By: Jeffrey Yao | Comments (5) | Related: > Triggers
Problem
I have a few SQL Server tables with 100+ columns and I need to audit data changes on about 60+ columns. When they are updated, I want to know which column(s) is/are updated. I know columns_updated() can give me all the information I need, but it is a little confusing to understand. Is there a way I can get the column names from columns_updated() value? Also, if I have a list of columns for a table, can I have a binary value which I can use to test against columns_updated() to see whether any of the columns are updated?
Solution
Using a SQL Server trigger to check if a column is updated, there are two ways this can be done; one is to use the function update(<col name>) and the other is to use columns_updated(). The first method is very intuitive, while the second one is a bit confusing as explained below from MSDN.

In this tip, we will create two functions, which will help us better manipulate the columns_updated() function in triggers, as shown below:
| 1 | udf_ColumnList(@p1 varbinary(256), @p2 int) | @p1 is the value from columns_updated(), @p2 is the table object_id, the function returns a table containing the column names matching each bit value of 1 in @p1 |
| 2 | udf_ColumnUpdated(@p1 varchar(max), @p2 int) | @p1 is the list of columns, @p2 is the table object_id, the function returns a varbinary(256) that is equal to the value of columns_updated() if each column in @p1 is updated |
From Columns_updated() to Column List
We will first create a test table and trigger to demonstrate what we want to achieve.
-- executed in sql server 2016 SP2 CU12 USE MSSQLTIPS go DROP TABLE IF EXISTS DBO.T go CREATE TABLE DBO.T ( C1 VARCHAR(10), C2 VARCHAR(10), C3 VARCHAR(10), C4 VARCHAR(10) , C5 VARCHAR(10), C6 VARCHAR(10), C7 VARCHAR(10), C8 VARCHAR(10) , C9 VARCHAR(10), C10 VARCHAR(10), C11 VARCHAR(10), C12 VARCHAR(10) , C13 VARCHAR(10), C14 VARCHAR(10), C15 VARCHAR(10), C16 VARCHAR(10) , C17 VARCHAR(10), C18 VARCHAR(10), C19 VARCHAR(10), C20 VARCHAR(10) , C21 VARCHAR(10), C22 VARCHAR(10), C23 VARCHAR(10), C24 VARCHAR(10) , C25 VARCHAR(10), C26 VARCHAR(10), C27 VARCHAR(10), C28 VARCHAR(10) , C29 VARCHAR(10), C30 VARCHAR(10), C31 VARCHAR(10), C32 VARCHAR(10) , C33 VARCHAR(10), C34 VARCHAR(10), C35 VARCHAR(10) ); insert into dbo.t values ( 'C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7', 'C8', 'C9', 'C10' , 'C11', 'C12', 'C13', 'C14', 'C15', 'C16', 'C17', 'C18', 'C19', 'C20' , 'C21', 'C22', 'C23', 'C24', 'C25', 'C26', 'C27', 'C28', 'C29', 'C30' , 'C31', 'C32', 'C33', 'C34', 'C35');
We will create a simple trigger to print the columns_updated() value:
USE MSSQLTIPS go drop trigger if exists trgUpd; go create TRIGGER trgUpd on dbo.t after update not for replication as begin print columns_updated(); end
If we randomly update a few columns of the dbo.t table as follows, we will see a printout value:
USE MSSQLTIPS go update dbo.t set c3 = 'c3_1' , c7 = 'c7_1' , c11 = 'c11_1' , c12 = 'c12_1' , c24 = 'c24_1' , c28 = 'c28_1' , c33 = 'c33_1';
We will get the following printout: 0x440C800801
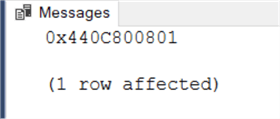
Now assume we do not know the update statement; can we get the column list from 0x440C800801? The answer is yes via the following function:
USE MSSQLTIPS
go
drop function if exists dbo.udf_ColumnList;
go
create function dbo.udf_ColumnList (@val varbinary(256), @objectid int)
returns @col table (colid int, isTouched bit, colname sysname default 'N/A')
as
begin
declare @i int=1, @cu binary;
while (@i <= len(@val))
begin
set @cu = substring(@val, @i, 1);
insert into @col(colid, isTouched)
select (@i-1)*8 + 1, @cu & 1 --@val%2
union all
select (@i-1)*8 + 2, @cu & 2 --@val/power(2, 1)%2
union all
select (@i-1)*8 + 3, @cu & 4 --@val/power(2, 2)%2
union all
select (@i-1)*8 + 4, @cu & 8 --@val/power(2, 3)%2
union all
select (@i-1)*8 + 5, @cu & 16 --@val/power(2, 4)%2
union all
select (@i-1)*8 + 6, @cu & 32 --@val/power(2, 5)%2
union all
select (@i-1)*8 + 7, @cu & 64 --@val/power(2, 6)%2
union all
select (@i-1)*8 + 8, @cu & 128 --@val/power(2, 7)%2
set @i = @i+1;
end
if exists (select * from sys.tables where object_id=@objectid)
begin
; with c as (
select c.name, c.column_id
from sys.columns c
where c.object_id = @objectid
)
update col set colname = c.name
from @col col
inner join c
on col.colid = c.column_id;
delete
from @col
where isTouched = 0;
-- commented out to list all columns
end
return
end
Now let see how it goes by inputting the previous columns_updated() value into this function:
declare @objectid int = object_id('dbo.t');
select * from dbo.udf_ColumnList (0x440C800801, @objectid );
It will return the following:
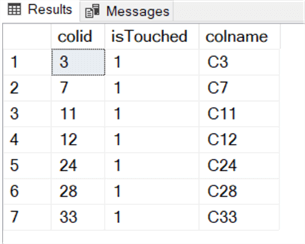
It is exactly the same as the columns used in the previous update statement.
From Column List to Columns_updated()
Now let’s say we know the list of columns and we want to know the expected columns_updated() value from such a list. Of course, we can create a trigger (as shown above) on each table, and then create an update statement for the needed columns and check the columns_updated() value, but it is not an efficient way when we have to handle multiple tables.
I came up with the following function:
USE MSSQLTIPS
go
drop function if exists dbo.udf_ColumnUpdated;
go
create function dbo.udf_ColumnUpdated(@column_list varchar(max), @table_object_id int)
returns varbinary(256)
as
begin
declare @val varbinary(256)=0x;
declare @t table (bitpos int, [name] varchar(128), bytepos int);
declare @v table (bytepos int, val binary(1));
declare @i int, @j int=1;
--declare @column_list varchar(max) ='c1,c2,c3, c31,c32,c33';
declare @bytepos int, @bitpos int, @name varchar(128);
if not exists (select * from sys.tables where object_id = @table_object_id)
begin
-- raiserror ('The @table_object_id =%d is invalid', 16,1, @table_object_id);
return null;
end
--populate the @v table according to # of columns, each bytepos and val will represent 8 columns
select @i = case count(*)%8 when 0 then count(*)/8 else count(*)/8+1 end
from sys.columns
where object_id = @table_object_id;
while @j <= @i
begin
insert into @v (bytepos, val) values (@j, 0x00);
set @j += 1;
end
;with t as (
select [colname]=trim([value]) from string_split(@column_list, ',')
)
insert into @t (bitpos, name, bytepos)
select bitpos=case c.column_id%8 when 0 then 8 else c.column_id%8 end, c.name
, bytepos=c.column_id/8 + case c.column_id%8 when 0 then 0 else 1 end
from sys.columns c
inner join t on t.colname = c.name
and c.object_id = @table_object_id;
; with c as (
select [val] = sum(power(2, bitpos-1)), bytepos
from @t
group by bytePos
)
update v set val = c.val
from @v v
inner join c on c.bytepos = v.bytepos
--select * from @t;
--select * from @v;
select @val +=val from @v order by bytepos asc;
return @val;
end
Now we need to test this new function with the following scripts
USE MSSQLTIPS
go
select [Columns_Updated]=dbo.udf_ColumnUpdated('c3,c7,c11,c12,c24,c28,c33', object_id('dbo.t'));
We get the following:
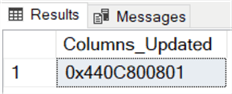
It is exactly the same as the printout value from the trigger.
A Real World Example
I have a table with 112 columns, the first column is used as the primary key, the last column is a "calculated" column to hold the hash value of the 100 columns from column 2 to column 101, the next 10 columns (column 102 to column 111) are not included in the hash calculation.
The last column, let’s call it hash column, is updated via a CLR function, if any column in those 100 columns (column 2 to column 101) is updated, but on the other hand, if the update is only on one or more of those 10 columns (column 102 to 111), the hash column will not be updated for performance sake.
So to compose this trigger, we first get the Columns_updated() value for the 100 columns used in hash calculation with our dbo.udf_ColumnsUpdated() function.
To demonstrate this, I will use the following code to create a table dbo.Test with 112 columns.
USE MSSQLTIPS
go
-- we first create a dummy table
declare @i int =1;
declare @sql varchar(max)='create table dbo.test (', @crlf char(2)=char(0x0d)+ char(0x0a);
while @i <= 112
begin
set @sql += @crlf + 'c' + cast(@i as varchar(5)) + ' varchar(10),'
set @i +=1;
end
set @sql = 'drop table if exists dbo.test;' + @crlf + substring(@sql, 1, len(@sql)-1) + ')';
-- print @sql; -- you can print it out to see how it goes
exec (@sql);
go
-- calculate
set nocount on;
declare @column_list varchar(max)='';
select @column_list += name + ','
from sys.columns
where object_id = object_id('dbo.test')
and column_id >=2 and column_id < = 101;
set @column_list = substring(@column_list, 1, len(@column_list)-1);
print @column_list;
select CU_Value=dbo.udf_ColumnUpdated(@column_list , object_id('dbo.test'));
We get the following value:
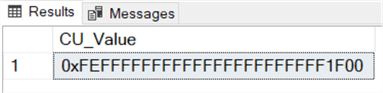
With this value retrieved, it will be easy to come up with a concise update trigger as follows.
Note this trigger is more for demo purpose (using the previous dbo.Test with 112 columns as an example) than any real business function.
The trigger will display the columns updated if the columns are among the 100 columns, i.e. column 2 to 101 (inclusive).
USE MSSQLTIPS
go
drop trigger if exists trg_upd;
go
create trigger trg_Upd on dbo.test for update as
begin -- trigger
declare @upd_val varbinary(128) = 0xFEFFFFFFFFFFFFFFFFFFFFFF1F00; -- hard-coded from the pre-calculation
declare @col_upd_val varbinary(128)= columns_updated();
declare @i int = 1;
declare @v int, @b binary(1);
declare @x varbinary(128)=0x;
declare @isKeyColumnUpdated bit = 0;
set @i = 1;
while @i <= DATALENGTH(@upd_val)
begin
set @v = cast(substring(@upd_val, @i, 1) as int);
if ( substring(@col_upd_val, @i, 1) & @v )>0
begin
set @b = substring(@col_upd_val, @i, 1) & @v;
set @x += cast((substring(@col_upd_val, @i, 1) & @v) as binary(1)); -- @b;
set @isKeyColumnUpdated = 1;
-- break; -- in real world, if one concerned column is updated, just break out
end
else
set @x += 0x00;
set @i += 1;
end
if (@isKeyColumnUpdated = 1)
begin
-- in prod, we need to put the business function codes here
select * from dbo.udf_ColumnList (@x, object_id('dbo.test'));
end
else
print 'no key column updated'; -- for demo only, not needed in prod
end -- trigger
Now, let’s populate one row into the dbo.Test table. Since we have 112 columns, it will be lengthy to write an insert sql statement, so I just use a short script to take advantage of dynamic sql to do the work:
USE MSSQLTIPS
go
-- insert a dummy record
-- you can run multiple times to put mulitple records
declare @i int = 1;
declare @sqlcmd varchar(max)='', @crlf char(2) = char(0x0d) + char(0x0a);
while (@i <=112)
begin
set @sqlcmd += ',''C' + cast(@i as varchar(3)) +'''' + @crlf;
set @i +=1;
end
set @sqlcmd = substring(@sqlcmd, 2, len(@sqlcmd));
set @sqlcmd = 'insert into dbo.test values (' + @sqlcmd + ');'
print @sqlcmd; -- you can check the
exec (@sqlcmd);
Ok, once we have at least one row, let’s do a few updates and see how the trigger behaves.
1. We have an update on columns among column 102 to 111, which are not monitored by the trigger.
USE MSSQLTIPS go set nocount on; update dbo.test set C102 = 'C102-test' ,C105 = 'C105-upd' ,C109 = 'C109_1' ,C111 = 'C111-upd2';
The result is the following, exactly as expected:
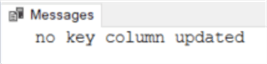
2. We have an update on key columns only, i.e. columns among column 2 to 101
USE MSSQLTIPS go set nocount on; update dbo.test set C2 = 'C2-test' ,C25 = 'C25-upd' ,C89 = 'C89_1' ,C101 = 'C101-upd2';
The result is the following, just as expected as well:
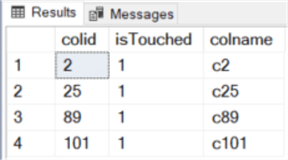
3. We combine 1 and 2 together, i.e. an update that contains both key columns and non-key columns.
USE MSSQLTIPS go set nocount on; update dbo.test set C2 = 'C2-test' ,C25 = 'C25-upd' ,C89 = 'C89_1' ,C101 = 'C101-upd2' ,C102 = 'C102-test' ,c105 = 'C105-upd' ,C109 = 'C109_1' ,C111 = 'C111-upd2';
We get the following result, exactly the same as the update in case 2, because only those key columns are updated so they are captured and listed by the trigger.
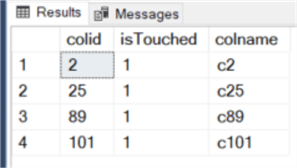
Summary
In this tip, we have discussed two functions related to columns_updated().They can be of help in some niche cases when dealing with triggers on very wide tables (i.e. tables with many columns).
For example, in one case, an auditing requirement is to check when some key columns are updated by a session (i.e. spid, application name, session user, etc.), instead of designing a solution using SQL Server Change Data Capture or Change Tracking, we can simply create a trigger and dump the columns_updated() value and some other needed info into another table [X], and use a SQL job to check this table [X] every 5 minutes and report the changes if the monitored key columns are involved.
Triggers in SQL Server are generally considered as not recommended by the DBA community, yet they are wildly used in many off-the-shelf solutions, and also in many DBA self-developed/controlled solutions. I personally use triggers from time to time for automation purposes, for example if a control table adds a new record, depending on the column value, I will auto start a pre-defined job. So, I’d say that triggers are a very nice feature and add great value, just do not abuse the use of them, such as having a long and time-consuming transaction inside a trigger.
Next Steps
There are many interesting tips about SQL Server Triggers on MSSQLTips.com, please review them to learn more about the use of triggers.
Please read the following related tips / articles for additional information.
- SQL Server Trigger Example
- Auditing when Triggers are Disabled or Enabled for SQL Server
- Disabling a Trigger for a Specific SQL Statement or Session






About the author
 Jeffrey Yao is a senior SQL Server consultant, striving to automate DBA work as much as possible to have more time for family, life and more automation.
Jeffrey Yao is a senior SQL Server consultant, striving to automate DBA work as much as possible to have more time for family, life and more automation.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
