By: Mohammed Moinudheen | Comments (10) | Related: > Indexing
Problem
On some of the SQL Server databases I manage, I noticed that there are tables with GUID columns and the GUID column is defined as the primary key. On checking further, I noticed that these GUID columns also have a unique clustered index on the column. What are the issues with this approach especially when the database grows considerably?
Solution
In SQL Server, there is a datatype called UniqueIdentifier that can be used to define GUIDs. To learn more about GUIDs refer to this excellent link by Siddharth Mehta and try out the sample queries in that tip.
Defining a primary key
Defining a primary key on a table will automatically create a unique clustered index unless it is mentioned explicitly not to create one. You could use the same scripts from this tip.
CREATE TABLE Product_A ( ID uniqueidentifier primary key default newid(), productname varchar(50) )
Here, you can see you have defined the primary key on the ID column. This will create a corresponding clustered index as shown below on the left and in the script on the right that can be generated from SSMS.

However, you could have avoided this scenario by specifying the non-clustered option as shown below.
CREATE TABLE Product_B ( ID uniqueidentifier primary key nonclustered default newid(), productname varchar(50), ) go CREATE CLUSTERED INDEX CIX_Product_B_productname ON Product_B(productname) GO
For this demo, we will create a non-unique clustered index on the productname column. This is for testing purposes only. As the non-clustered option is explicitly mentioned for the primary key, the clustered index does not get defined on the uniqueidentifier column.

Uses of GUIDs in SQL Server
One of the major uses of GUIDs is in merge or replication-based applications. Normal integer based primary key columns may face issues while trying to merge data together and dealing with the conflict issues would get tiresome especially if dealing with huge databases in busy applications. GUID usage gained popularity over time due to these benefits. You can refer to this link where pros and cons of using integer or GUID based primary keys is neatly explained by Armando Prato.
All of the factors mentioned come in handy especially at the design phase of the application where the table and the indexes can be defined based on the correct requirements. But sometimes, things like a clustered index on an uniqueidentifier column defined as a primary key can get overlooked causing performance issues at later stages.
What is the issue if clustered index is on a GUID primary key column?
The purpose of the primary key is to uniquely identify every row in the table. So, there is no problem in having the GUID as a primary key. However, as we saw earlier, creating just the primary key by default also creates a unique clustered index unless otherwise mentioned.
The clustered index as we know, helps in defining the physical order of the rows of the table. As GUIDs are randomly generated, defining the clustered index on the GUID column will lead to page splits in the page structure where data is entered in the middle of the page based on the value of the uniqueidentifier. This type of page split will have an impact on INSERTs and UPDATEs. It will lead to issues with SELECT statements as well due to heavy fragmentation. You can refer to this link by Ben Snaidero where he neatly compares page splits while using int, bigint or GUID data types.
Demo on impact of fragmentation while using clustered index on GUID primary key
To learn more about fragmentation, refer to this excellent tip by Brady Upton where he gives a good overview of SQL Server index fragmentation. You can use the same scripts from this tip to get fragmentation percentage.
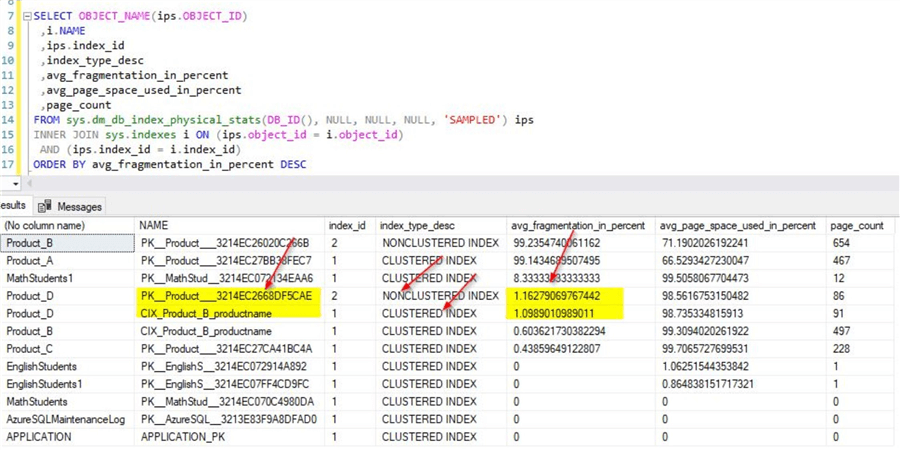
SELECT OBJECT_NAME(ips.OBJECT_ID) ,i.NAME ,ips.index_id ,index_type_desc ,avg_fragmentation_in_percent ,avg_page_space_used_in_percent ,page_count FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'SAMPLED') ips INNER JOIN sys.indexes i ON (ips.object_id = i.object_id) AND (ips.index_id = i.index_id) ORDER BY avg_fragmentation_in_percent DESC
On running this script, you will get this output with details on index fragmentation percentage.
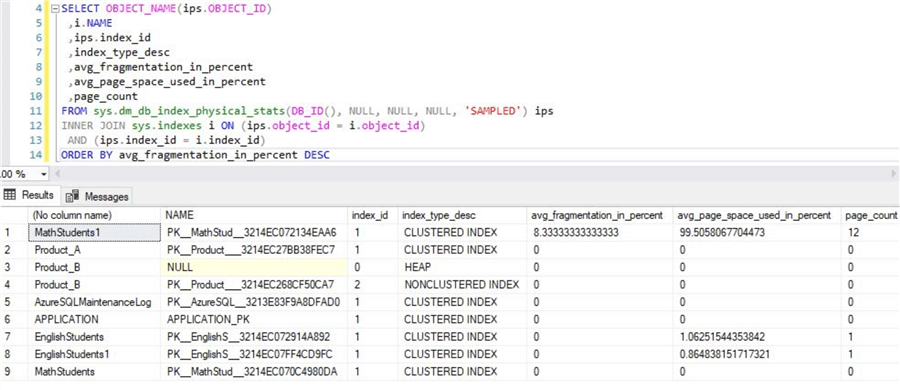
As you can see this is an empty database with a very low page count. Let's insert rows to the Product_A table we created earlier to test fragmentation as the clustered index is defined on the GUID primary key column on this table. Use this sample script that will perform the test inserts. You may modify the GO value if you want, but the idea is to test with a high number of inserts.
INSERT INTO [dbo].[Product_A] VALUES (default,'Test') GO 100000
Once the script execution completes, check the fragmentation percentage using the same script used earlier and you will notice the fragmentation is quite high for the clustered index.
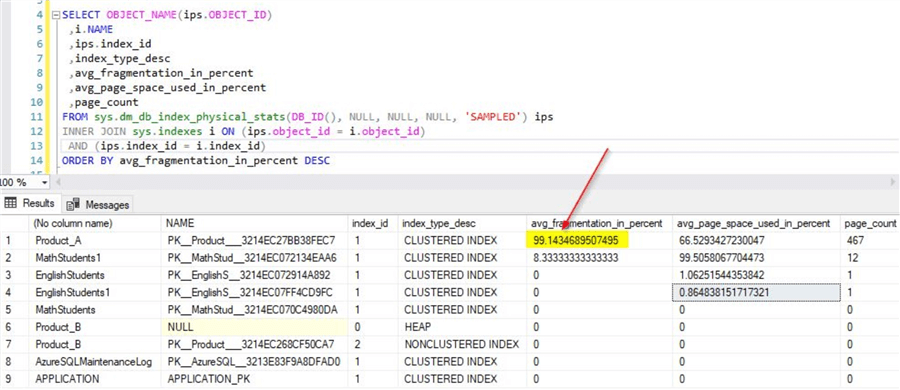
You could imagine the impact on huge databases that have high usage.
Demo on impact of fragmentation while using non-clustered index on GUID primary key
In order to test this scenario, we could use the other table we created earlier - Product_B. Use the script below to perform test inserts into this table.
INSERT INTO [dbo].[Product_B] VALUES (default,'Test') GO 100000
As shown earlier, the non-clustered option was provided for the primary key in the table. Allow the inserts to complete and check the fragmentation percentage once it completes. Run the script used earlier for checking the fragmentation percentage. You will see a similar output as below for the Product_B table. From the screenshot, you can see the fragmentation % for the clustered index on the Product_B table is very low. However, the fragmentation % for the non-clustered index on the GUID column is quite high. This is mainly because of inserting a huge number of non-sequential data as we did in this case. These insertions will lead to high page splits and eventually leads to high fragmentation. As mentioned earlier, you can learn more on the impact of page splits in this tip.
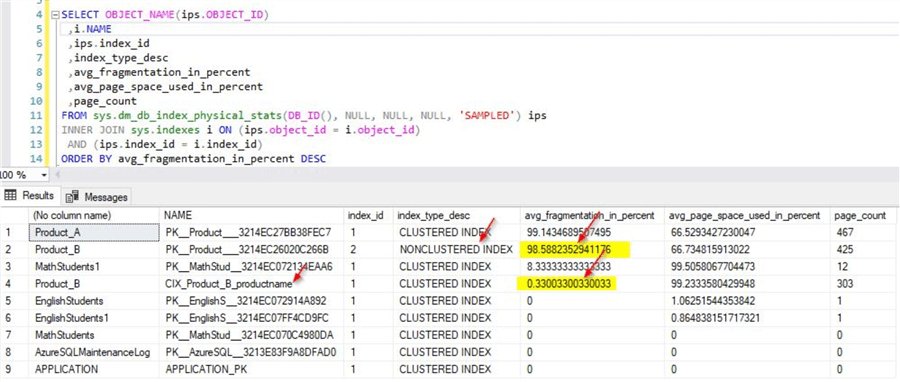
Impact of fragmentation when using clustered index on GUID primary key using newsequentialID function
As seen earlier, we had used the newid() function in the Product_A table. This generates random unique numbers every time. There are specific use cases for using either of these functions and you may refer to this tip mentioned earlier to learn more.
The newsequentialID function helps to generate a GUID greater than a previously generated one. This would help especially when used as clustered index as fragmentation would get reduced compared to having random values for GUIDs. You can use the same tables you had used earlier or you could create a new table using the below script. You can see we are using the newsequentialID() function.
CREATE TABLE Product_C ( ID uniqueidentifier primary key default newsequentialid(), productname varchar(50) )
Once done, perform the inserts as shown earlier.
INSERT INTO [dbo].[Product_C] VALUES (default,'Test') GO 100000
After the insert completes, check the index fragmentation using the scripts used earlier. You will notice that the fragmentation of the clustered index is very low. You will also notice that the average page space usage percentage is also high for Product_C as compared to the clustered index on Product_A.
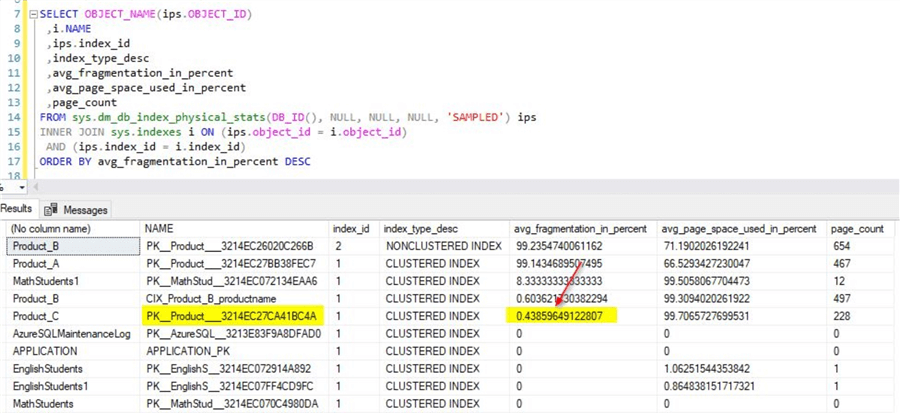
Below is a sample screenshot of the sequential GUID's.
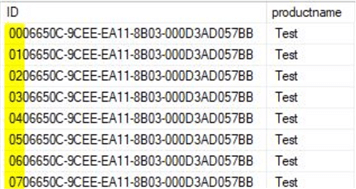
Impact of fragmentation when using non-clustered index on GUID primary key using newsequentialID function
For testing this scenario, you could alter the existing Product_B table or use the below scripts. You can notice the use of the newsequentialID function as default for primary key.
CREATE TABLE Product_D( ID uniqueidentifier primary key nonclustered default newsequentialid (), productname varchar(50), ) go CREATE CLUSTERED INDEX CIX_Product_B_productname ON Product_D(productname) GO
Once done, perform the inserts using below script.
INSERT INTO [dbo].[Product_D] VALUES (default,'Test') GO 100000
After the inserts complete, check the index fragmentation using the script provided earlier. You will notice that the fragmentation percentage is low for the clustered index as expected. However, you will also notice low fragmentation on the non-clustered index on the GUID column. This was not the case when we had used the newid function earlier in our demo for the non-clustered index on the GUID column.
Find GUID columns that have primary key and clustered index defined on same column and using newid or newsequentialID
As you can see there are some workarounds we can use if you are facing considerable performance issues based on the above scenarios. There is no standard approach to deal with these issues. It is best to test all options based on your requirements before applying any of the suggestions mentioned above.
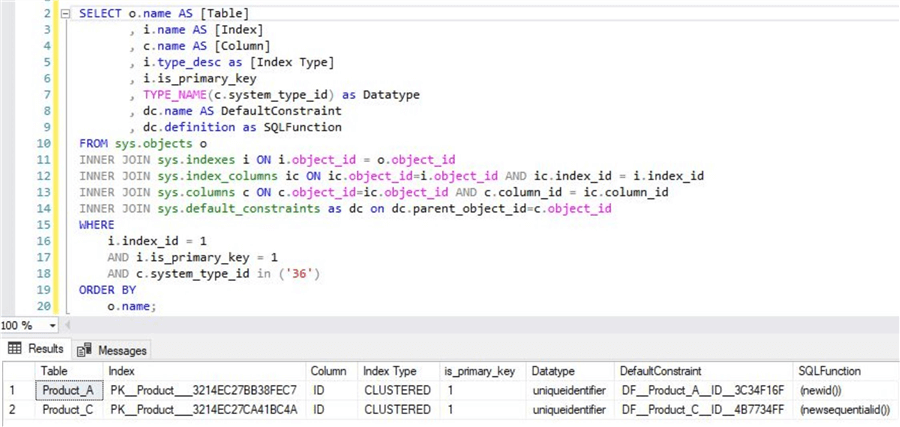
You could use the below query to collect information if you have a clustered index defined on a GUID column and it also provides information if the GUID column is using newid or newsequentialID function.
SELECT o.name AS [Table]
, i.name AS [Index]
, c.name AS [Column]
, i.type_desc as [Index Type]
, i.is_primary_key
, TYPE_NAME(c.system_type_id) as Datatype
, dc.name AS DefaultConstraint
, dc.definition as SQLFunction
FROM sys.objects o
INNER JOIN sys.indexes i ON i.object_id = o.object_id
INNER JOIN sys.index_columns ic ON ic.object_id=i.object_id AND ic.index_id = i.index_id
INNER JOIN sys.columns c ON c.object_id=ic.object_id AND c.column_id = ic.column_id
INNER JOIN sys.default_constraints as dc on dc.parent_object_id=c.object_id
WHERE
i.index_id = 1
AND i.is_primary_key = 1
AND c.system_type_id in ('36')
ORDER BY
o.name;
In the above query, system_type_id = 36 is for the uniqueidentifier datatype.
The sample output for this query is below.
Using this query, you can quickly identify indexes in your database that may be impacted due to the presence of clustered indexes on the GUID columns.
Next Steps
- In this tip, you learned the impact of fragmentation when a clustered index is defined on GUID columns
- In this tip, you learned the impact of fragmentation when a non-clustered index is defined on GUID columns
- In this tip, you learn about the use of newid and newsequentialID functions
- You could try this demo on a trial version of Azure SQL DB or you can use existing on-premises SQL Server DB
- To learn more about Microsoft Azure, refer to this link
- To learn more about GUID, you may refer to the various links mentioned in this tip






About the author
 Mohammed Moinudheen is a SQL Server DBA with over 6 years experience managing production databases for a few Fortune 500 companies.
Mohammed Moinudheen is a SQL Server DBA with over 6 years experience managing production databases for a few Fortune 500 companies.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
