By: Ron L'Esteve | Comments (2) | Related: > Azure Data Factory
Problem
In my previous article, Azure Data Factory Pipeline to fully Load all SQL Server Objects to ADLS Gen2, I successfully loaded a number of SQL Server Tables to Azure Data Lake Store Gen2 using Azure Data Factory. While the smaller tables loaded in record time, big tables that were in the billions of records (400GB+) ran for 18-20+ hours. How can I load big data tables from on-premises SQL Server to ADLS faster?
Azure Data Factory is a robust cloud-based data integration. Within Azure Data Factory, the Mapping Data Flows copy activity has a GUI-based tool that allows for loading partitioned data in parallel. However, Mapping Data Flows currently does not currently support on-premises sources, so this option is currently off the table. While thinking through what alternative options I might have, I know that my previous article, Using SQL Server Integration Services to Generate Excel Files Based on Criteria, I discussed how to split a large SQL Server table into multiple files. The idea behind it is to use a two ForEach Loops to create files for all partitioned ranges. The first ForEach Loop looks up the table and passes it to the second Nested ForEach Loop which will look-up the partition range and then generate the file. If I apply this same concept to Azure Data Factory, I know that there is a lookup and ForEach activity that I can leverage for this task, however, Nested ForEach Loops are not a capability of the ADF Copy activity. Again, this option is off the table. What other options might I have to generate partitioned files in the data lake based on a list of on-premises SQL Server tables?
Solution
While there are currently limitations to ADF's capabilities to generate partitioned files in the Data Lake from on-premises SQL Server tables, there is a custom solution that I can implement to achieve this task. In this article, I will walk-though the process of leveraging the pipeline parameter table that I had created in my previous articles along with introducing a new table that will be used to store the partitioned fields. The benefit of this process is two-fold: 1) I will be able to load my on-premises SQL Server table to ADLS by partitioned ranges that will load in parallel using Azure Data Factory, and 2) the partitioned records will also be streamlined into the same Azure Data Factory pipeline, look up, and foreach loop activities as the non-partitioned tables that have all been flagged and defined in my pipeline parameter table. This article will not cover any performance optimization techniques and comparisons for improving speed and performance within Azure Data Factory.
Pre-requisites
As a pre-requisite, I would recommend getting familiar with some of my previous articles related to this topic, which eventually lead to this process:
- Azure Data Factory Pipeline to fully Load all SQL Server Objects to ADLS Gen2
- Logging Azure Data Factory Pipeline Audit Data
- Using COPY INTO Azure Synapse Analytics from Azure Data Lake Store gen2
- Load Data Lake files into Azure Synapse DW Using Azure Data Factory
Create and Populate Pipeline Parameter Partition Table
In my previous articles, I introduced the concept of a pipeline parameter table which would contain the meta-data for the ADF Pipeline orchestration process.
Next, I will create a pipeline parameter partition table to store my partition related columns. The SQL syntax below will create the pipeline_parameter_partition table along with adding a foreign key constraint to the pipeline parameter table.
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[pipeline_parameter_partition]( [partition_id] [bigint] IDENTITY(1,1) NOT NULL,--Primary Key [pipeline_parameter_id] [int] NULL, --Foreign Key to pipeline_parameter ID [src_name] [nvarchar](500) NULL,--source SQL table name [partition_field] [nvarchar](500) NULL, --partition field identified in source system [partition_watermark_start] [nvarchar](500) NULL, --watermark start [partition_operator] [nvarchar](500) NULL, --operator can be altered [partition_watermark_end] [nvarchar](500) NULL, --watermark end CONSTRAINT [PK_pipeline_parameter_partition] PRIMARY KEY CLUSTERED ( [partition_id] ASC )WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[pipeline_parameter_partition] WITH CHECK ADD CONSTRAINT [FK_pipeline_parameter_id] FOREIGN KEY([pipeline_parameter_id]) REFERENCES [dbo].[pipeline_parameter] ([ID]) GO ALTER TABLE [dbo].[pipeline_parameter_partition] CHECK CONSTRAINT [FK_pipeline_parameter_id] GO
Once the pipeline_parameter_partition table is created and populated, it will look similar to this:

Create Data Factory Pipeline
Now that the base tables have been created and populated, the Data Factory pipeline can be created. Similar to my previous articles that contain steps to create pipelines, the pipeline begins with a Lookup along with a ForEach activity.
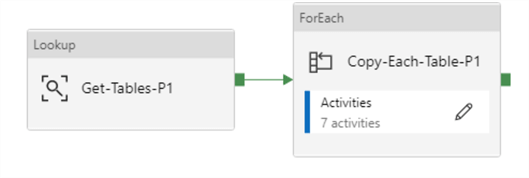
Lookup Activity – Settings and Source Query
The lookup source dataset is the Azure SQL DB containing the pipeline_parameter and pipeline_parameter_partition tables.
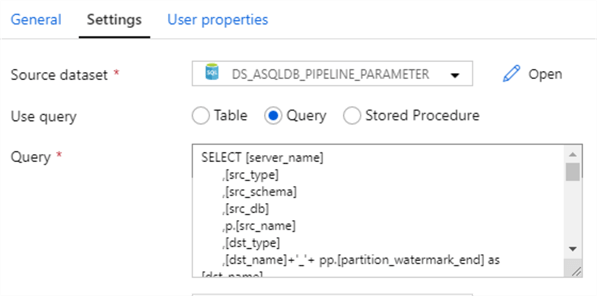
The source query joins the pipeline_parameter_partition table with the pipeline_parameter table to get a UNION result set of tables that need to be partitioned along with tables that do not need partitioning.
SELECT
[server_name]
,[src_type]
,[src_schema]
,[src_db]
,p.[src_name]
,[dst_type]
,[dst_name]+'_'+ pp.[partition_watermark_end] as [dst_name]
,[include_pipeline_flag]
,[process_type]
,[priority_lane]
,[pipeline_date]
,[pipeline_status]
,[dst_folder]+'/'+[dst_name] AS [dst_folder]
,[file_type]
,[last_modified_folder_date]
,pp.[partition_field]
,pp.partition_watermark_start
,pp.partition_watermark_end
,pp.partition_operator
FROM [dbo].[pipeline_parameter] p
INNER JOIN [dbo].[pipeline_parameter_partition] pp ON pp.pipeline_parameter_id = p.ID
WHERE adhoc = 1
AND priority_lane = 1
UNION
SELECT
[server_name]
,[src_type]
,[src_schema]
,[src_db]
,[src_name]
,[dst_type]
,[dst_name]
,[include_pipeline_flag]
,[process_type]
,[priority_lane]
,[pipeline_date]
,[pipeline_status]
,[dst_folder]+'/'+[dst_name] AS [dst_folder]
,[file_type]
,[last_modified_folder_date]
,'1' AS partition_field
,'1' AS partition_watermark_start
,'1' AS partition_watermark_end
,'BETWEEN' AS partition_operator
FROM [dbo].[pipeline_parameter] p
WHERE adhoc = 1
AND priority_lane = 1
AND p.ID not in ( SELECT DISTINCT pipeline_parameter_id FROM [dbo].[pipeline_parameter_partition] pp )
The result-set may look something like the following, where I have a record for my non-partitioned table along with three records for my partitioned table, since I defined three partitions in my pipeline_parameter_partition table. With this approach, I can combine all of my source records into one source lookup activity and have the process be driven by the pipeline parameter table.
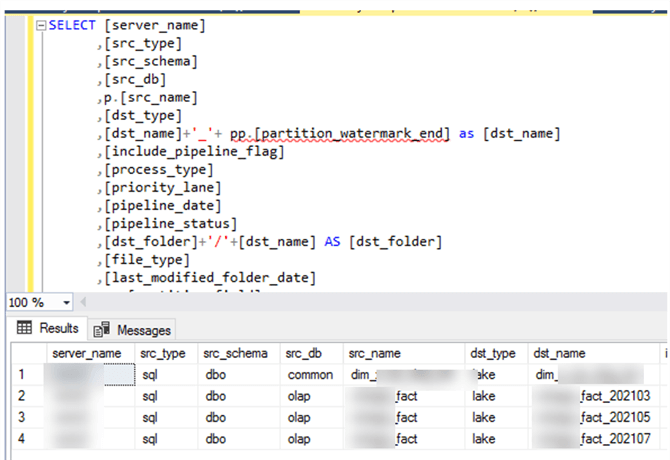
The reason why I have the following fields set to 1 is because I want the fields to evaluate to true when I pass them to the Source SQL Select statement of the ForEach Loop.
,'1' AS partition_field ,'1' AS partition_watermark_start ,'1' AS partition_watermark_end
That query would look like this where 1 BETWEEN 1 and 1, which evaluates to true. This way, the lookup query will not fail on tables from the pipeline parameter that need to be loaded to the Data Lake but do not need to be partitioned, accommodating for a streamlined process of both partitioned and non-partitioned tables.
SELECT * FROM @{item().server_name}.@{item().src_db}.@{item().src_schema}.@{item().src_name}
WHERE @{item().partition_field} @{item().partition_operator} @{item().partition_watermark_start} AND
@{item().partition_watermark_end}
ForEach Loop Activity – Settings
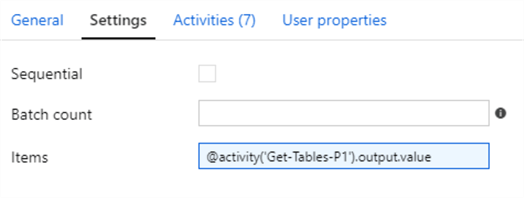
It will be important to ensure that the ForEach Loop activity setting Items contain the output value from the lookup activity.
Also, note that the 'Sequential' setting is left unchecked so that the files will be created in parallel. The batch count can also be defined. The default batch count is 20 and the max is 50.
ForEach Loop Activities
Upon drilling into the ForEach Loop activities, we see that there are a number of activities on the canvas. My previous articles discuss the success/failure logging process in greater detail. For the purpose of this article, I will focus on the stored procedure and copy activity of the ForEach Loop activity.
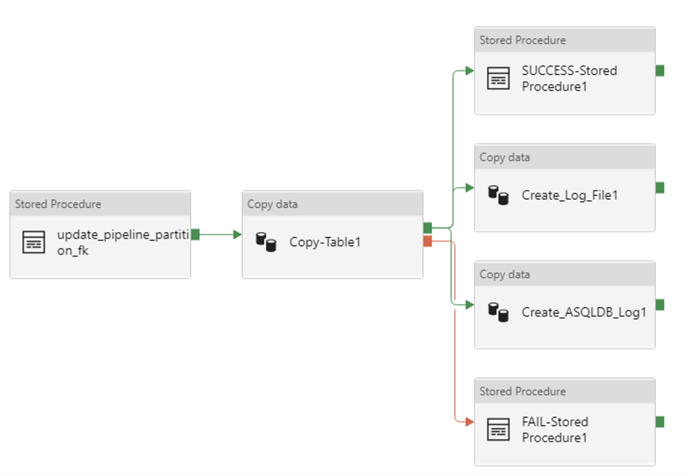
ForEach Loop Activity – Stored Procedure
The stored procedure is designed to pipeline_parameter_partition table with the pipeline_parameter's ID column based on a join of the source name from both tables.
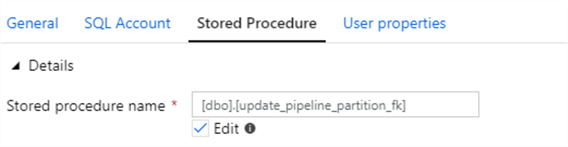
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO -- ============================================= CREATE PROCEDURE [dbo].[update_pipeline_partition_fk] AS BEGIN UPDATE pipeline_parameter_partition SET pipeline_parameter_partition.pipeline_parameter_id = p.ID FROM pipeline_parameter_partition pp INNER JOIN pipeline_parameter p ON pp.src_name = p.src_name END GO
1) pipeline_parameter Table:
I have two records in my pipeline parameter table. ID = 32 from my pipeline_parameter table is my partitioned table since it contains matching records in the pipeline_parameter_partition table where pipeline_parameter_partition.src_name = pipeline_parameter.src_name:
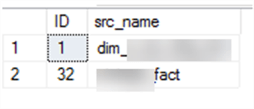
2) pipeline_parameter_partition Table:
After running the stored procedure, we can see that the pipeline_parameter_id has been updated in the pipeline_parameter_partition:

ForEach Loop Activity – Copy Data
The copy data activity will run a query to lookup the table where the partition field is between the partition watermark start and partition watermark end fields.
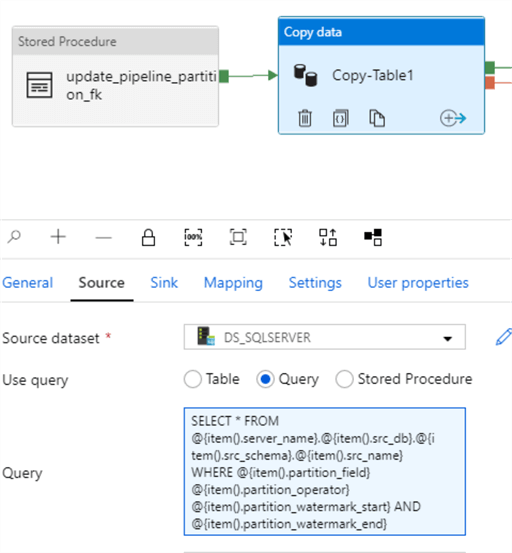
SELECT * FROM @{item().server_name}.@{item().src_db}.@{item().src_schema}.@{item().src_name}
WHERE @{item().partition_field} @{item().partition_operator} @{item().partition_watermark_start} AND
@{item().partition_watermark_end}
Pipeline Datasets
As a refresher from previous articles, the sink contains the following dataset properties:
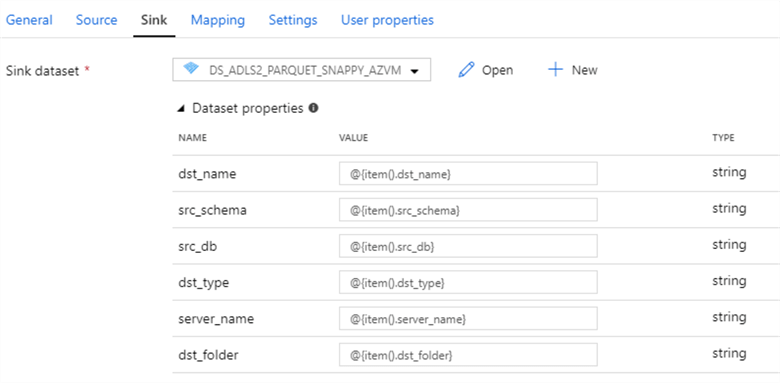
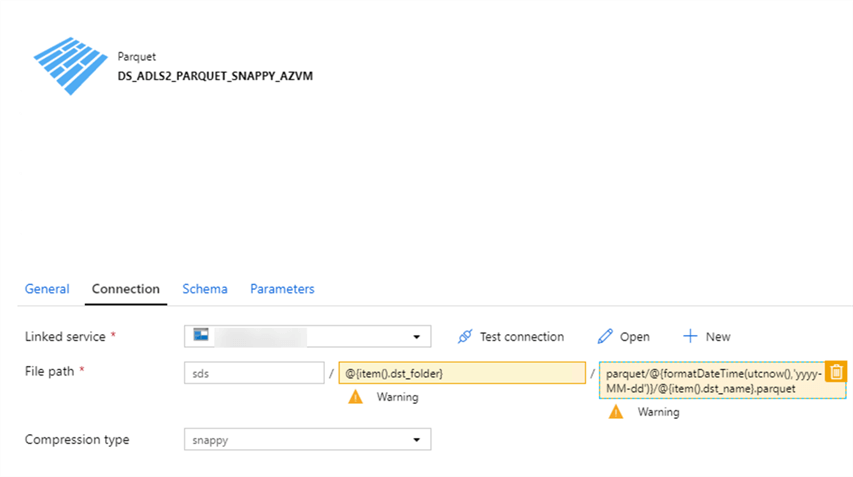
And the sink dataset connection properties resemble the following:
Pipeline Results
After the pipeline completes running, all activities have succeeded.
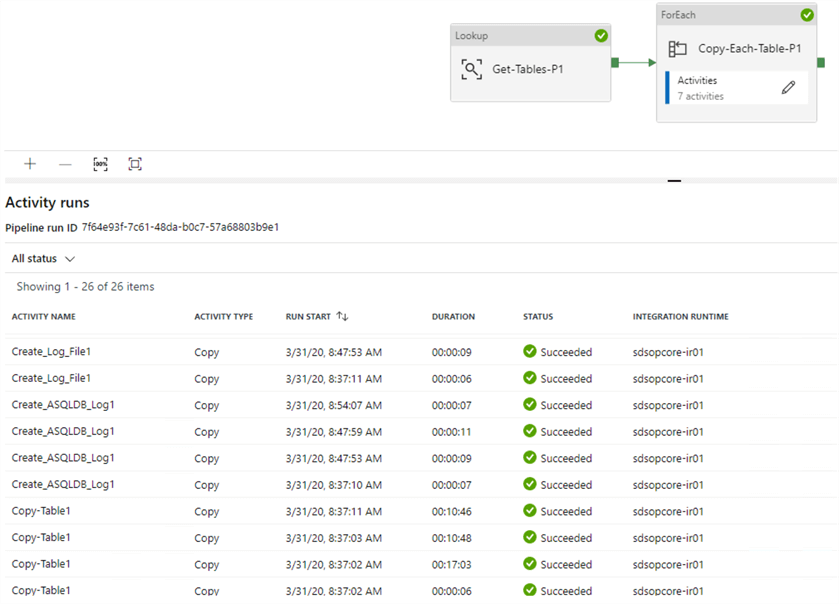
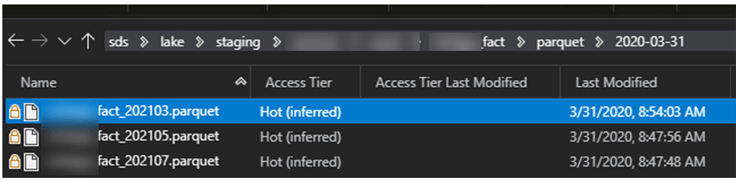
Upon looking through the destination Data Lake folders, we can see that there are four total files that have been generated.
There is one parquet file for the non-partitioned table.

And there are three parquet files for the three different partitions that have been defined in the pipeline_parameter_partition table.
Next Steps
- For more information on how to write a SQL Query to create a range of partitions on the source SQL Server table that can then be used to populate the pipeline_parameter_partition table, see this excellent MSSQLTips article: Partitioning Data in SQL Server without using Partitioned Tables.
- For more information on writing SQL Queries to select all if the parameter is NULL see, SQL Query to Select All If Parameter is Empty or NULL.
- For more information on writing SQL Queries to ignore the WHERE clause when NULL, see SQL ignore part of WHERE if parameter is null.
- For more information on writing SQL Queries to combine a UNION and an INNER JOIN, see How to combine UNION and INNER JOIN?
- For more information on optimizing the ADF Copy activity performance, see Copy activity performance optimization features
- For more detailed information on troubleshooting performance and tuning of the ADF Copy activity, see Copy Activity performance and tuning guide.






About the author
 Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master’s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tec
Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master’s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tecThis author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
