By: Derek Colley | Comments (3) | Related: > Dynamic SQL
Problem
You have a task to undertake the scripting out of many individual T-SQL statements. For example, you need to rename a number of SQL Server database files. You need to automate the creation of T-SQL statements rather than manually script out the solution. How can you do so? Check out this tip to learn more.
Solution
You can use techniques such as dynamic SQL to create multitudes of statements, passing in parameters from known tables as input. This can save much typing and reduce errors in scripting significantly. For this tip, I'll be demonstrating an example where this can come in handy, using set-based (SELECT) conditional logic to intelligently produce code.
Recently, I was facing a requirement to rename 70 database files from their current form of "drive:\folder\subfolder\dbname_n.xdf", where "n" ranged from 1-70, "xdf" varied between mdf/ndf/ldf, there were 8 filegroups, and the path varied depending on the filegroup in which the database file was located. Very quickly, I realized this was a mammoth manual scripting task. By hand, I would have to:
- Query sys.database_files (name, physical_name) to find the current physical names
- Take the database offline
- For each file, issue an ALTER DATABASE
MODIFY FILE ( FILE = 'name', FILENAME = 'physical_name'); statement - Manually rename each file (i.e. by GUI, or using 'rename x y' syntax in a Command Window)
- Bring the database online
- Verify the files are in the correct locations
This amounts to at least 140 lines of similar code and much eyeballing of 'before/after' file paths to ensure these are correct. This has a couple of disadvantages - through typos or human error, I could inadvertently point a file record to a physical location that doesn't exist (have you ever done this in production? I have. Scary moment). I could miss one or more files. And, of course, this takes time, even with the magic of copy and paste.
There are a couple of tricks one can use. One of my colleagues uses Excel to auto-fill columns full of SQL commands, but this still takes work when coding individual parameters. The technique below, which I'll examine part-by-part, will show one method of doing it in T-SQL. Here's the build script - a simple CREATE DATABASE statement with the primary filegroup and three tertiary filegroups, and a single log file. For clarity, I've omitted additional options like SIZE, MAXSIZE etc., and the defaults will be used. Replace 'C:\del' with your working directory. You'll need to create the subfolders 'TestDB', 'TestDB\Data' and 'TestDB\Logs':
CREATE DATABASE TestDB ON PRIMARY ( NAME = 'TestDB_Primary', FILENAME = 'c:\del\TestDB\Data\Datafile_1.mdf' ), FILEGROUP FG_1 ( NAME = 'TestDB_FG_1_1', FILENAME = 'c:\del\TestDB\Data\Datafile_2.mdf' ), ( NAME = 'TestDB_FG_1_2', FILENAME = 'c:\del\TestDB\Data\Datafile_3.ndf' ), FILEGROUP FG_2 ( NAME = 'TestDB_FG_2_1', FILENAME = 'c:\del\TestDB\Data\Datafile_4.mdf' ), ( NAME = 'TestDB_FG_2_2', FILENAME = 'c:\del\TestDB\Data\Datafile_5.ndf' ), FILEGROUP FG_3 ( NAME = 'TestDB_FG_3_1', FILENAME = 'c:\del\TestDB\Data\Datafile_6.mdf' ), ( NAME = 'TestDB_FG_3_2', FILENAME = 'c:\del\TestDB\Data\Datafile_7.ndf' ) LOG ON ( NAME = 'TestDB_Log', FILENAME = 'c:\del\TestDB\Logs\TransactionLog.ldf' ) GO
Now, the logical file names are straightforward - each file is named appropriately, and one can look in the folder and see the physical files. However, the physical files are named arbitrarily and this can make it difficult to reconcile each file to the appropriate file group. It's relatively easy to use T-SQL to do this:
USE TestDB SELECT df.name [logical_name], df.physical_name, fg.[name] [filegroup_name] FROM sys.database_files df INNER JOIN sys.filegroups fg ON df.data_space_id = fg.data_space_id ORDER BY fg.data_space_id ASC, df.file_id ASC
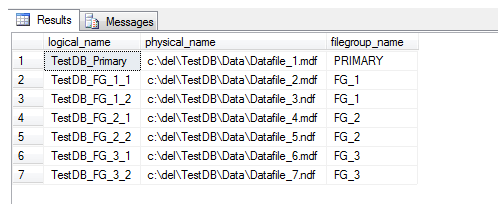
However it's neater and consistent with best practices to have meaningful filenames. Here's the crux of the code which will produce the code to rename the physical files to their logical names:
SELECT 'ALTER DATABASE ' + CAST(DB_NAME() AS VARCHAR(50)) + ' MODIFY FILE ( NAME = ' +
QUOTENAME(df.[name],'''') + ', FILENAME = ''' +
SUBSTRING(df.[physical_name], 1,
LEN(df.[physical_name]) - CHARINDEX('\',REVERSE(df.[physical_name])) + 1 ) +
df.[name] + CASE
WHEN df.type_desc = 'ROWS' AND df.file_id = 1 THEN '.mdf'' )'
WHEN df.type_desc = 'LOG' THEN '.ldf'' )'
WHEN df.type_desc = 'ROWS' AND df.file_id != 1 THEN '.ndf'' )'
END
FROM sys.database_files df
Note this code doesn't take into account FILESTREAM and FULLTEXT (pre-2012) types in the type_desc column of sys.database_files. I'm not using these features in the demo, but feel free to amend the CASE block accordingly. I'm also assuming your file_id for the main DB file in the PRIMARY filegroup is 1 - check and amend if using this code for your databases.
When I run the above against my newly-created TestDB, I get:
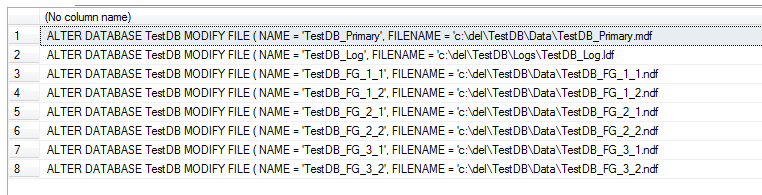
Thus I have renamed my physical files to match my logical names. I will step through the snippet above line-by-line to explain what's going on:
SELECT 'ALTER DATABASE ' + CAST(DB_NAME() AS VARCHAR(50)) + ' MODIFY FILE ( NAME = ' +
This line gets the current database context (DBNAME()) and casts it into a string concatenation to build the initial part of the string. Given that sys.database_files in the FROM clause is database context-dependent (i.e. different results are returned depending on which context you are in), DB_NAME(), which is also context-dependent, is safe to use.
QUOTENAME(df.[name],'''') + ', FILENAME = ''' +
Two methods of inserting quotes into quoted strings are demonstrated here - QUOTENAME, which enables one to specify two parameters - the expression to quote, and the character to use. It is also possible to specify a quote using a 'quoted quote', i.e. ''', as above.
SUBSTRING(df.[physical_name],1,LEN(df.[physical_name])-CHARINDEX('\',REVERSE(df.[physical_name]))+1)
This is rather complicated. Starting from the innermost expressions, the physical name of the file is reversed and the CHARINDEX string function is used to identify the first occurrence of '\' from the left. This returns a string position for the LAST occurrence of '\' in the physical name (once reverted to normal). This is necessary since CHARINDEX does not enable directional specification (although something might be possible by switching collation?).
Now we have the position of the last '\', we can surmise everything before that (from position 1 to this position) is the drive and path, and everything afterwards is the file name. So now we need to get the substring of the physical path from position 1 to this position to derive the drive and path, with all subfolders. The filename is going to be replaced so is of no use to us and can be discarded. The + 1 at the end simply reads an additional character into the SUBSTRING, the final '\', so we can append the df.[name] value directly without hardcoding another '\'.
If this seems confusing, read through the line, and dry-run through the functions with a pen and paper starting with REVERSE, then CHARINDEX, then LEN and finally SUBSTRING, and you will see how this works regardless of number of subfolders, drive letter or path variations. Note the CHARINDEX return value and SUBSTRING position parameter are out by +/- 1 since the former is 1-indexed, and the latter 0-indexed, which is why the final '\' doesn't appear in the output despite it's position being explicitly specified.
df.[name] + CASE
WHEN df.type_desc = 'ROWS' AND df.file_id = 1 THEN '.mdf'' )'
WHEN df.type_desc = 'LOG' THEN '.ldf'' )'
WHEN df.type_desc = 'ROWS' AND df.file_id != 1 THEN '.ndf'' )'
END
This block appends the logical file name to the string we are creating (after the aforementioned drive:path), then makes a decision on the file extension based on the attributes of the file in the row. If the file_id is 1, and the type_desc in sys.database_files is 'ROWS', it's likely (note: not guaranteed!) that this is the primary datafile, so it merits extension '.mdf'. Likewise if the type_desc describes the file as 'LOG', it's going to be a transaction log file and gets extension '.ldf'. Finally, if the file_id is NOT equal to 1 and of type_desc 'ROWS', it's named as a '.ndf'. BE CAREFUL - as stated before this example doesn't take into account full-text indexes or filestream attributes. You may wish to amend this conditional logic to deal with this.
FROM sys.database_files df
This is the source of the datafile information, and is a context-dependent view. If you wish to work from another DB context (e.g. master), you can specify the database name prior to 'sys' but you must hard-code the database name in line 1 rather than using DB_NAME().
Next, we need to create the rename script. This is simpler:
SELECT 'rename ' + df.[physical_name] + ' ' + df.[name] + CASE WHEN df.type_desc = 'ROWS' AND df.file_id = 1 THEN '.mdf' WHEN df.type_desc = 'LOG' THEN '.ldf' WHEN df.type_desc = 'ROWS' AND df.file_id != 1 THEN '.ndf' END FROM sys.database_files df
It builds the rename string dynamically, and uses identical CASE logic to our first code block.
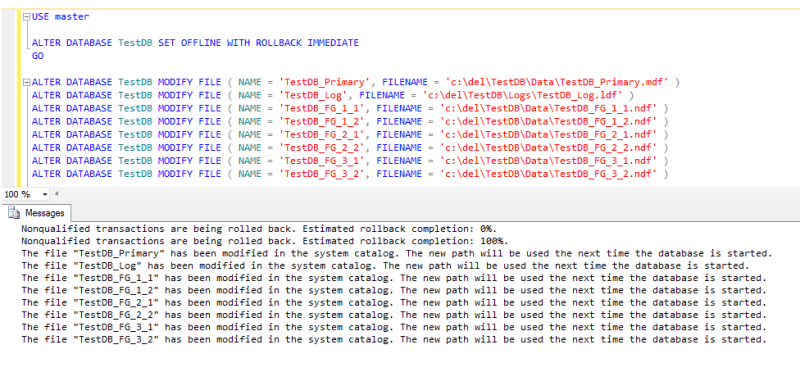
Finally, we need to set the database offline; execute the first code block and copy/paste the output to a new window; execute the output from our first code block; execute the second code block and copy/paste the output to a new batch file; execute the output from our second code block in a command window; and bring the database back online, like so:
Take the SQL Server Database Offline and Modify the File Path
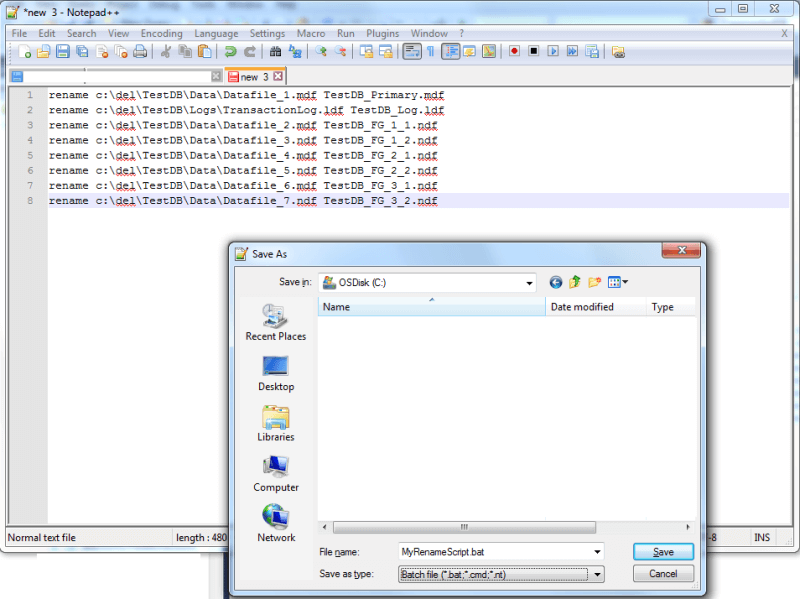
Create the *.bat file to Rename SQL Server Database Files
Execute the *.bat File to Rename the SQL Server Databases
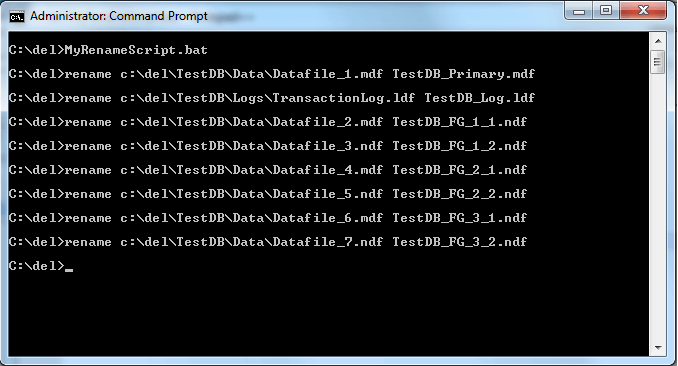
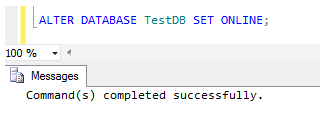
Bring the SQL Server Database Online
Next Steps
- For further reading on using dynamic SQL in SQL Server, please consult
the following sources:
- 'Execute Dynamic SQL commands in SQL Server' - Greg Robidoux, mssqltips.com http://www.mssqltips.com/sqlservertip/1160/execute-dynamic-sql-commands-in-sql-server/
- 'Generate Dynamic SQL Statements in SQL Server' - Tim Chapman, TechRepublic http://www.techrepublic.com/blog/the-enterprise-cloud/generate-dynamic-sql-statements-in-sql-server/
- Check out all of the Dynamic SQL Tips on MSSQLTips.com.






About the author
 Derek Colley is a UK-based DBA and BI Developer with more than a decade of experience working with SQL Server, Oracle and MySQL.
Derek Colley is a UK-based DBA and BI Developer with more than a decade of experience working with SQL Server, Oracle and MySQL.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
