By: Tim Smith | Comments | Related: More > Import and Export
Problem
We've experience inaccurate information that came from APIs we use and we initially tried to approach our API alerting where we had alerts fire if we felt values were inaccurate, but these alerts became constant and our developers learned to ignore them. Unfortunately, there are many situations that we need to know immediately if a data value from an API is wrong, but this seems to be more difficult than it sounds. Are there any best practices you recommend for API alerting?
Solution
In extracting data from many APIs, I have discovered situations where I receive incorrect or questionable information from pieces of the data and in some cases from the full data set (the below image is from an API that reported bitcoin's price as $0.00 for four minutes while the other APIs reflected the accurate price estimate).
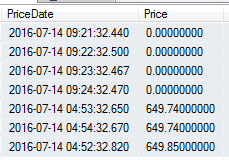
No API is the same, even if the structure is similar - they all tend to have behavioral characteristics. Anyone who has built APIs knows that this can happen and those who rely on the data must be aware of the ins and outs of the effects of this inaccurate data. When you extract from an API, at the least, you should know the following:
- The purpose of the data.
- The logic for the data.
- The final user of the data.
Purpose
No data are superior to inaccurate data, unless inaccurate measurements are intended for testing or demonstrative purposes (like the above image - which was incorrect data - is being used for a point). In the above example, if the purpose was for a minute-by-minute price for an urgent buyer, we'd have to use data from other sources and exclude this API in this case; if the data are used for aggregating an overall price estimate, this simply is excluded from the aggregate for these four minutes. The purpose affects how we respond and how we alert; for some APIs, we may need to contact the people who created and maintain it before alerting (is it wrong, is our application wrong?). In other cases, like weather data, we may build exceptional ETL processes that import the correct or updated data when it's available (economic data can often be updated, retracted, etc.), so alerting may not be required because it can be handled later.
Logic
Using the above example and a situation where I want other data sources checked prior to an alert, if I aggregate a price from multiple sources every five minutes, I might create a check for extreme values to prevent the above from being included in the aggregate:
DECLARE @max DECIMAL(27,9), @min DECIMAL(27,9) ---- The 1.2 gives the max range a higher range than the aggregate, as prices could have risen SELECT @max = (MAX(Price)*1.2) FROM tblAggregate WHERE PriceDate BETWEEN DATEADD(MINUTE,-6,GETDATE()) AND GETDATE() ---- The .8 gives the minimum range a lower range than the aggregate, as prices could have dropped SELECT @min = (MIN(Price)*.80) FROM tblAggregate WHERE PriceDate BETWEEN DATEADD(MINUTE,-6,GETDATE()) AND GETDATE() ;WITH FilterExtremes AS( SELECT AVG(Price) Price FROM tblBitcoinAPIOne WHERE PriceDate BETWEEN DATEADD(MINUTE,-5,GETDATE()) AND GETDATE() ---- Filter extremes, which I'm defining as inaccurate with this logic AND Price BETWEEN @max AND @min ) INSERT INTO tblAggregate (PriceDate,Price) SELECT GETDATE() , Price FROM FilterExtremes
The rules that I would define for alerting in this case would be if multiple sources of data had extreme values (the alert would use the tblAggregate not tblBitcoinAPIOne). While I know the API in the above example returned the incorrect information (its futures had a correct value - so this was an API error), it is possible that outlier values could occur with other APIs, so we should make sure that we know the data well enough to be able to define strict rules, like the above example. It is possible that an extreme value is legitimate. Let's suppose that the $0.00 values were legitimate - in many cases, we would want to know immediately if there was an extreme value. Instead of waiting until we get into the database layer for alerting (the ETL process can still extract the data), we could alert and save the value. In the below example, if the price is above $5000 or if the price is below $60, it sends an email and adds a value, while if the price is between the range, it simply adds the value.
if (($price -lt 5000) -and ($price -gt 60))
{
### Add data value
Execute-Sql -command $command
Write-Host $price
}
else
{
### Alert and add data value
Send-MailMessage -to $to -from $from -smtpserver $smtp -subject $subject $body $body -BodyAsHtml
Execute-Sql -command $command
}
The first point - purpose - is important here because we don't want a noisy ETL process when we know that a particular API may have these blips, such as an API that extracts server performance metrics from a list of servers. If it requires immediate action, build the logic as close to the call as possible, otherwise, wrap logic inside the database layer.
Final User
In many cases, this may be an automated process, application, or individual. The application or individual who consumes the data will determine how the final result is reported. We may simply report the data we have and exclude any inaccurate or questionable data, or we might also include how many questionable or inaccurate records we had. We may also report the total row count for the time period (like the amount of rows of data we had per day) and the amount we should have (or the difference). One of my "best practices" for numerical APIs is a daily dashboard of the count of values I received for the time period I should have received, along with the maximums, minimums, outliers, medians, etc. For alphabetic APIs, I'll often do the same, except with numerically expressed values of the alphabetic characters, such as the average length of the text, maximum, etc. These help quickly identify abnormal patterns with the API you're using, which will help build familiarity with the APIs. The key with this dashboard for APIs is that it's intended and not disruptive (the opposite of alerting - which disrupts); the idea behind my practice is that I set aside time to look and evaluate it so that I can consider the current logic, or possibly updating the logic (to quote Joe Polish, "What's measured improves; what's measured and reported improves exponentially"). Prevention always trumps cure.
Other final users of this data (not myself) may not want to see this dashboard, or may not want to see any alerts at all. We have to consider as well; if we're the developer or DBA for an individual who doesn't want to know, then we need to watch it without alerting them and sending them information that they may not care for (and vice versa if they want to know immediately).
Meaningful alerting with ETL extraction from API helps us reduce noise, while assisting with quick detection of potential problems with either data, our ETL design, or other processes that are related. We may need to contact the people behind an API, but before we do, we should have a good idea of what is normal and abnormal to help them quickly identify if there are issues.
Next Steps
- Extracting data from APIs is easy; delineating parameters and ranges for the data is not.
- Consider the purpose of the data to determine the urgency of alerting.
- Define the logic of each API and keep in mind that even if they're similar, their behavior may differ.






About the author
 Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.
Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
