By: Tim Smith | Comments | Related: More > Import and Export
Problem
We maintain a big data environment with four ETL teams who maintain data sets that we've delineated rules for maintaining. We have run into issues where we need to access data from the original source, such as the import file, or access data that was derived from the source that was later used for other purposes. In some cases, we retain the original data in our reports, but with other data sets, our data we report are completely derived, which can make it difficult to track for audit purposes if we don't retain the original data.
Since we have many teams and manage a large amount of data, what are some considerations and best practices for retaining ETL source data, such as files, API calls, etc.?
Solution
In large data environments, we may have different rules for data sets, especially when we consider retaining the original data from ETL files, API calls, data feeds, etc. Some initial considerations that will help provide insight for each data set or each team:
- For our environment, what is a scenario or scenarios in which we would need to access the original data set? An example here might be loan data where we don't retain loan client's comments, but retain other data for analysis, but need an answer to a question involving a loan client's comment. Another example might be retaining ETL files from venders for use if needing to prove these files have errors, after being cross-checked with other data sets.
- How much of the original data is retained within our data structure? An example with some pricing data sets, we extend the original data set by adding algorithms, but seldom change or remove original data - unless the data set has obvious errors.
- If we need to access the original data, how flexible can we be with the stored format? As an example, if we retain data from API calls in files, can we migrate these to table or document storage from their original file form?
- What are our limitations - such as cost, time, private data, skill, etc. - as these may be deciding factors if we choose to keep original data? If we have a limited budget for storage of ETL files and privacy or security isn't a huge concern as the original data are public, cheap cloud storage may be an option to consider (such as Amazon Glacier).
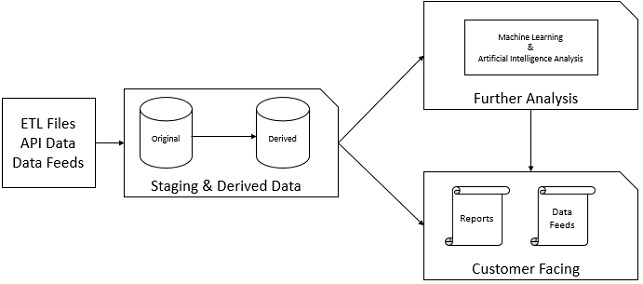
In the above image, we look at three sources for ETL data - files, API calls, and direct data feeds. Most ETL sources will fall within these categories, as data either come from an external disk based source, through an external web API or interface, or are directly fed by another source.
Direct Data Feeds
In the case of data feeds, we receive data directly from the vender. If we had a database that we called our EntryStaging database, the vender would submit data to this database directly through their own ETL flow. When we think about retaining the original data from data feeds, we will already have it within a table structure or layout and we can use compressed backups and save a copy of the data periodically, or we can migrate the original data to its own server and retain it live. The latter option will be more expensive, provided we don't need to access the data that often, though we may be able to reduce the space by using some of the tools in SQL Server, like clustered columnstore indexes or other compression options. If we save backups, we will require time to bring the data online, but if we seldom access the data, this may be a preferred option.
In both of these cases, at most we have to restore the database, check data integrity post restore, and query the data for our needs - and this only applies if we use the backup option. If the data feed is public data, or data that we are willing to store in the cloud, we can consider storing backups in the cloud, as some options are cheap per petabyte. This assumes that we're willing to be delayed for a period of time while we obtain access to the data. A few considerations for direct data feeds to decide whether to keep the data live on another server, or save a backup:
- We may need to access the data a few times a year to resolve a discrepancy. A backup file and cloud storage may be the preferred option here.
- We tend to query the data weekly for validating a record or resolving a discrepancy. In this case, a backup file on local storage or data live on a separate server with compression options used may be the preferred option.
- We face random audits at any time, which we must answer within minutes, and due to the data type, these data must be secured. In this case, a separate server with live data would be the best option, especially since these audits don't have any ability to be delayed.
ETL Files
When we import data through files and retain the full format of the data, we have the option to use the above techniques to keep the original data, such as using backup files or on another server outside of our staging server. We can use these techniques because we import all the data from the file, so the original data will be fully retained.
What if we import some data from a file, while removing other data? An example might be where we retain housing records, but remove comments that pertain to those housing records. The file's original data has more data than what we have on our staging server, or what we would keep either on a backup or on a different server, relative to our needs.
If we're resolving a discrepancy, or need the data in the case of an audit, keeping the files may be required. A lack of original file retention may cause an audit failure, relative to the industry or legal jurisdiction. If the file requires strict security, we may be required to pay for the storage and keep it local to pass the audit. If we have some flexibility with the security, we could store the data in the cloud. In the below example.
---- Once split, I would truncate this
CREATE TABLE tbImportExample(
IdKey VARCHAR(20),
---- Contrived PII data
CustomerIdentifyingInformationOne VARCHAR(100),
CustomerIdentifyingInformationTwo VARCHAR(100),
---- Historical non-PII data
Demographic VARCHAR(1),
DemographicGroup TINYINT,
Assessment VARCHAR(4)
)
---- Distinct PII data are stored here
CREATE TABLE tbSplitCustomerIdentifying(
CustomerIdentifyingID INT IDENTITY(1,1) PRIMARY KEY,
IdKey VARCHAR(20),
---- Contrived PII data
CustomerIdentifyingInformationOne VARCHAR(100),
CustomerIdentifyingInformationTwo VARCHAR(100)
)
---- Historical information are stored here
CREATE TABLE tbSplitCustomerHistoric(
HistoricId BIGINT IDENTITY(1,1) PRIMARY KEY,
IdKey VARCHAR(20),
Demographic VARCHAR(1),
DemographicGroup TINYINT,
Assessment VARCHAR(4)
)
---- Example initial import:
INSERT INTO tbImportExample
VALUES ('6ADE6A5B','Identifier1','Identifier12','A',1,'High')
, ('6ADE6A4C','Identifier2','Identifier22','B',1,'Mid')
, ('6ADE6A3D','Identifier3','Identifier32','A',2,'Low')
, ('6ADE6A2E','Identifier4','Identifier42','A',1,'Mid')
---- Example split:
INSERT INTO tbSplitCustomerIdentifying (IdKey,CustomerIdentifyingInformationOne,CustomerIdentifyingInformationTwo)
SELECT IdKey, CustomerIdentifyingInformationOne, CustomerIdentifyingInformationTwo
FROM tbImportExample
INSERT INTO tbSplitCustomerHistoric (IdKey,Demographic,DemographicGroup,Assessment)
SELECT IdKey, Demographic, DemographicGroup, Assessment
FROM tbImportExample
---- Clear initial import table: we still have the original data, and we've split off the PII data
TRUNCATE TABLE tbImportExample
From the above code, we delineate the PII data from the historical data and retain the key for the historical data to be linked to the PII data when needed. Given the security breaches in the past two years, I would consider alternative methods of sending PII data to clients outside of live reports. Some companies may not have this choice, though consider the growing risks and be clear with users about this. When retaining these original data, I would keep the PII data separate from the historical data outside of the ETL server. When we think about storing our original data, by delineating the PII data from the historical data, we have advantages with this approach on storage:
- Without the PII data attached, we may be able to store historical data in the cloud or have more options for storing these data.
- We've kept the original data by separating data that may have strict guidelines from data that may have more flexibility. Depending on what our further needs are for the data, this retains an original data set in two places for an audit.
- We can keep all external ports off while importing data (i.e.: no ability to send data).
- We can disable all ports and open one port to a migration server, when ready to migrate historical data (i.e.: no ability to send or receive data except the ability to send data to one server).
- When we need to find patterns within data in groups, without PII data stored for these queries, we can spot the trends without compromising the security of our users.
API Data
API data may be the most challenging, as APIs can frequently change or cease to exist. If we're staying compliant for audits, we may not have the option to check with the vender since the vender may not exist anymore. In extracting data from APIs, I've run into multiple situations where the company either sold or disappeared, so contacting the vender may not be an option. In this case, we want to retain what we extracted, but we may not be able to validate these data if an issue arises.
For API data, I recommend using similar techniques to the above examples and adding a column with a default of the date and time the record was extracted and inserted into the table from the API. These points of time are what I use for retaining the data and depending on how frequent I need to access them, I can save them to a backup file or keep the data on a separate server.
Next Steps
- Determine what the use-case is for retaining original data, as this will be a deciding factor for how you store the data.
- Investigate all compression options for these data, as the access required for the data will generally reduce the need for quick query performance.
- If cloud storage is an option, it's worth considering as the storage costs have become cheaper than trying to maintain the data within an environment.






About the author
 Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.
Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
