulting scan is still more expensive (though query
duration is roughly the same):
Most of the time here is spent reading, delivering, and rendering the results, not finding them; both plans will get worse as the table gets larger. The key is keeping queries reasonable – on more than one occasion I've added additional safeguards, like if the number of days between start and end exceeds some threshold, just return an error. Not the friendliest thing in the world but can prevent a scan on a trillion-row table from monopolizing all the resources on a server.
Maintenance
As time goes on, we can maintain the goal posts table using a job that runs during the day, populating the goal posts for the previous day:
DECLARE @today date = GETDATE(),
@yesterday date = DATEADD(DAY, -1, GETDATE());
DELETE dbo.HippoLogGoalPosts WHERE TheDate = @yesterday;
INSERT dbo.HippoLogGoalPosts(TheDate, FirstLogID, LastLogID)
SELECT @yesterday, MIN(LogID), MAX(LogID)
FROM dbo.HippoLog
WHERE EventDateTime >= @yesterday
AND EventDateTIme < @today;
This job should ideally run sometime after we know we've imported all of yesterday's data, but before any users run queries. But because of our failsafe, it won't be a problem even if users query during the window between the end of yesterday and the completion of today's job.
Next Steps
- If your queries against logging data are taking longer because of suboptimal indexing, and you don't have the luxury of fixing that, consider implementing a "goal posts" table to shift the cost of expensive scans away from end user queries.
- See these tips and other resources:






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-07-07
