By: Tim Smith | Comments | Related: More > Import and Export
Problem
We’ve been experiencing longer transaction latency with data for our near real-time reports, which require precise times for the data to appear for the reports that we send to our clients. Since the data go through several transformations and some of our data sources are growing, we’re not sure if the data growth alone is causing some of the latency and if we need to expand the physical resources or if some of it is that our transformations don’t scale.
In this tip we cover some of the things we can do to help identify some of the problems on the data level to get a better idea of the latency issues and how far behind the data might be from loading to the reporting system.
Solution
In this tip, we’ll look at a few timing techniques on the data level for identifying possible latency, if we assume that this could be a problem with some of the transformation steps, or if we want to know if this could be a problem in the future. In one case, we may be solving for the current problem, while in the other case, we want to prevent this from becoming a problem. In some cases, hardware will be the issue – our data load has increased, and we need to add processing power. In other cases, we may be able to identify one or more transformation steps that can be optimized and tune these.
All of these will either use a time-based or record-based format so that we can identify what’s normal for our loads using aggregates on historical data.
Use Test Transactions
After we receive a batch of data, we add a test value that’s non-existent as a part of the data and is only for validation of the data flow. This means that within our final data, we'll have an invalid value, so all of our reports on these data will filter this out so that these data don't impact our reports or aggregates of data. This technique works best when we have batches of data at a time, not a consistent data flow and it works well when we can order the data so that our invalid value can be added at the end of the batch, such as inserting data into a table following the bulk insert of a file and ordered in a manner where it would be the last value in any migration. One other major benefit to this approach is security: when this transaction comes through to the final destination, it can be designed to never reveal the time when the first import happened. In some environments, this matters as hackers will try to use time information as hints for how to compromise an environment.
---- We import our data BULK INSERT tbValveImport FROM 'E:\ETLFiles\Import\valve_2017.txt' WITH ( FIELDTERMINATOR = ',' ,ROWTERMINATOR = '0x0a' ,FIRSTROW=2) ---- We add our test transaction DECLARE @testvalue VARCHAR(11) = 'tez' + CONVERT(VARCHAR(8),GETDATE(),112) INSERT INTO tbValveImport VALUES (0,0,'2017-01-01 01:35:28.277','2017-01-07 04:35:13.317',@testvalue,0)
One alternative to the test value is to use a randomly selected value, or the last value in a data set and track it. Because this final value may be different each time in a load, it may cost more on performance to find when it reaches the final destination and the value must carry over from the initial load (which might be a security concern relative to how the random value is carried). This depends on the data; the advantage of a test value is we know the exact filter remains the same on every load, but on smaller loads, this may matter less.
Track the Time of Every Step Through the Flow
We can use a technique where we add a date and time column to each step of our data process – from the initial import, to the transformation, to the final destination. In the below example, we’ll look at three steps in the same database, while in practice this may be across multiple servers and with multiple steps. The first step will require only one of these columns, while the latter steps will add another date and time column.
---- Initial loading table CREATE TABLE tbValveImport( [ValveOutput] [int] NULL, [ValveInput] [int] NULL, [MeasurementTime] [datetime] NULL, [ImportDate] [datetime] NULL, [ValveId] [varchar](12) NULL, [ImportFlag] [int] NOT NULL ) ---- Transformation table (step 2) CREATE TABLE tbValveTransform( [ValveIXNValue] DECIMAL(13,2), [MeasurementTime] [datetime] NOT NULL, [ImportDate] [datetime] NOT NULL, [TransformDate] [datetime] NOT NULL, [ValveId] [varchar](12) NULL ) ---- ETL flow final time table (joins with reporting table) CREATE TABLE tbValveETLFlowTime( [ImportDate] [datetime] NOT NULL, [TransformDate] [datetime] NOT NULL, [ReportDate] [datetime] NOT NULL, [ValveId] [varchar](12) NULL ) ---- Reporting table (final table for reports) CREATE TABLE tbValveReport( [ValveIXNValue] DECIMAL(13,2), [ValveAssessment] VARCHAR(1), [MeasurementTime] [datetime] NOT NULL, [ValveId] [varchar](12) NULL )
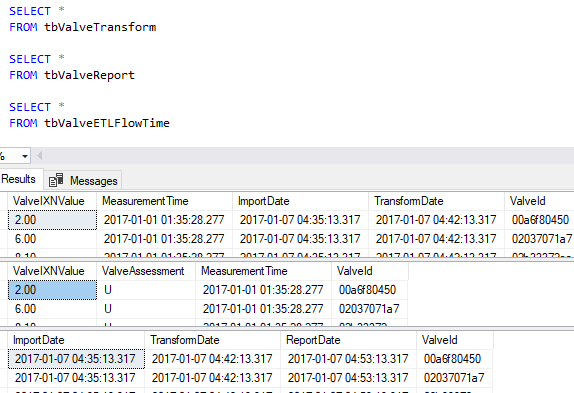
The advantage to this approach is that we have an exact time at every step for every row of data, which gives us historic data on what we can expect in the future, provided the data volume and hardware remain. We can also use these historical data to predict the impact of an increase in data, or what a hardware adjustment might do, as we do both. The downside to this is that we're adding more data to our table. Even if we use smalldate time, we're using 4 bytes per column. However, this cost may be minor compared to the costs of reports being sent out at the wrong time, or the cost of our inability to predict what the impact will be of data growth.
Measure Maximum Times Across the Flow
A similar approach to the above technique is a time stamp on each table step and measuring these values across all the points from importing the data to transforming to reporting. We can measure these maximum times and report it in a table format, with a message (shown in the below code) or using another technique. This helps us identify what step may be slowing our data movement, as we can see the final time of the import, the final time of the transformation and the final time of the report. In the below code, I use PowerShell to extract this information and write out the summarized output; if our servers were connected through linked servers, we could use T-SQL as an alternative.
Function Get-LatestDate {
Param(
[string]$server
, [string]$database
, [string]$query
)
Process
{
$scon = New-Object System.Data.SqlClient.SqlConnection
$scon.ConnectionString = "Data Source=$server;Initial Catalog=$database;Integrated Security=true"
$1rowcmd = New-Object System.Data.SqlClient.SqlCommand
$1rowcmd.Connection = $scon
$1rowcmd.CommandText = $query
$1rowcmd.CommandTimeout = 0
try
{
$scon.Open()
$1rowread = $1rowcmd.ExecuteReader()
$1rowdt = New-Object System.Data.DataTable
$1rowdt.Load($1rowread)
foreach ($row in $1rowdt.Rows)
{
$row["MsDt"]
}
}
catch [Exception]
{
$function = $MyInvocation.MyCommand
Write-Warning "$function ($server.$database)"
Write-Warning $_.Exception.Message
}
finally
{
$scon.Dispose()
$1rowcmd.Dispose()
}
}
}
[datetime]$flow1 = Get-LatestDate -server "OurImportServer" -database "ImportDb" -query "SELECT MAX(ImportDate) As MsDt FROM tbValveImport"
[datetime]$flow2 = Get-LatestDate -server "OurTransformServer" -database "TransformDb" -query "SELECT MAX(TransformDate) As MsDt FROM tbValveTransform"
[datetime]$flow3 = Get-LatestDate -server "OurReportServer" -database "ReportingInfo" -query "SELECT MIN(ReportDate) As MsDt FROM tbValveReport"
$flow1
$flow2
$flow3
Write-Output "Import finished at $flow1, the transformation step finished at $flow2, and the report step finished at $flow3"
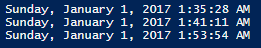

This is a popular approach to ETL flows with many servers. The positives to this is that we can write one query that performs a check across multiple servers and we save space in storage, unlike the above flow. The problem is that this technique is completely incompatible with some ETL flows that must use strict security. Some secure ETL designs require that each step of the process communicate one-way or are unable to communicate to earlier steps due to PII data, or due to data partitioning where secure data migrate elsewhere. If security is not a priority, opening communication across multiple servers may not be an issue, such as priority reports for internal users only.
In addition to designing for analysis that allows us to identify problems quickly, we want to consider the costs in performance overhead along with complying with strong security practices. Since some environments will weigh these concerns differently, a few of these techniques may not be options, or can be adjust in a manner that matches the environment.
Next Steps
- Each of these techniques will function better in some environments depending on the limitations within that environment. For an example, the technique of simulating a test transaction per load will cost much less in storage than adding time columns to each step in the transformation and aggregating that. In a similar manner, the latter technique of pulling data from each step may be a problem with security if multiple servers are involved and our security team wants some servers completely blocked except at certain times or with certain servers.
- When we use aggregates on our data, we can alert on the growth of those data values – such as day 2’s load time increasing above a threshold compared to day 1 or another measure we may find meaningful.
- If we determine that transformation times are a cause we can investigate scaling some transformation steps for important data to be separate for reports that may be daily.






About the author
 Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.
Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
