By: Greg Robidoux | Updated: 2021-08-05 | Comments (14) | Related: > Identities
Problem
One nice feature of SQL Server that is used quite a bit is the use of identity columns. This function gives you a simple way of creating a unique value for every row in your table. Adding a new column and making it an identity column is an easy thing to do as well as dropping an existing column that is an identity column, but how can you modify an existing column to make it an identity column or remove the identity property from an existing column?
Solution
Not sure how much you have researched this one so far, but there is no easy way to do this. By design there is no simple way to turn on or turn off the identity feature for an existing column. The only clean way to do this is to create a new column and make it an identity column or create a new table and migrate your data.
Let's take a look at a few examples:
Example 1
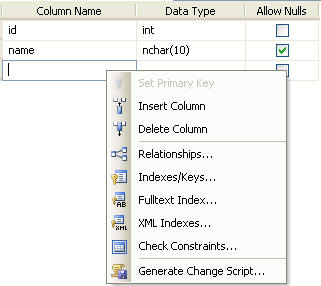
Here is a simple table that has two columns and one column is the identity column.
CREATE TABLE [dbo].[Test1]( [id] [int] IDENTITY(1,1) NOT NULL, [name] [nchar](10) NULL )
If we use SQL Server Management Studio to get rid of the identity value on column "id", a new temporary table is created, the data is moved to the temporary table, the old table is dropped and the new table is renamed. This can be seen in the script below.
To get this script use SQL Server Management Studio to make the change and then right click in the designer and select "Generate Change Script".
/* To prevent any potential data loss issues, you should review this
script in detail before running it outside the context of the database designer.*/
BEGIN TRANSACTION
SET QUOTED_IDENTIFIER ON
SET ARITHABORT ON
SET NUMERIC_ROUNDABORT OFF
SET CONCAT_NULL_YIELDS_NULL ON
SET ANSI_NULLS ON
SET ANSI_PADDING ON
SET ANSI_WARNINGS ON
COMMIT
BEGIN TRANSACTION
GO
CREATE TABLE dbo.Tmp_Test1
(
id INT NOT NULL,
name NCHAR(10) NULL
) ON [PRIMARY]
GO
IF EXISTS(SELECT * FROM dbo.Test1)
EXEC('INSERT INTO dbo.Tmp_Test1 (id, name)
SELECT id, name FROM dbo.Test1 WITH (HOLDLOCK TABLOCKX)')
GO
DROP TABLE dbo.Test1
GO
EXECUTE sp_rename N'dbo.Tmp_Test1', N'Test1', 'OBJECT'
GO
COMMIT
Example 2
If we make this example a little more complicated, by having a primary key and creating a second table with a foreign key constraint referencing back to the first table we can see that even more work needs to be done.
CREATE TABLE [dbo].[Test1]( [id] [int] IDENTITY(1,1) NOT NULL, [name] [nchar](10) NULL, CONSTRAINT [PK_Test1] PRIMARY KEY CLUSTERED ( [id] ASC )) GO CREATE TABLE [dbo].[Test2]( [id] [int] NULL, [name2] [nchar](10) NULL ) ON [PRIMARY] GO ALTER TABLE [dbo].[Test2] WITH CHECK ADD CONSTRAINT [FK_Test2_Test1] FOREIGN KEY([id]) REFERENCES [dbo].[Test1] ([id]) GO ALTER TABLE [dbo].[Test2] CHECK CONSTRAINT [FK_Test2_Test1] GO
If we do the same thing and use SQL Server Management Studio to get rid of the identity value on column "id" in table "test1" and script out the change, we can see that even more steps need to take place.
- First a temp table "Tmp_Test1" is created with the correct column attributes
- The data is moved to "Tmp_Test1" from "Test1"
- The FK constraint on "Test2" is dropped
- Table "Test1" is dropped
- Table "Tmp_Test1" is renamed to "Test1"
- The primary key is created on table "Test1"
- And lastly the FK constraint is recreated on table "Test2". That's a lot of steps.
/* To prevent any potential data loss issues, you should review this
script in detail before running it outside the context of the database designer.*/
BEGIN TRANSACTION
SET QUOTED_IDENTIFIER ON
SET ARITHABORT ON
SET NUMERIC_ROUNDABORT OFF
SET CONCAT_NULL_YIELDS_NULL ON
SET ANSI_NULLS ON
SET ANSI_PADDING ON
SET ANSI_WARNINGS ON
COMMIT
BEGIN TRANSACTION
GO
CREATE TABLE dbo.Tmp_Test1
(
id INT NOT NULL,
name NCHAR(10) NULL
) ON [PRIMARY]
GO
IF EXISTS(SELECT * FROM dbo.Test1)
EXEC('INSERT INTO dbo.Tmp_Test1 (id, name)
SELECT id, name FROM dbo.Test1 WITH (HOLDLOCK TABLOCKX)')
GO
ALTER TABLE dbo.Test2
DROP CONSTRAINT FK_Test2_Test1
GO
DROP TABLE dbo.Test1
GO
EXECUTE sp_rename N'dbo.Tmp_Test1', N'Test1', 'OBJECT'
GO
ALTER TABLE dbo.Test1 ADD CONSTRAINT
PK_Test1 PRIMARY KEY CLUSTERED
(
id
) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
COMMIT
BEGIN TRANSACTION
GO
ALTER TABLE dbo.Test2 ADD CONSTRAINT
FK_Test2_Test1 FOREIGN KEY
(
id
) REFERENCES dbo.Test1
(
id
) ON UPDATE NO ACTION
ON DELETE NO ACTION
GO
COMMIT
The same holds true if we want to change an existing column and make one of the columns an identity column. This scenario is probably less likely, but there may be a need.
Other Approaches
Another approach would be to add a new column and make it an identity column or add a new column without the identity property and migrate the data from the old column to the new column. After that you could drop the old column and then rename the column using the sp_rename stored procedure. If you have indexes, foreign keys and other constraints on these columns you would still need to drop these prior to making the changes, so this approach is not much faster.
As you can see there really is not any easy way to do this. There are some other approaches that you can find on the internet that modify values in the system tables. These approaches do work, but if you make a mistake you could totally mess up your data, so make sure you understand what is in store before modifying system tables.
I wish there was a simpler way of turning on and turning off the identity property. For small tables or for databases that are not that busy this approach works without much issue. But if you have large tables or your databases are very busy it is kind of hard to drop constraints and tables on the fly like this.
Next Steps
- Now that we have seen there is no easy way to do this, keep this in mind when designing your tables. Identity columns are great, but if you do need to change one it could be more painful then you think.
- Try to avoid using identity columns as your primary key and for foreign key constraints just for this reason. I know once you start using them it is difficult to stop using them, but be aware of potential issues you may face down the line.






About the author
 Greg Robidoux is the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server. He is also one of the co-founders of MSSQLTips.com. Greg has been working with SQL Server since 1999, has authored numerous database-related articles, and delivered several presentations related to SQL Server. Before SQL Server, he worked on many data platforms such as DB2, Oracle, Sybase, and Informix.
Greg Robidoux is the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server. He is also one of the co-founders of MSSQLTips.com. Greg has been working with SQL Server since 1999, has authored numerous database-related articles, and delivered several presentations related to SQL Server. Before SQL Server, he worked on many data platforms such as DB2, Oracle, Sybase, and Informix.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-08-05
