By: Pablo Echeverria | Comments | Related: > Database Configurations
Problem
In this tip we’re going describe what parallelism is, the benefits, and how to take advantage of parallelism in SQL Server with some examples.
Solution
To define parallelism, there are some basic concepts we need to define:
- Throughput: The number of tasks completed per unit of time. If you have a 2-seat car (excluding the driver) that travels at 150 MPH, and a 40-seat bus (excluding the driver) that travels at 50 MPH, the car is 3x faster but in a 150-mile trip for 3 hours the bus can deliver 10x more people than the car, or if we wait for the car to deliver 40 people it takes 13x more time than the bus.
- Thread: One independent path of execution through the code. The number of simultaneous active threads is up to the number of CPU’s or cores. Note that not all threads have to follow the same path, but the throughput increases if they do.
- Multithreading/multiprocessing: The ability to execute multiple processes simultaneously. If you have a color printer, it would be cumbersome if you need to print one color at a time, times the number of pages.
- Automation: If a machine can do a task, there’s no need for you to force it working in a specific way. If you have a 4-helix airplane, it's nonsense that you iterate through each spin for each one of the helixes must make. Even if it will eventually move the plane, the plane will never take off.
Parallelism can be defined as achieving better throughput by the execution of multiple threads at the same time or the automation of tasks. It is achieved by keeping the hardware busy using a lot of threads, processing multiple items per thread, and/or performing multiple operations with the same data already in memory. By keeping the hardware busy, threads spend less time waiting on a resource that is unavailable at that moment and being forced to switch context. This is better explained in the article fully utilize all bottlenecks, from where the image below is from:
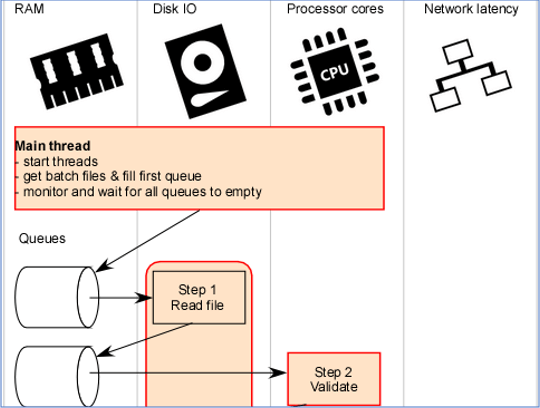
The benefits of implementing parallelism are:
- We can solve larger problems or solve more problems in less time. Usually you end up having less operations performed, or the same number of operations, but with less steps.
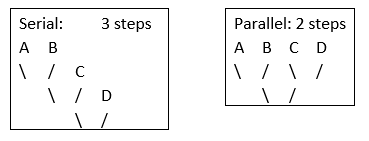
- Get a return on your investment. If you’re doing serial programming on a 4-CPU computer, the other three CPU’s are consuming power and generating heat without being needed nor used. Also, the SQL Server license is per-core, so its better if you’re using the cores for which you paid a license for.
- Increase the computing power beyond the local resources. There’s no need to have centralized software that monitors all the servers (and consuming all network bandwidth and CPU in the run) if each server can monitor itself and send alerts when appropriate consuming its local network bandwidth and CPU. And there are algorithms that can be parallelized and distributed among multiple CPU’s and/or nodes in a network. Examples of this are multi-server queries, multi-server jobs, machine learning server and GPU acceleration.
Note that parallelism is helpful for people in all IT levels:
- For managers, it helps them decide on which software to purchase, based on its capacity and computations per cycle.
- For infrastructure support, it helps them recommend the best hardware based on their characteristics and configure the virtual machines and operating systems in a way that utilizes the resources correctly.
- For database administrators, it helps them configure the database servers in a way that performs better with the existing hardware and software that is already in place.
- For developers, it helps them create programs that utilize fully and correctly the existing hardware.
Configuring SQL Server to run operations concurrently
For the operations performed inside the SQL Server engine, you must take a look at how to set the cost threshold for parallelism and the max degree of parallelism, as they may be preventing you from using parallelism. The default value of is 5, but Microsoft suggests changing it to 50 and then adjust as needed. Here is a calculator that can tell you the recommended value for MAXDOP, and here is an example on how to run a query in parallel in the engine.
Below are example query plans where one is run in parallel and the other is not.
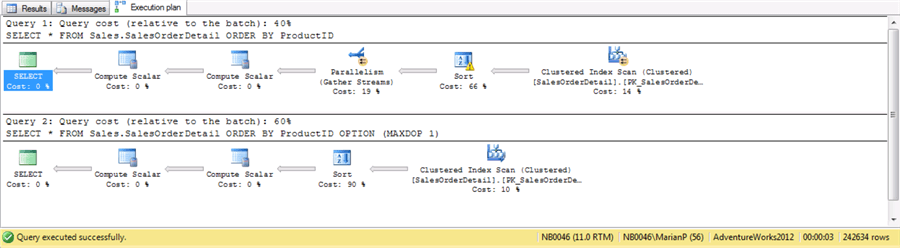
Image source: https://placko.wordpress.com/2012/06/24/parallel-query-processing-in-sql-server/
For the number of simultaneous requests sent to SQL Server instance, please note that in T-SQL you can’t create multiple threads (which is a limitation of the language) even when SQL Server can handle multiple requests in parallel, but this is doable. Here are some examples on how to do it from PowerShell, Reporting Services and Integration Services.
Below is an example in PowerShell where multiple tasks are run in parallel.


The Correct T-SQL to Work in Sets
The general advice is to not create procedural programming, instead work in sets. Let the machine determine the “how”, which is what it has been programmed for. It may not be obvious how to rewrite a query without using cursors and loops, but this is doable. When you do procedural programming (loops, recursive calls, etc.), you’re forcing it to work in a specific way that is almost never optimal, causing threads to follow different paths due to the execution of different pieces of code at the same moment, losing hardware efficiency and this finally forces the query to execute serially because of thread divergence. Check this link for additional information.
Example: For the current database, output all table names with their columns comma separated. This is easily programmed using cursors and variables, but the following query lets the engine decide how to distribute work and doesn’t require you to know the number of tables and columns beforehand, working for any database with any number of tables and columns.
SELECT o.name,
STUFF((SELECT (', ' + od.NAME)
FROM sys.columns od
WHERE od.object_id = o.object_id
ORDER BY od.column_id
FOR XML PATH('')), 1, 2, '') cols
FROM sys.objects o
WHERE o.type = 'U'
ORDER BY o.name
Example: There’s a table with historical information about disk space in each of the servers. It contains Server, Drive, Capacity, FreeSpace and DateCollected. There are 160 servers and 1380 drives among all servers, but the table has 21 million records. To get the latest information from this table, you could select the record that doesn’t have a previous record, but this means reading an average of 15 million records for every one of the 21 million rows. Instead, the following query first benefits from sub-setting the information getting the newest date, and then matching those rows to get the remaining information.
SELECT [h1].[Server], [h1].[Drive], [h1].[Capacity]/1024/1024/1024 [SizeGB], [h1].[FreeSpace]/1024/1024/1024 [FreeGB], [h1].[DateCollected]
FROM [DiskHistorical] [h1]
INNER JOIN (
SELECT [Server], [Drive], MAX([DateCollected]) [DateCollected]
FROM [DiskHistorical]
GROUP BY [Server], [Drive]) [h2]
ON [h2].[Server] = [h1].[Server]
AND [h2].[Drive] = [h1].[Drive]
AND [h2].[DateCollected] = [h1].[DateCollected]
ORDER BY [Server], [Drive]
The execution plan is as follows. Note that initially it reads 21 million records, but the information is returned in only 60 seconds even when there are no indexes defined on it, this due to the parallelism which can be seen in the execution plan below.

Example: Get information from all GAM extents DIFF map pages for the MSDB database. This is part of a bigger solution described in this link. Although you can declare a cursor to iterate through each GAM page and get the DBCC information from it, this query creates the DBCC commands to execute, letting the engine decide how to distribute work, and then runs the commands as a whole.
CREATE TABLE #DBCCPage ([Id] INT IDENTITY(1,1), [ParentObject] VARCHAR (100), [Object] VARCHAR (100), [Field] VARCHAR (100), [VALUE] VARCHAR (100))
DECLARE @Size INT, @cmd VARCHAR(MAX)
SELECT @Size = [size] FROM [sys].[master_files] WHERE [database_id] = 4 AND [file_id] = 1
SET @cmd = ''
;WITH [DBCC] AS (s;'
;WITH [DBCC] AS (
SELECT 0 [ExtentId], 'DBCC PAGE(4,1,'+CAST(6 AS VARCHAR)+',3) WITH TABLERESULTS' [Command]
UNION ALL
SELECT [ExtentId]+511232, 'DBCC PAGE(4,1,'+CAST([ExtentId]+511232+6 AS VARCHAR)+',3) WITH TABLERESULT WHERE [ExtentId] + 511232 < @Size)
SELECT @cmd = @cmd + 'INSERT #DBCCPage EXEC('''+[Command]+''');' FROM [DBCC]
EXEC (@cmd)
SELECT * FROM #DBCCPage
DROP TABLE #DBCCPageCPage
DROP TABLE #DBCCPage
Next Steps
- I invite you to think about your worst performing queries, and how those can be rewritten to benefit from sets and parallelism. A rule of thumb I always follow is that any query taking more than 30 seconds must be reviewed. This is also the same default timeout setting in most Microsoft products.
- Check this link for an example about multi-server queries.
- Check this link for an example about multi-server jobs.
- Check this link for an example about PowerShell.
- Check this link for an example about how much databases have changed since last full backup.






About the author
 Pablo Echeverria is a talented database administrator and C#.Net software developer since 2006. Pablo wrote the book "Hands-on data virtualization with Polybase". He is also talented at tuning long-running queries in Oracle and SQL Server, reducing the execution time to milliseconds and the resource usage up to 10%. He loves learning and connecting new technologies providing expert-level insight as well as being proficient with scripting languages like PowerShell and bash. You can find several Oracle-related tips in his LinkedIn profile.
Pablo Echeverria is a talented database administrator and C#.Net software developer since 2006. Pablo wrote the book "Hands-on data virtualization with Polybase". He is also talented at tuning long-running queries in Oracle and SQL Server, reducing the execution time to milliseconds and the resource usage up to 10%. He loves learning and connecting new technologies providing expert-level insight as well as being proficient with scripting languages like PowerShell and bash. You can find several Oracle-related tips in his LinkedIn profile.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
