By: Susantha Bathige | Comments (11) | Related: > TSQL
Problem
In SQL Server, we often need to search character fields using the percentage (%) wildcard. I see when I put the wildcard at the end of the search string (String%) it uses the index, but if I put it the front (%String) it does a scan of the index. How can I make this search (%String) more efficient?
Solution
Having the wildcard (%) at the end of the string when searching on uncertain characters is not as challenging as having the wildcard at the beginning of the search string. For example, searching on a character field with 'abc%' is not an issue if the column has an index, but searching '%abc' is always slow because it does an index scan. However, there are many situations where we need to write queries with '%abc'.
In this tip, we will look at one way this can be resolves to make queries faster than ever before.
SQL Server Wildcard Searches Using %
For example, say you have a table named Employee and you want to find all the rows where the name starts with 'Aaron'. In this case, you would write a query as follows:
SELECT * FROM Employee WHERE name LIKE 'Aaron%'
Similarly, you can find all the employees with the name ending with certain characters, as follows:
SELECT * FROM Employee WHERE name LIKE '%Allen'
You can also find all the employees where the name has letters 'Co' anywhere in the name. The query would look like below:
SELECT * FROM Employee WHERE name LIKE '%Co%'
Assuming the Employee table has an index on the Name column, you will quickly see the last two queries are slower than the first one because they do an Index Scan and instead of an Index Seek.
The first query is faster because the WHERE condition is Sargable. However, the 2nd and 3rd queries are not Sargable, hence those queries could not leverage the index on Name. As a result, the 2nd and 3rd queries are slower than the 1st query.
How to make SQL Server Wildcard Searches Using % Faster
Let's create a sample data set using the AdventureWorks2016 database. Let's call this new table customer.
USE AdventureWorks2016 GO CREATE TABLE customer ( customer_id int identity(1,1) primary key, cust_name varchar(100), cust_name_reverse varchar(100) ); CREATE INDEX idx_cust_name ON customer(cust_name); CREATE INDEX idx_cust_name_reverse ON customer(cust_name_reverse, cust_name);
The customer table has three columns including a primary key for the customer_id. I intentionally added the third column to contain the customer name in reverse order. We will need that column later.
The script below populates the table using the data from the [Person].[Person] table in the AdventureWorks2016 database.
INSERT INTO customer SELECT FirstName + ' ' + LastName , REVERSE(FirstName + ' ' + LastName) FROM [Person].[Person]
Note that the INSERT query uses the REVERSE function to generate the customer name in reverse order.
Also, note that we have indexes on both cust_name and cust_name_reverse columns.
Slower SQL Server Wildcard Search
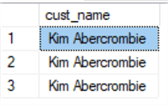
Let's do a search to find out all the customers with their names ending with 'Abercrombie'. See the below query:
SELECT cust_name FROM customer WHERE cust_name LIKE '%Abercrombie'
Here are the results:
The execution plan does an Index Scan.
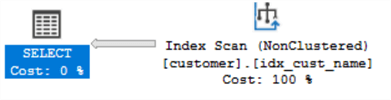
This table has 19,972 records and the query returns only three records. It does an Index Scan, meaning the entire index of cust_name had to be scanned to find just three records which is not good in terms of performance.
The query above cannot be further improved.
Faster SQL Server Wildcard Search
We could use an alternative method to get the same result more efficiently with an index seek. See the alternative query below:
SELECT cust_name FROM customer
WHERE cust_name_reverse LIKE REVERSE('Abercrombie') + '%'
Here are the results:

The execution plan does an Index Seek.

This time, we used cust_name_reverse column which has the customer name in reverse order. Also, notice the percentage sign (%) is at the end of the search string. Basically, we have converted our query to make it Sargable as 'abc%'.
Comparing the SQL Server Wildcard Queries
Let's execute both queries at once and compare the execution plans and cost comparison.
We can see the first query that does an Index Scan is 96% of the batch and the second query that does an Index Seek is 4% of the batch.
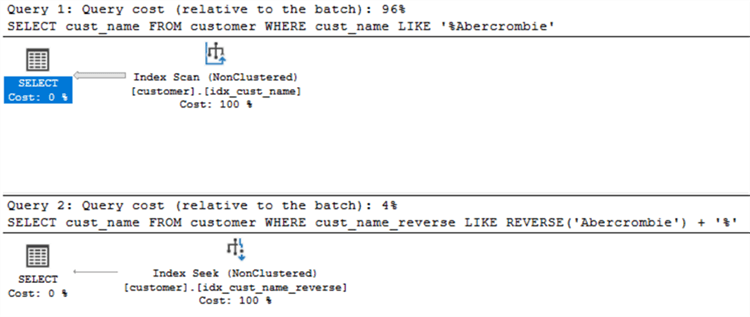
It's great! The alternative approach is a big improvement.
Summary
The drawback of this approach is that you need to have an additional column to store the reverse order of the string, but if you are designing the database system, you can add the additional column if it is something that will be used frequently with wildcard searches where "%" is at the beginning of the string. The performance gain with this approach could be bigger than the additional storage it uses. It's your choice!
Next Steps
- Take a look at the REVERSE T-SQL function.
- Also, take a look at these other tips.






About the author
 Susantha Bathige currently works at Pearson North America as a Production DBA. He has over ten years of experience in SQL Server as a Database Engineer, Developer, Analyst and Production DBA.
Susantha Bathige currently works at Pearson North America as a Production DBA. He has over ten years of experience in SQL Server as a Database Engineer, Developer, Analyst and Production DBA.
This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
