By: Arshad Ali | Comments (5) | Related: 1 | 2 | 3 | 4 | > Data Quality Services
Problem
In my earlier tips, I talked about the Data Quality Service (DQS) in SQL Server 2012, which helps ensure data integrity and quality by data profiling, matching, cleansing, correcting and monitoring overall status of the data cleansing process. We also talked about using the interactive Data Quality Client tool and in this tip we will walk through how to do data cleansing in a automated mode.
Solution
Data Quality Service (DQS) has a SSIS component which you can use for automating the data cleansing process or if you want to run it in batch mode (versus interactively in the Data Quality Client tool).
Before you can start using the Data Cleansing component in SSIS, you need to make sure you have already created and published a knowledge base for cleansing your source data. To learn more about the knowledge base or knowledge discovery and the process of creating a knowledge base, refer to my earlier tip in this series.
Please note, this data cleansing component is a SSIS component which can be installed and run on the same machine or on a different machine than the DQS server. This component works like a client and requires DQS Server for performing data cleansing operations. To learn more about DQS installation and configuration, please refer to my first tip in this series.
As you can see below, the SSIS component reads data from the source, sends it to the DQS Server for data cleansing and correction and writes the output to the destination. It also includes additional columns to indicate whether the value was already correct, was corrected by DQS, if any other value was suggested or the value was an invalid/unknown value.
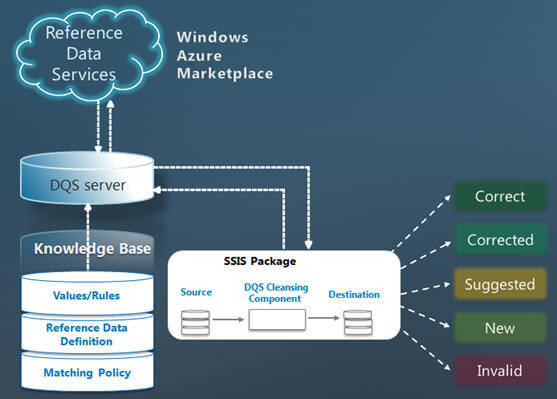
Getting started with the DQS cleansing component in SSIS
I am assuming you have basic understanding of SSIS and you are aware of how to create a simple package in SSIS, if not please refer to this tutorial.
Create a SSIS package and drag a data flow task from the Toolbox on to the Control Flow; double click on data flow task to open the task in data flow pane. In the Toolbox of the data flow pane you will notice a new component (DQS Cleansing) appears as shown below:
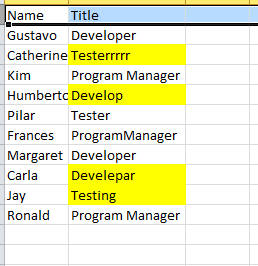
Before we begin using this component, we need to first select/specify the data source which needs to be cleansed, in my case I have a csv file (incorrect values have been highlighted here for clarity) with this data, which I want to cleanse, as shown below:
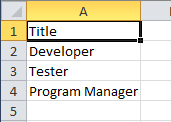
In this example I am going to use the same knowledge base (TitleDomain) which I created in my last tip of this series and which has these entries, as shown below, for valid Title domain:
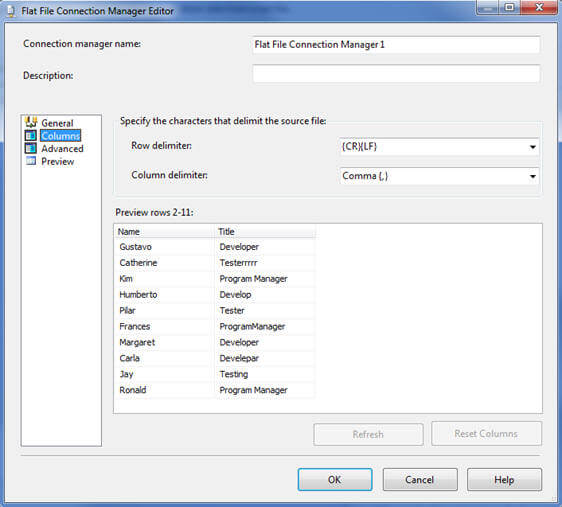
Now coming back to the data source for data cleansing, I have defined a flat file connection manager as shown below, for the above "csv" file:
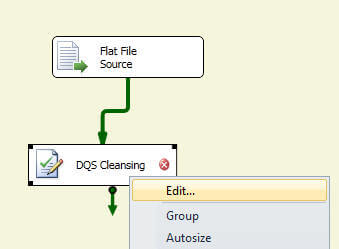
Now drag a Data Cleansing component from the Toolbox on to the data flow pane, drag the green arrow icon to the component from the flat file source and right click -> Edit on the Data Cleansing component as shown below:
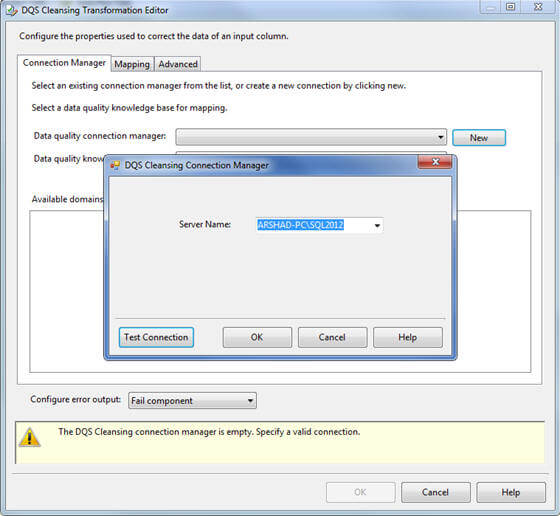
In the Connection Manager page of DQS Cleansing Transformation Editor, you need to either specify or create a new connection manager (a new type of connection manager introduced with this release to connect to DQS Server) that connects to DQS Server where you have created the knowledge base for use, you can click on the Test Connection button to verify the connection is valid:
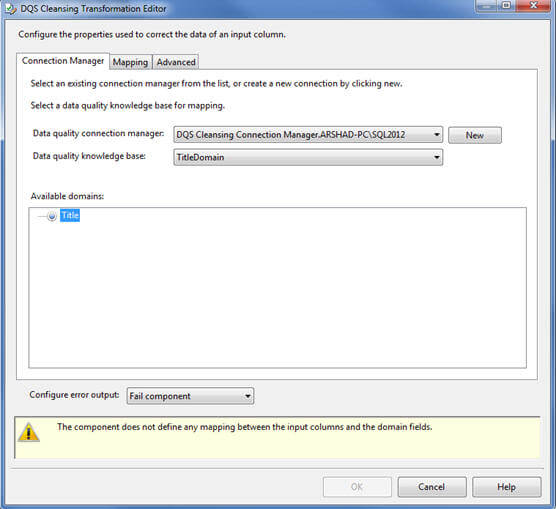
Once connected to the DQS Server, the data quality knowledge base combo-box will display all the published knowledge bases available on the DQS Server. Select the appropriate one and then go to the Mapping page:
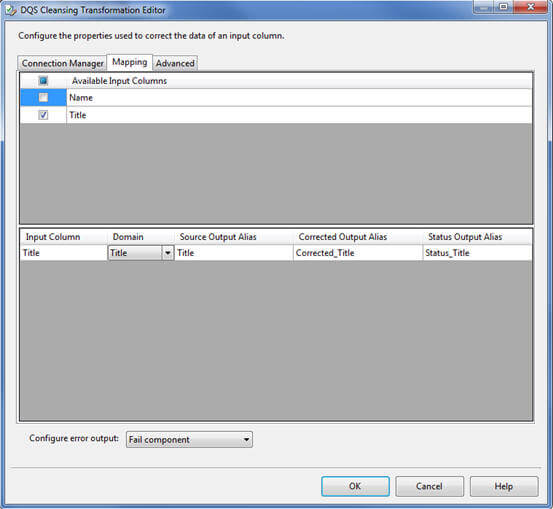
On the Mapping page, select the source/input columns to be cleansed and select the appropriate domain (will be contained in the knowledge base which you selected in last step) for each column in the bottom grid as you can see below. I want to cleanse the Title column of the source and hence I have selected the Title domain (available in the knowledge base) to be used for cleansing the incoming titles:
The DQS Cleansing component adds a column called [Record Status] which indicates what operation has been taken by the DQS Server for each value. For example, if the value was already correct or corrected by DQS; if not then if there is any suggestion or it is invalid for the domain or an unknown value which is not in the domain and does not match with the domain rules:
![The DQS Cleansing component adds a column called [Record Status]](/tipimages2/2593_imgE.jpg)
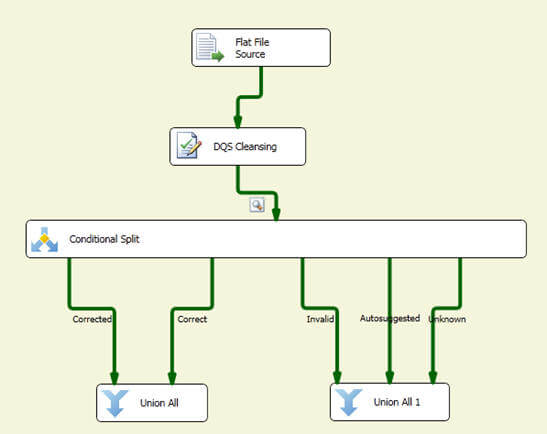
You need to use a Conditional Split Transformation for splitting the output from the DQS Cleansing component based on the values of the [Record Status] column as shown below. Correct and Corrected values can be combined together (using Union All Transformation) and written directly to the destination whereas Autosuggested, Invalid or Unknown values can be combined and written to an intermediate table, so those values can be manually fixed before writing to the destination (or the knowledge base can be enhanced to include these additional values or updated for existing values so that manual fixing can be minimized):
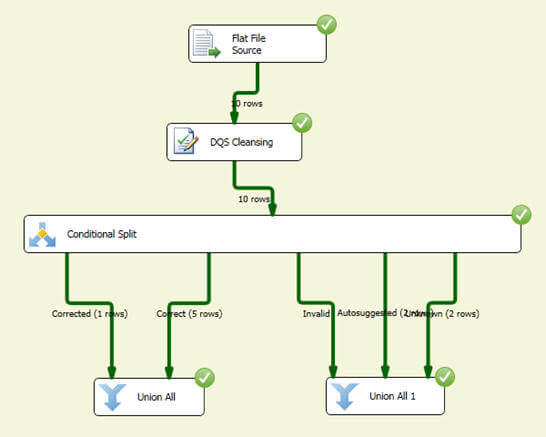
When you run the above package, you will notice that 10 records come from the source, out of the 10 records, five are correct, one gets corrected, two are autosuggested and two values are unknown as shown below:
In this tip, I demonstrated how you can use the SSIS transformation component to do data cleansing in a batch/automated mode. If you want to learn more about creating a knowledge base and doing the cleansing in an interactive mode using the Data Quality Client tool, refer to my earlier tips in the series.
Please note, the details and examples in this tip are based on SQL Server 2012 CTP 3, there might be some changes in the final release of the product.
Next Steps
- Review Introducing Data Quality Services article on msdn
- Review Data Quality Services "How Do I?" Videos on msdn
- Review DQS Cleansing Transformation on msdn blog






About the author
 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
