By: Brent Shaub | Comments (19) | Related: > Data Types
Problem
Frequently surveys ask yes/no questions and use a bit datatype. What are the effects of allowing this column to be NULL in a SQL Server table? Check out this tip to learn more.
Solution
The bit's ability to store a NULL gives it a fundamental third value needing no additional storage space. Using NULL to denote the survey question was read, but not answered is logical. Like 1 and 0, the value of NULL must be used consistently. The existence of a record in survey results differentiates "I saw the question and decided to skip it" from "the system never asked me that question".
Proper Data Retrieval with NULL Columns
NULL is a funny animal in the SQL kingdom; it uses a different syntax in the WHERE clause for queries. Below are two examples.
NULL is not equal to anything, not '' nor even NULL. This query will always return 0 records.
select count(question1) as count_na from survey_answers where question1 = NULL
The correct syntax is:
select count(question1) as count_na from survey_answers where question1 IS NULL
As an alternative, the ISNULL(<column>, value) function will supply the value of the second parameter if the value of the column in the first parameter is NULL. Keep in mind that the supplied value must be of the same datatype. If using ISNULL with a bit and needing a third non-null value, use something like ISNULL(CAST(<column> as tinyint), 2). The choice of the value i.e. 2 and the data type i.e. tinyint can be changed to best suit your situation. ISNULL is handy for sorting NULLs where they appear best. Supplying -1 or the highest value + 1 will left or right justify rows with NULLs. Supplying a value for ISNULL that's between other columns' values places them in the middle. Outputting a message like "None found" is a common use too.
NULL Storage Space Considerations in SQL Server
Bits ties tinyint and char in using one byte. Why a byte when a bit is an eighth of one? If a table has one bit, SQL allocates an entire byte. As other bits are defined, they use the other bits; up to eight bit fields total. When creating a ninth bit, a second byte is used, and creating a seventeenth will use a the first bit in a third byte.
Aggregating Data
Here is a sample data model for our survey application:
|
Survey ERD |
|---|
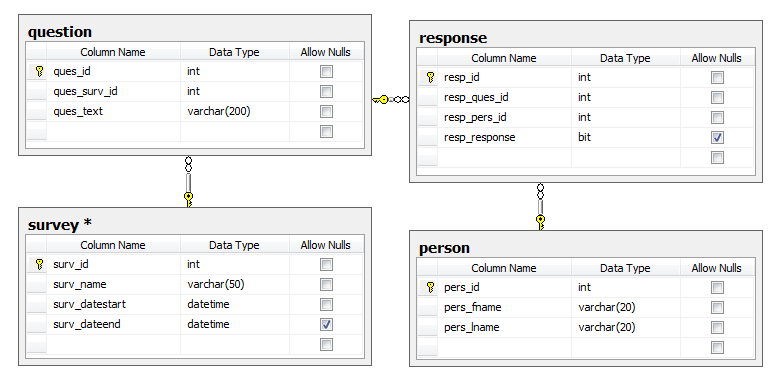 |
Using the schema above, here is a query to count the responses by question:
select coalesce(yesses.resp_ques_id, nos.resp_ques_id, nas.resp_ques_id) ques_id, isnull(yesses.yes, 0) yes, isnull(nos.no, 0) [no], isnull(nas.na, 0) na from (select resp_ques_id, count(1) as yes from response where resp_response = 1 group by resp_ques_id ) yesses left outer join (select resp_ques_id, count(1) as no from response where resp_response = 0 group by resp_ques_id ) nos on yesses.resp_ques_id = nos.resp_ques_id left outer join (select resp_ques_id, count(1) as na from response where resp_response is null group by resp_ques_id ) nas on nas.resp_ques_id = nos.resp_ques_id
Here are the sample data:
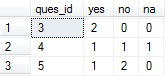
This query will scale for any number of questions in a survey. To filter by a survey, simply add a join in each sub query from response to question with an AND ques_surv_id = x.
Next Steps
- For any situation with three possible values, the bit datatype can be utilized by leveraging NULL as a logical value.
- If "not answered" and "not applicable" need stored along with "yes" and "no", a char or tinyint becomes necessary.
- Detecting NULLs requires a special syntax in the WHERE clause: IS [NOT] NULL.
- ISNULL() can be used to make output more readable by replacing a NULL value with a logical business term.
- In a high-volume scenario, having multiple bits in place of char or tinyint will make a difference.
- Counting bit fields' values utilizes three sub queries, one for each value.
- Become familiar with NULL in T-SQL. Review IS [NOT] NULL and ISNULL().
- Decide if using bit fields in your system would save disk space while maintaining readability.






About the author
 Brent Shaub has been creating, renovating and administering databases since 1998.
Brent Shaub has been creating, renovating and administering databases since 1998.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
