By: Fikrat Azizov | Comments | Related: > Azure Synapse Analytics
Problem
Azure Synapse Analytics has introduced Spark support for data engineering needs. This allows processing real-time streaming data, using popular languages, like Python, Scala, SQL. There are multiple ways to process streaming data in the Synapse. In this tip, I will show how real-time data from Azure Cosmos DB can be analyzed, using the Azure Cosmos DB links and the Spark Structured Streaming functionality in Azure Synapse Analytics.
Solution
The streaming data analysis options in Azure Synapse Analytics
The Spark capabilities introduced in the Azure Synapse Analytics, allow processing streaming data in multiple ways.
In one of the previous tips, I’ve illustrated the Synapse pipeline (see Ingest and process real-time data streams with Azure Synapse Analytics) that can consume streaming data directly from the streaming input platforms, like Azure Event Hubs or Azure IoT Hubs, using the Spark Structured Streaming feature (see Structured Streaming Programming Guide for more details). This solution assumes that the involved pipelines will be continuously running.
Azure Synapse Analytics’ ability to reach out to external services like Azure Cosmos DB allows us to build offline stream processing solutions as well. Specifically, we can create an Azure Cosmos DB link and use the Spark engine to build pipelines with either batch or continuous processing modes. In the next sections, we will explore the examples of both pipelines types and see their limitations. If you are not familiar with the Azure Cosmos DB link feature in the Azure Synapse Analytics, I’d recommend you read Explore Azure Cosmos Databases with Azure Synapse Analytics before proceeding further.
An important factor to be considered when processing the Azure Cosmos DB data is whether the Analytical Storage option is enabled for the source Cosmos DB container. When enabled, this option replicates non-structured data in the Cosmos DB container into another storage in a tabular format, which then can be leveraged for Azure Synapse Analytics data analysis (see What is Azure Cosmos DB Analytical Store for more info).
Ingesting the data into the Cosmos DB
I will use the real-time streaming pipeline to fetch Twitter feeds, which I described in Build real-time data pipelines with Azure Event Hub, Stream Analytics and Cosmos DB. Please follow the steps in this tip to build a pipeline, populating an Analytical Storage enabled container twitter_container in the Azure Cosmos DB.
Next, create a container named TwitterOltp_container with similar settings, except with the Analytical Storage option turned off, as follows:
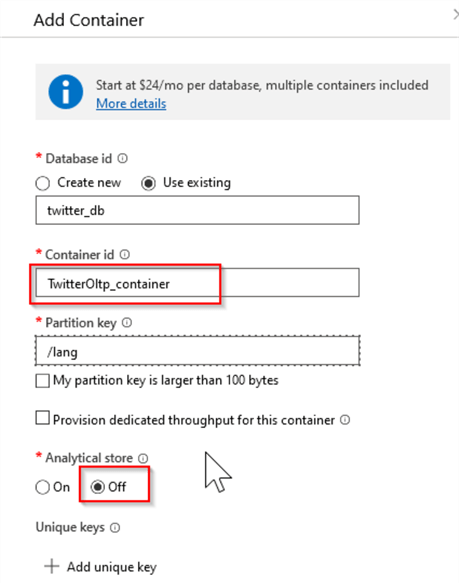
Figure 1
Next, create the Azure Stream Analytics output and query, to populate the newly created container with Twitter feeds. Here is how your Cosmos DB database twitter_db should look at this point:
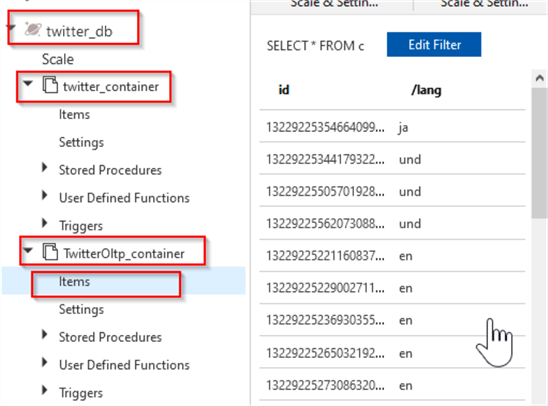
Figure 2
Create Azure Cosmos DB link for Azure Stream Analytics
Now that we have the Azure Cosmos DB database in place, let us create an Azure Stream Analytics link pointing to it and expand that link to ensure that both containers are visible:
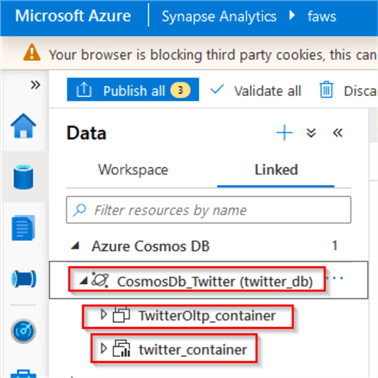
Figure 3
Analyzing the data in the Analytical Storage enabled container
Let us select the Analytical Storage enabled container twitter_container, select the New notebook command and review the available commands:
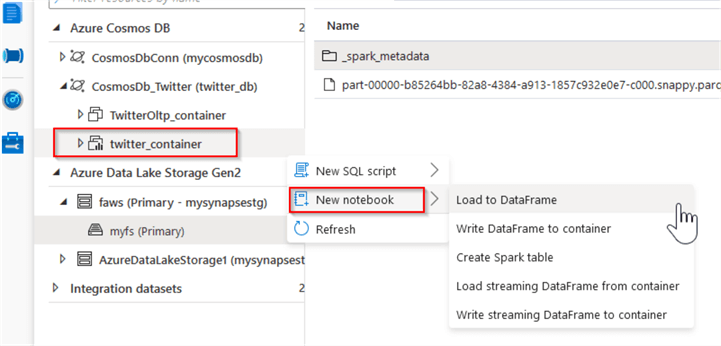
Figure 4
The Load to DataFrame command allows us to perform a batch analysis. Select it and review the following code auto-generated by Azure Stream Analytics:
df = spark.read .format("cosmos.olap") .option("spark.synapse.linkedService", "CosmosDb_Twitter") .option("spark.cosmos.container", "twitter_container") .load() display(df.limit(10))
Notice that cosmos.olap was selected as a data source type for this link. Run this cell and review the results. Among others, the query output contains the fields lang and EventEnqueuedUtcTime fields, which represent the feed language and Event Hub ingestion timestamps:
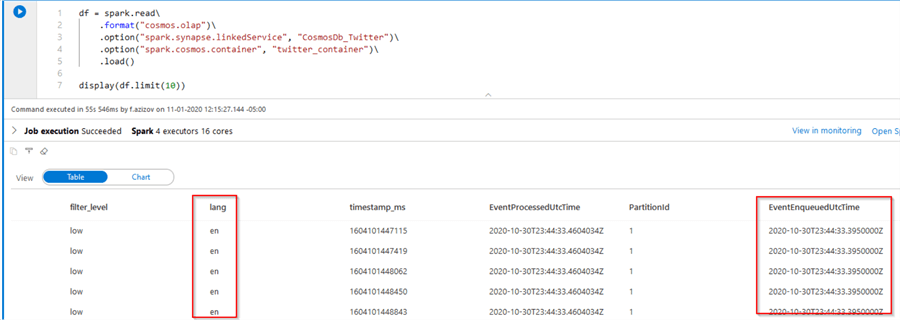
Figure 5
Next, let us execute the following simple aggregation query to count the number of the feeds grouped by the language:
dfAgg=df.groupBy('lang').count().alias('FeedCount') display(dfAgg)
Here are the query results in a chart format:
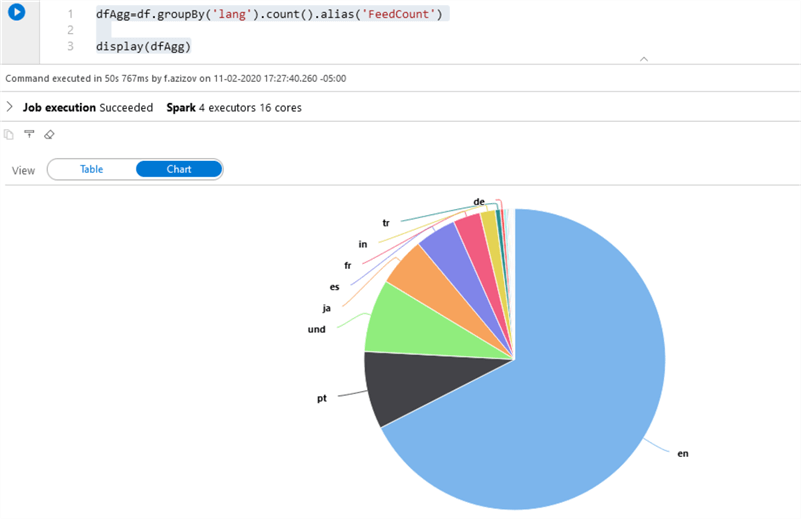
Figure 6
As you can see, we can load static data from Azure Cosmos Db and perform transformations applicable to standard data frames.
Now let us explore the streaming option, by selecting the Load streaming DataFrame from container command:
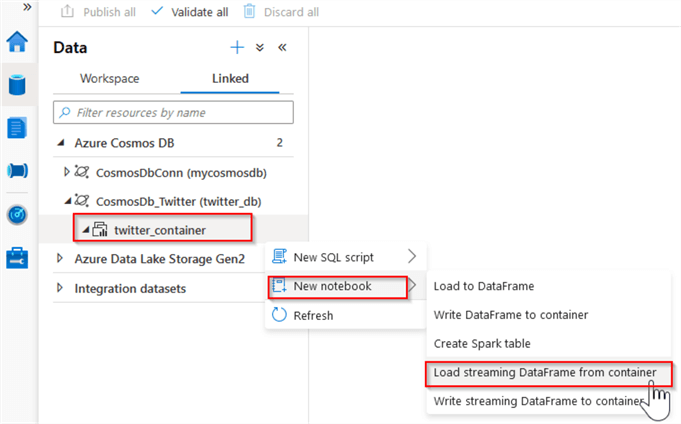
Figure 7
This will generate the following code:
dfStream = spark.readStream .format("cosmos.oltp") .option("spark.synapse.linkedService", "CosmosDb_Twitter") .option("spark.cosmos.container", "twitter_container") .option("spark.cosmos.changeFeed.readEnabled", "true") .option("spark.cosmos.changeFeed.startFromTheBeginning", "true") .option("spark.cosmos.changeFeed.checkpointLocation", "/localReadCheckpointFolder") .option("spark.cosmos.changeFeed.queryName", "streamQuery") .load()
Notice that this query uses Spark’s readStream command, to generate a streaming data frame. Unlike the static data frame, we cannot use Spark’s display command to see the data frame’s content, as this command would simply fail:
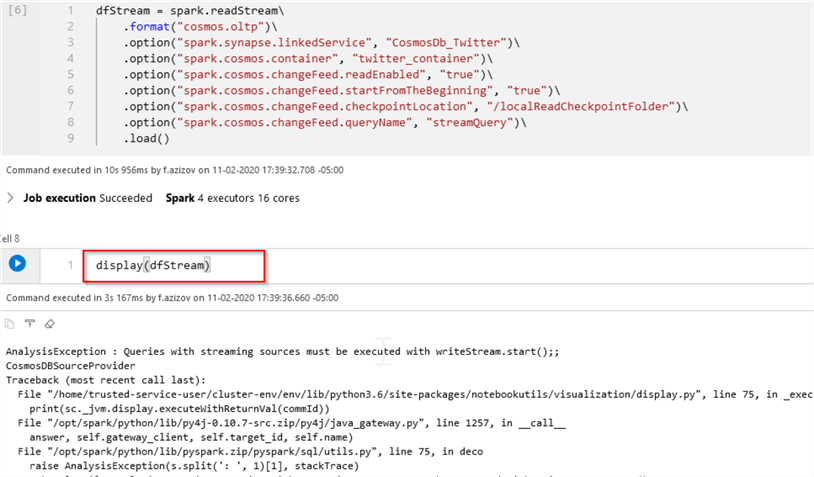
Figure 8
It is worth mentioning that, the Display command does work in Databricks, and simplifies code development and debugging.
Now, let us run the following query, to aggregate the streaming data by the language and event time window and write the results to the storage:
from pyspark.sql.functions import * curStrm=(dfStream .withColumn('EventTime',to_timestamp(col('EventEnqueuedUtcTime'))) .withWatermark("EventTime", "1minutes") .groupBy('lang',window('EventTime', "1minutes")) .count() .writeStream.format('parquet') .option('mode','complete') .option('checkpointLocation','/Twitter/CuratedStream/Logs_parq1/') .option('path','/Twitter/CuratedStream/Data_parq1/') .start()) curStrm.awaitTermination()
Although its syntax is correct, this query fails after a few minutes:
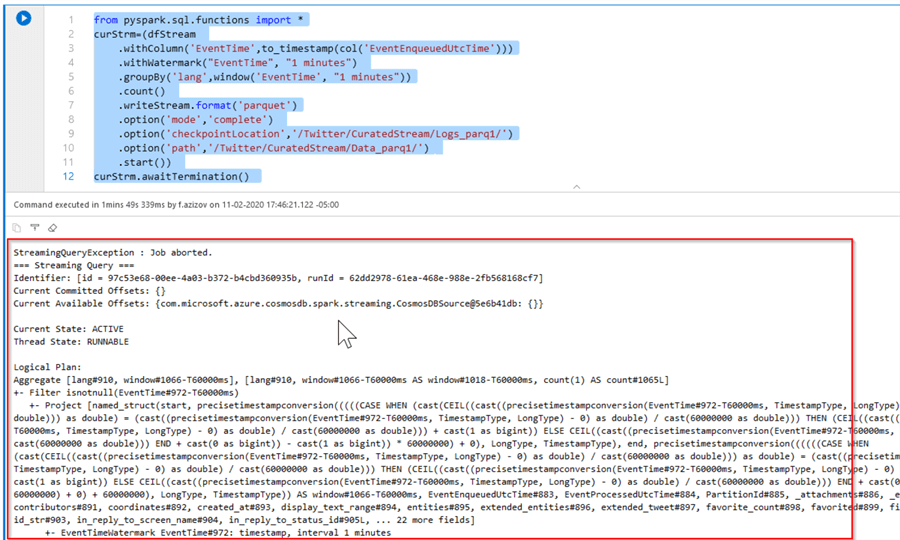
Figure 9
Unfortunately, it’s not possible to troubleshoot the root cause of this problem, based on the error message provided by Azure Stream Analytics, and after some search on online documentation, I’m inclined to think these kinds of transformations are not supported on data streams, based on Analytical Storage enabled container links.
Analyzing the data in the Analytical Storage disabled container
Let us now select the container link for which the Analytical Storage is disabled:
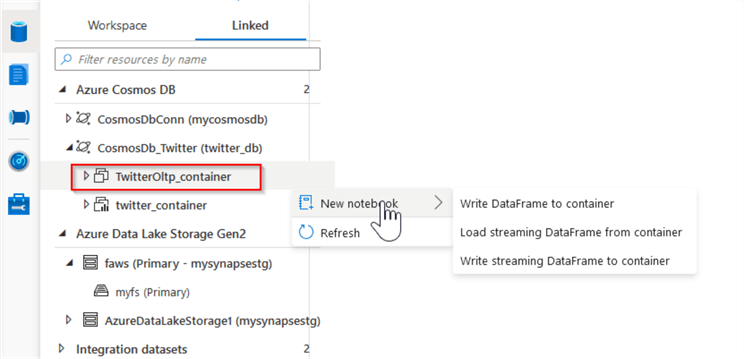
Figure 10
The first thing to notice is that the Load to DataFrame option is not available for this container. This makes sense, considering this link is not meant for batch analysis. Let us use the Load streaming DataFrame from container command, to generate the following query:
dfStreamOltp = spark.readStream .format("cosmos.oltp") .option("spark.synapse.linkedService", "CosmosDb_Twitter") .option("spark.cosmos.container", "TwitterOltp_container") .option("spark.cosmos.changeFeed.readEnabled", "true") .option("spark.cosmos.changeFeed.startFromTheBeginning", "true") .option("spark.cosmos.changeFeed.checkpointLocation", "/localReadCheckpointFolder") .option("spark.cosmos.changeFeed.queryName", "streamQuery") .load()
And run the aggregation query, like to one we used in the previous section:
from pyspark.sql.functions import * curStrm=(dfStreamOltp .withColumn('EventTime',to_timestamp(col('EventEnqueuedUtcTime'))) .withWatermark("EventTime", "1minutes") .groupBy('lang',window('EventTime', "1minutes")) .count() .writeStream.format('parquet') .option('mode','complete') .option('checkpointLocation','/Twitter/CuratedStream/Logs_parq/') .option('path','/Twitter/CuratedStream/Data_parq/') .start()) curStrm.awaitTermination()
This time the aggregation query works and writes the output into storage. To examine the results, let us create another PySpark notebook with the following code:
%%sql CREATE TABLE twitters_parq USING PARQUET LOCATION '/Twitter/CuratedStream/Data_parq/'
This code creates a Spark table, based on the data from the streaming query output. Now that we schematized the data, let’s add this command to browse a sample output:
%%sql select * from twitters_parq limit 100
Here is the screenshot with the query output:
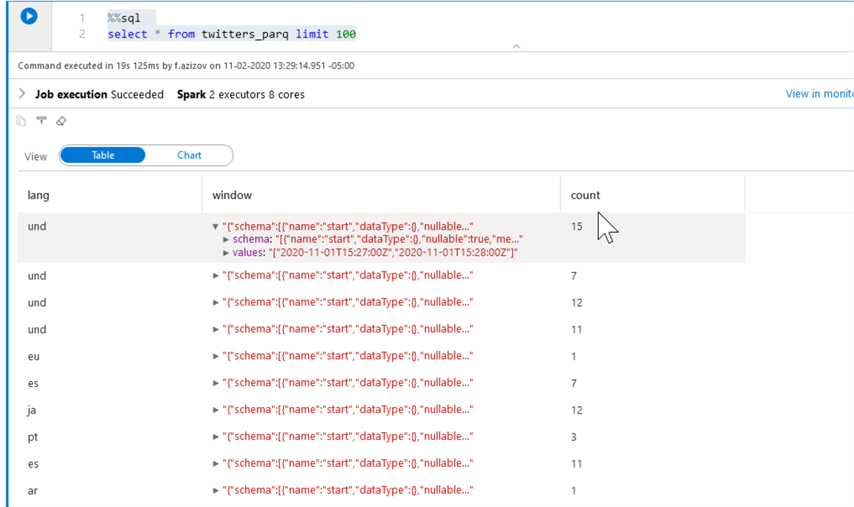
Figure 11
Conclusion
I this tip, we explored the behaviors of the queries based on different-type Cosmos DB links. Based on what we have seen, I am concluding that at this point the links for Analytical Storage enabled Cosmos DB containers are suitable only for batch analysis. Similarly, the Analytical Storage disabled Cosmos DB containers are only good for streaming queries.
This may of course change in the future, considering that the Azure Stream Analytics features discussed here are still in preview.
Next Steps
- Read: Configure and use Azure Synapse Link for Azure Cosmos DB
- Read: Interact with Azure Cosmos DB using Apache Spark in Azure Synapse Link
- Read: Structured Streaming Programming Guide






About the author
 Fikrat Azizov has been working with SQL Server since 2002 and has earned two MCSE certifications. He’s currently working as a Solutions Architect at Slalom Canada.
Fikrat Azizov has been working with SQL Server since 2002 and has earned two MCSE certifications. He’s currently working as a Solutions Architect at Slalom Canada.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
