By: Andrea Gnemmi | Updated: 2023-10-02 | Comments | Related: > PostgreSQL
Problem
Partitioning is a common and effective technique to improve database performance, especially for large tables and when a table is bigger than physical memory. With that said, there are many features, nuances, and differences between PostgreSQL and SQL Server when partitioning that are worth looking into.
Solution
In this tip, we will review the syntax, features, and options used in partitioning tables in PostgreSQL, focusing on the particularities and benefits of this technique.
PostgreSQL Table Partitioning: What is it and What are the Benefits?
First, let's define partitioning and its various benefits and advantages for performance in PostgreSQL.
Partitioning refers to splitting one large table into smaller physical pieces. So, dealing with smaller "sub-tables" in this way can improve query performance dramatically, especially for certain kinds of queries. Moreover, when an index no longer fits easily in memory, both read and write operations on the index take progressively more disk accesses, so dealing with smaller pieces of the index enhances performance.
Some additional benefits include the following:
- Useful for large tables, especially when a table is bigger than physical memory
- Bulk loads or deletes may be accomplished by simply adding or removing one of the partitions
- Avoids VACUUM overhead caused by a bulk DELETE
- Improved UPDATE performance
- Index operations take less time
Examples of when partitioning is useful are:
- When a large table begins having performance issues
- The size of the table has exceeded the physical memory
- Tables greater than 20GB
- Tables containing historical data where the newest data can be added to a new partition. A typical example is where one month of data is frequently updated and 11 months of data is read-only
- When queries only need to access a subset of data
Partitioning Techniques in PostgreSQL
There are two different techniques used in PostgreSQL to partition a table:
- Old method used before version 10 that is done using inheritance
- Declarative partitioning, similar to the one used in SQL Server.
Inheritance is a feature on tables that lets you create a hierarchy between tables. This allows data to be divided according to the user's choice, and triggers must be used to redirect inserted data to the appropriate partition.
This is quite complicated as a lot of the work must be manually done to have a complete solution.
Instead, declarative partitioning can be done in three different ways:
- Range Partitioning: Defined via key column(s) with no overlap or gaps.
- List Partitioning: Explicitly listed for the partitioning scheme.
- Hash Partitioning: Specified by a modulus and a remainder for each partition.
Let's show an example using declarative range partitioning to see all the steps needed!
First, we need to create a new table, declaring it partitioned. This will be the base table:
-- MSSQLTips.com create table test_partition (id_pt bigint generated always as identity, insert_date timestamp, descrizione varchar(20)) partition by range(insert_date);
In this case, we have defined a partition by range based on the partition key column insert_date, so we plan to partition based on a date range.
Now, the second step is to create each partition that will contain the data. They are like sub-tables; we will build them with a CREATE TABLE statement. In this case, we will create a lot of these partitions, so it is a nice idea to use some dynamic SQL to avoid manually writing all the scripts:
-- MSSQLTips.com
CREATE OR REPLACE FUNCTION create_partitions_year(IN table_part_name text,date_start date, date_end date)
RETURNS table(dynamic_sql text) AS
$$
BEGIN
return query select 'CREATE TABLE '||table_part_name||'_'||date_part('year',generate_series(date_start,date_end, '1 years'))||
' partition of '||table_part_name||' for values from ('''||generate_series(date_start,date_end-'1 years'::interval, '1 years')||''''||') to ('||''''||generate_series(date_start+'1 years'::interval,date_end, '1 years')||''''||');';
END;
$$ LANGUAGE plpgsql;
--end function
As you can see, the function accepts three parameters as inputs: the table name, start date, and end date, and returns the script as a table with one column of data type text. Then, it builds the script using dynamic SQL, and in particular, the generate_series function that I already showed in my previous tip on PREPARED statements: PostgreSQL Prepared Statements to Enhance the Performance of Frequently Used Queries.
Now we can call the function and retrieve the scripts:
select create_partitions_year('test_partition','2008-01-01','2024-01-01');
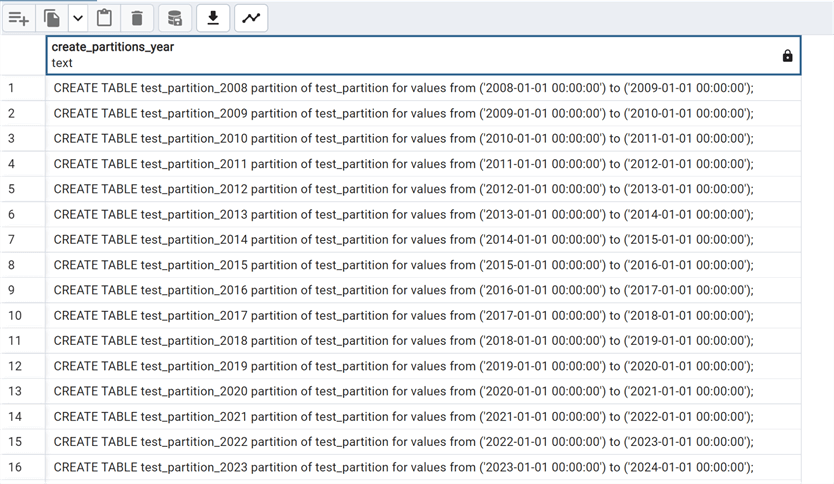
In this way, we can create all the needed partitions.
For the next step, it is important to create an index on every partition based on the partition key used in order to have better performance. As before, it will be a lot of scripts to write manually, so we create another function using dynamic SQL like the previous step.
-- MSSQLTips.com index creation on the column used for partitioning on each partition table
CREATE OR REPLACE FUNCTION create_partitions_index_year(IN table_part_name text,index_column text,date_start date, date_end date)
RETURNS table(dynamic_sql text) AS
$$
BEGIN
return query select 'create index idx_'||table_part_name||'_'||date_part('year',generate_series(date_start,date_end, '1 years'))||' on '||table_part_name||'_'||date_part('year',generate_series(date_start,date_end, '1 years'))||'('||index_column||');';
END;
$$ LANGUAGE plpgsql;
Here, we have four input parameters to determine the start and end date, table name, and index column, and some dynamic SQL to combine them with the generate_series function.
Calling the function, we have all the scripts to create the indexes:
select create_partitions_index_year('test_partition','insert_date','2008-01-01','2023-01-01');
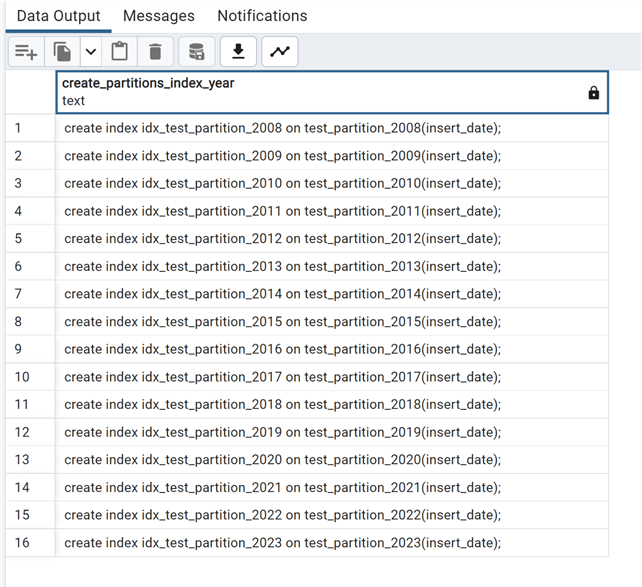
We can now take a look in PgAdmin 4 at the visual representation of a partitioned table:
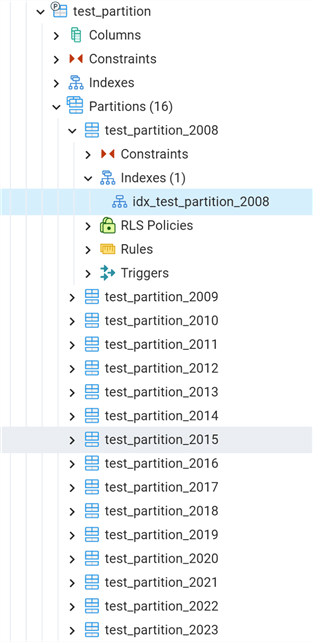
At this point, we can finally insert data in the partitions by using the generate_series function:
--MSSQLTips.com
insert into test_partition (insert_date, descrizione)
values(generate_series('2008-02-24 00:00'::timestamp,
'2023-05-11 13:10', '10 minutes'), 'descrizione'||generate_series(1,800000)::varchar);
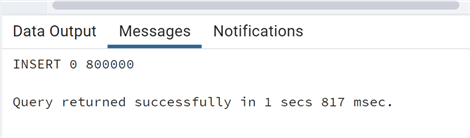
Now, let's query the data and see the execution plan:
--MSSQLTips.com select * from test_partition where insert_date>='2022-01-01';
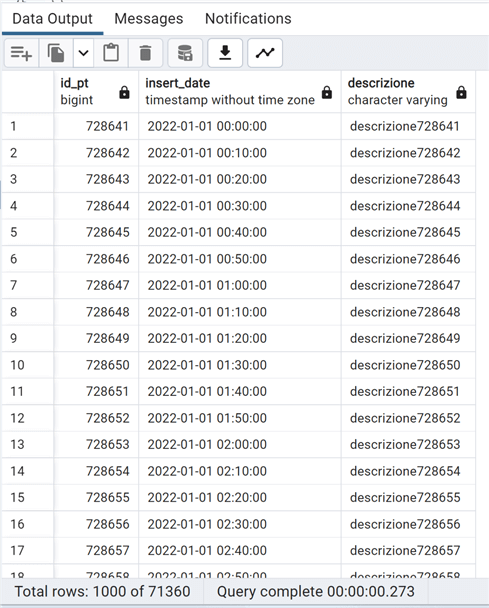

As you can see, the query is fast and, looking at the execution explain plan, we can see that PostgreSQL does just a sequential scan on the two partitions that have data related to our filter, completely ignoring the other partitions, thus giving us a clear performance advantage over a normal table. We have a sequential scan because the WHERE clause does not remove any row from these two partitions; thus, the optimizer is not using the index we have on the partitions.
This is done by design; it's called Partition Pruning and comes with its own features and caveats.
First, the query filter must use the partitioning key column like in our example. Second, it can be controlled by a parameter named enable_partition_pruning. Let's see it in action, turning off the feature:
set enable_partition_pruning=off;
Doing an EXPLAIN ANALYZE on the same query:
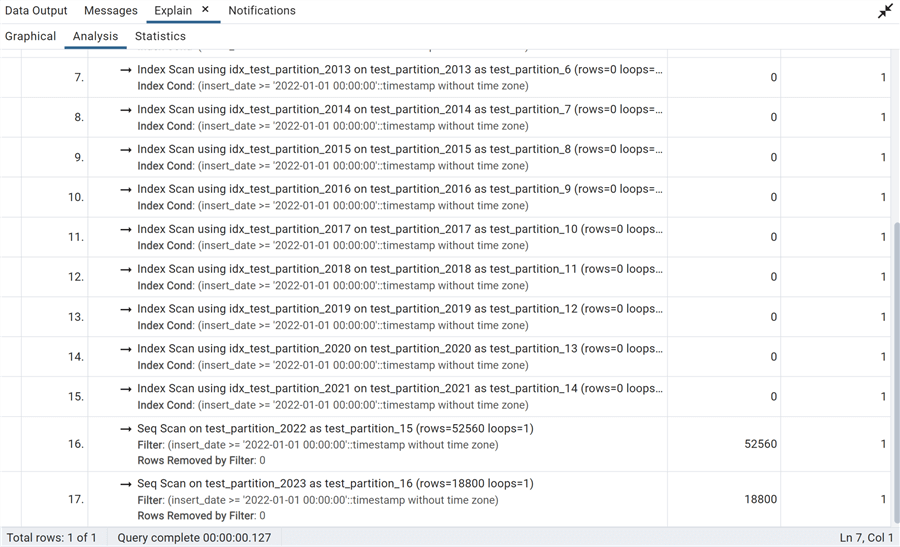
We can see that the optimizer has devised a plan to do an index scan on each partition of the whole table and a sequential scan on the two partitions containing data for our filter. We can also see it graphically, which gives a better idea of the amount of extra work that is done concerning the previous plan:

Attach and Detach Partitions
An existing table can be added or attached as a partition to an existing partitioned table. In the same way, an existing partition can be converted into a standalone table. Actually, Detach Partition is the best practice to delete or archive rows from a partitioned table because, in this way, we avoid an exclusive lock on the whole table.
Let's try a couple of examples. First, let's detach a partition and then drop the resulting table:
--MSSQLTips.com ALTER TABLE test_partition DETACH PARTITION test_partition_2008;
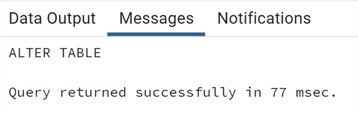
Easily detached, as you can see. Now we see in the pgAdmin 4 GUI that the partition is no longer part of the original partitioned table, but it is now a separate table:
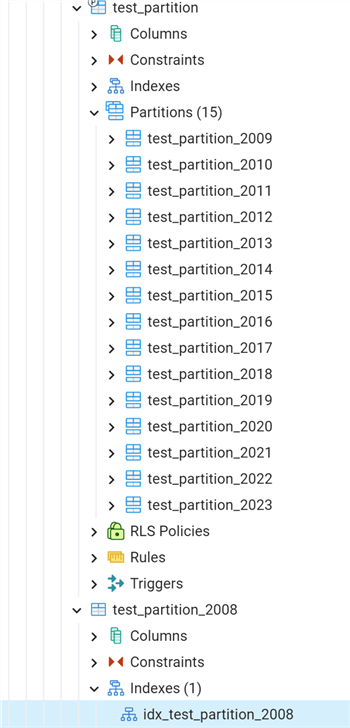
Now, we can test a simple query against this table and see its EXPLAIN PLAN:
--MSSQLTips.com select * from test_partition_2008 where insert_date>='2008-09-10';
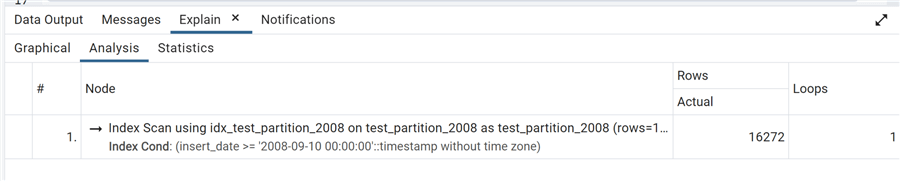
As we can see, the query uses the index created on the partition and inherited by the detached table.
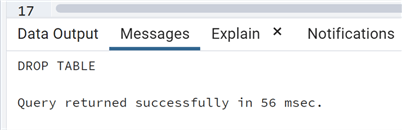
We can now proceed to drop the table, resulting in the complete deletion of all the rows of 2008:
drop table test_partition_2008;
Now, if we want to add an existing normal table as a new partition to a partitioned table, we must be careful on the checks side to ensure the integrity. Let's do an example creating a new table test_partition:
--MSSQLTips.com drop table if exists test_attach; create table test_attach (like test_partition);

Note: I have used two syntaxes of PostgreSQL SQL dialect:
- IF EXIST, in order not to have an error with the create or drop table,
- LIKE, to create a new table using exactly the same column names and data types of another table, in this case, our test_partition table.
Another thing to note is that we have created the table using LIKE without any INCLUDE option. Notably, I should have used INCLUDING IDENTITY. In this way, we now need to add an identity column to our new table:
alter table test_attach alter column id_pt add GENERATED BY DEFAULT as identity;
We can see our table in pgAdmin:
Important: We need to add a constraint to check that the values (that will be added for a second time to a partition) are complying with that partition; in this case, we want to add another year:
alter table test_attach ADD CONSTRAINT y2024 CHECK (insert_date >='2024-01-01' and insert_date < '2025-01-01');
We can now insert the data using a script similar to the one already used on the partitioned table:
insert into test_attach (insert_date, descrizione)
values(generate_series('2024-01-01 00:00'::timestamp,
'2025-01-01 00:00', '10 minutes'), 'descrizione'||generate_series(1,52560)::varchar);
We get an error as the last value inserted goes against the check constraints:

So we correct the insert script and retry:
insert into test_attach (insert_date, descrizione)
values(generate_series('2024-01-01 00:00'::timestamp,
'2024-12-31 23:59', '10 minutes'), 'descrizione'||generate_series(1,52560)::varchar);
Now, we can finally try to attach this table to the partitioned table as a new partition:
alter table test_partition attach partition test_attach FOR VALUES FROM ('2024-01-01') TO ('2025-01-01');
And check it in pgAdmin:
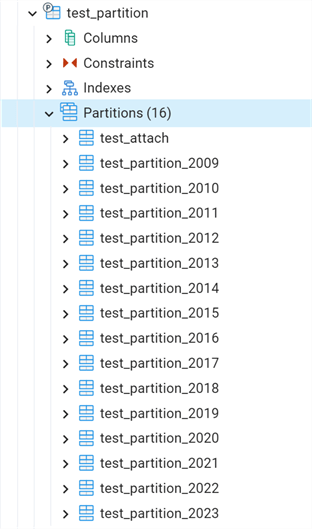
We can see that our test_attach table is now a new partition on the test_partition table.
Conclusions
In this tip, we have reviewed the concept of partitions in PostgreSQL, the query benefits, the concept of partition pruning, and how to attach and detach partitions.
Next Steps
- Link to the official documentation on PostgreSQL Table Partitioning: 5.10. Table Partitioning
- Links to other tips regarding partitioning:
- Links for sharding: Database Sharding to Help Improve Performance and Maintenance Tasks






About the author
 Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.
Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-10-02
