By: Koen Verbeeck | Comments (2) | Related: > Tools
Problem
SQL Server Data Tools allows you to develop database projects inside Visual Studio. It's a versatile IDE, and it can do more than create tables or stored procedures. In this tip, we'll give an overview of the more interesting features of this product.
Solution
SQL Server Data Tools (SSDT) is a development tool from Microsoft for building SQL Server relational databases in Visual Studio. In an SSDT Project you can design database objects for SQL Server, but also Azure SQL DB and Azure SQL Data Warehouse. In this tip we'll focus on SSDT for database projects, because SSDT can also be used to develop solutions for SQL Server Integration Services (SSIS), Analysis Services (SSAS) and Reporting Services (SSRS). The business intelligence components are outside the scope of this tip.
In earlier versions of Visual Studio, you could download SSDT as a separate installer, but since Visual Studio 2017 the database projects have been integrated into the Visual Studio installation. In Visual Studio 2019 for example, you need to select the workload Data storage and processing to enable SSDT.
Let's take a look at some features to discover why SSDT can be a valuable tool in your database development toolbox.
1 – Treat your Database like Code
With SSDT, all of your database objects – tables, views, stored procedures, functions – are code. You write it in Visual Studio, you build it in Visual Studio and you publish it to your desired destination. SSDT supports source control integration, such as a git repository in Azure Devops for example. Having all your database code in source control means you won't lose any code when the database goes down and cannot be recovered.
A couple of tips have already been written on the subject of database projects in SSDT and git integration:
- SQL Database Project with SQL Server Data Tools and GIT
- SQL Database Project Code Branching in Git
- Branching in Git with SQL Database Projects
- SQL Database Project with Git Feature Branch Workflow
When using source control, you can also create multiple versions of your database, by using git branches for example. Suppose you need to hotfix a stored procedure in production. In development however, you're already working on a new version of the stored procedure which doesn't need the fix. But it's not finished yet, so you cannot deploy the new version to prod. To solve this, you can create a branch using the code from production, implement the fix and publish this to production. To continue working on the new version of the stored proc, you switch your branch back to the development branch.
2 – Reverse Engineer Existing Database
You can create a database from scratch in SSDT, but what if you already have existing databases? You can import their schema into SSDT with just a few clicks:
You can find more details in the tip Reverse Engineer SQL Server Databases with Visual Studio.
3 – Schema Compare of Two Databases
This feature allows you to compare the schema of two databases and report all the differences between them. You can easily check for example what the differences are between your test and production database. A database can either by a physical database, or a database described in a database project in SSDT. Once the comparison is done, you can choose to update the target database or to generate a .sql script with all the changes. This feature is also useful when someone has been making database changes outside of SSDT – in other words, by running DDL statements directly on the database – and you want to sync those changes to source control.
The following video shows a schema compare of a database. After the compare, three changes were found: a table was added, a column was added and one column had its name changed.
The tip SQL Server Data Tools Connected Database Development also has an example of a schema compare.
4 – Publishing Database Schema
When you finished the development of the database objects, you can publish the solution. This will build the solution – checking for any discrepancies – and push out the database object to a target server. You can do an incremental deployment, where only changes are pushed to the database. You can also do a re-create of the database, although I wouldn't recommend doing this in production. You can also configure to block the deployment if any data loss should occur.
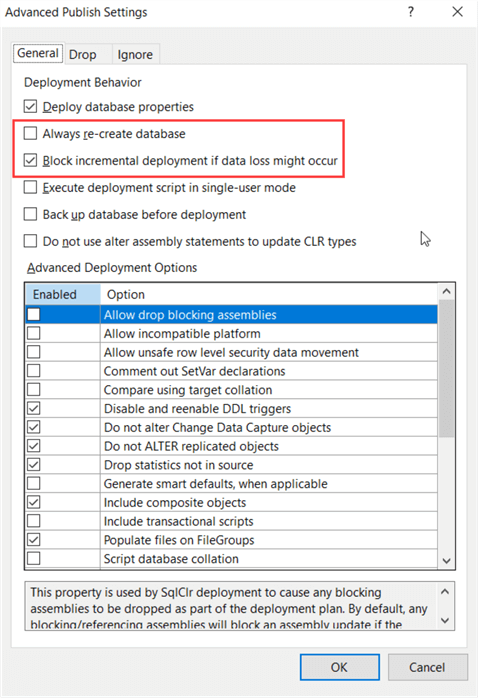
Publishing is useful to push out a brand new database. For example, suppose you have configured a new development server. If you want your database with all the objects but with no data, you can publish the database from SSDT to the new server. If you want data though, a back-up/restore from an existing database might be more useful.
If you frequently push your solution to the same database with the same settings, you can create a publish profile.
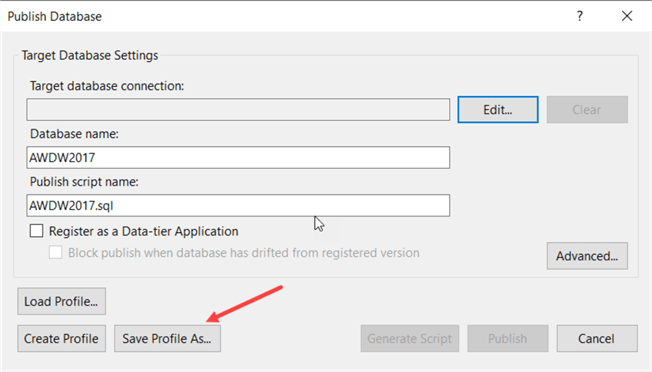
This profile is saved in the solution. Next time you want to publish your database, you can just double click the profile and hit publish.
Another option is to generate a script. This can be useful if you want to inspect which changes SSDT will push to your database.
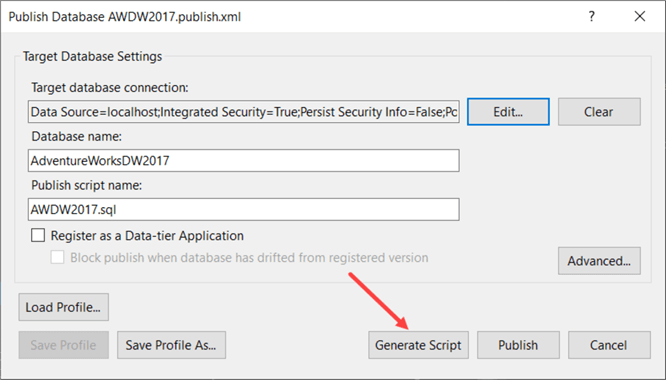
Here you can see a piece of the deployment script when a column has been added to a table:
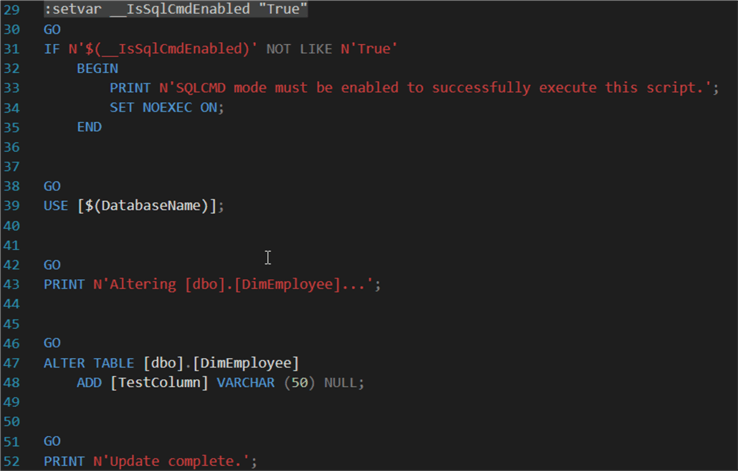
This script uses sqlcmd parameters, so you cannot copy paste it in SQL Server Management Studio (SSMS) and execute it, unless you run in sqlcmd mode (as explained in the tip Using the SSMS Query Editor in SQLCMD Mode).
A script is generated each time you publish, even when you don't choose to generate a script but choose to publish directly. You can find the scripts in the bin/debug folder:
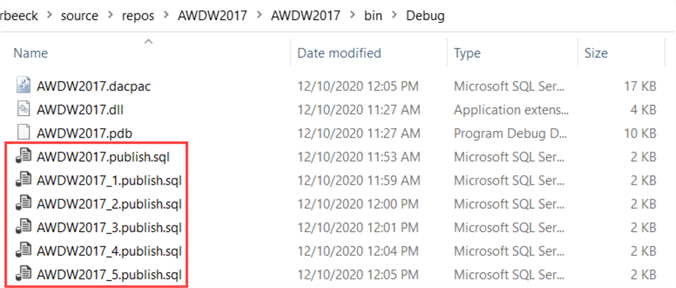
5 – Generate Report with Changes
Every time you build the solution (or publish, which will invoke a build), a .dacpac file is created which contains all the information about the database schema. Using the tool sqlpackage.exe, you can generate an XML report with all the changes that will be deployed when a publish is executed. This tool can be downloaded here.
We can run the following command line command to generate such a report:
sqlpackage /action:DeployReport /SourceFile:"mydatabase.dacpac" /TargetConnectionString:"Data Source=localhost;Integrated Security=True;Initial Catalog=mydatabase" /OutputPath:"C:\temp\DeployReport.xml"
For example:

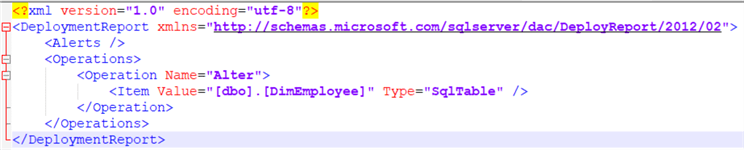
You might want to add the location of the sqlpackage executable to the path environment variable. The following report is generated:
Every time you publish from Visual Studio, a text-based report is generated as well:
However, this report is not as easy to interpret automatically as an XML report:

The combination of sqlpackage.exe and dacpac allows for many automation opportunities. Generating a report is only one of the available options. Check out the documentation for other commands.
6 – Editor and Templates
If you don't like to write the entire SQL for creating a table with many columns, there's a tabular editor where you can enter/edit all of the information:
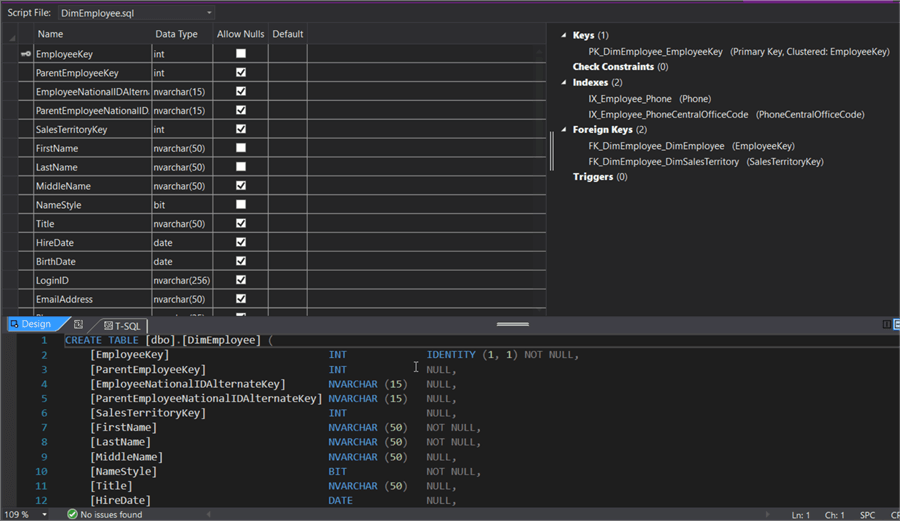
If needed, you can still edit the CREATE TABLE DDL command in the bottom pane.
In SSDT, you can add many different types of objects:
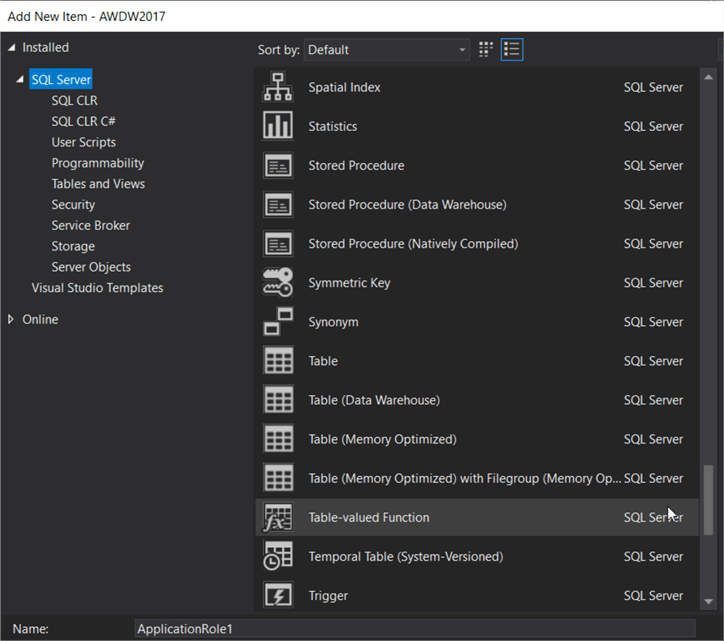
For many of them, a skeleton template will be provided for the new object. For example, here's the one for a table-valued function:
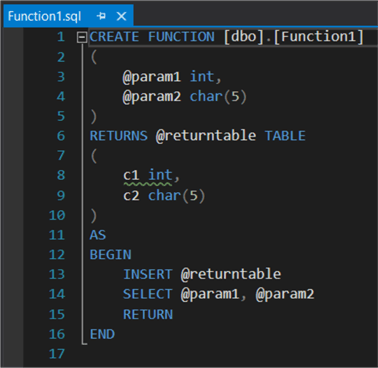
This is useful when you don't know all of the syntax by hard.
7 – Refactor Code
SSDT also supports refactoring. For example, when you rename a table, it will also change the name of the table in objects referencing the table. Suppose we have the following sample table:
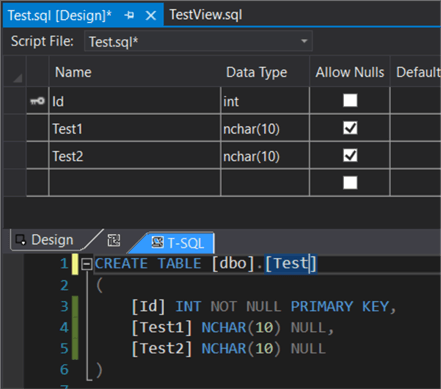
And the following view, which just selects all columns from the table:
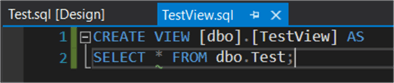
If we rename the table manually in the T-SQL script, this will break the view.
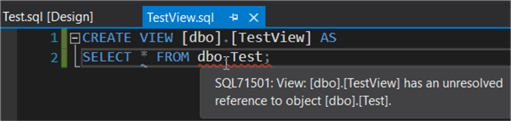
But if we use the refactor functionality, this will update the view as well.
You can also use the refactor functionality to expand wildcards:
Other options for refactoring are fully qualifying object names and moving objects between schemas.
Next Steps
- Of course not every feature of SSDT is described in this tip! You have for example the ability to add pre- and post deployment scripts to the solution, you can run a code analysis and so much more. Do you have a favorite feature not mentioned in the article? Let us know in the comments!
- More info about sqlcmd can be found in the tip Introduction to SQL Server's sqlcmd utility.
- You can find an introduction to sqlpackage and dacpacs in the following tips:
- If you want to learn more about SSDT, there's a whole tutorial available. There's also the tip SQL Server Data Tools Connected Database Development.






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
