By: Greg Robidoux | Comments (23) | Related: > Backup
Problem
Have you ever wished you could get your backups to run faster? Well there may be a way, by writing to multiple files. Creating SQL Server backups is pretty simple to do; you can use the SQL Server management tools or you can use T-SQL commands to issue the backup. But sometimes with large databases it takes a long time to run and it is difficult to copy this very large file across the network or even to your backup tapes.
Solution
Write your database backup to multiple files. In addition to writing your database backup to one file you have the ability to write to multiple files at the same time and therefore split up the workload. The advantage to doing this is that the backup process can run using multiple threads and therefore finish faster as well as having much smaller files that can be moved across the network or copied to a CD or DVD. Another advantage to writing to multiple files is if you have multiple disk arrays you can write your backup files to different arrays and therefore get better I/O throughput. One thing to note is that to maintain the I/O throughput you should keep the writing of your backup files and the reading of the database file on different disk arrays.
Here are two ways of writing your backup to multiple files:
Backup to multiple files using SQL Server Management Studio
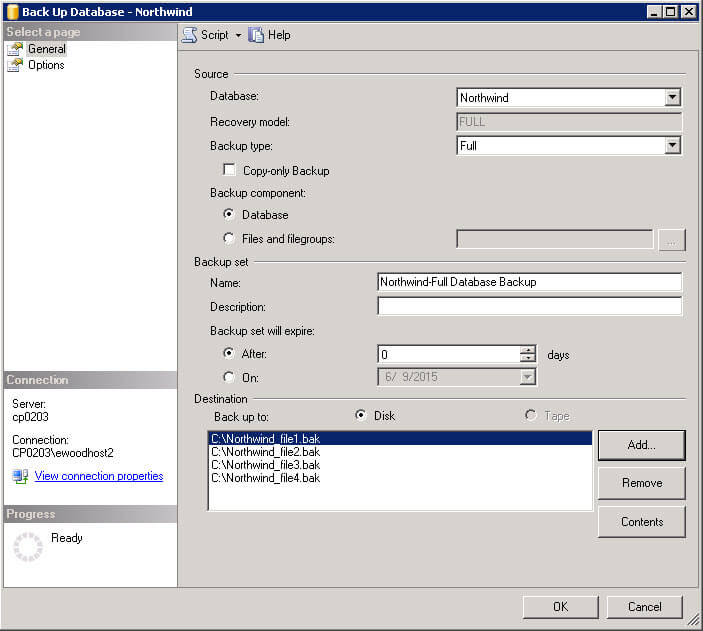
In SQL Server Enterprise Manager you have the ability to add additional destination files. Just click "Add" and you can add an additional output file. In the example below everything is going to the C:\ drive, but for faster I/O throughput you would want to write to different drives.
Backup to multiple files using T-SQL
Using T-SQL you would write your backup command similar to the following:
BACKUP DATABASE [Northwind] TO
DISK = 'C:\Northwind_file1.bak',
DISK = 'D:\Northwind_file2.bak',
DISK = 'E:\Northwind_file3.bak',
DISK = 'F:\Northwind_file4.bak'
WITH INIT , NOUNLOAD , NAME = 'Northwind backup', NOSKIP , STATS = 10, NOFORMAT
Next Steps
- Test writing your backups to multiple files to see how much faster you can get your backups to run.
- Size the backup files for your needs, whether you need to fit them on a CD or DVD or whether you just want to make the copy across your network easier. To size the file look at the size of the current database backup file and divide it by the size of the files you want to create.
- See if this makes sense to implement in your environment and then plan to make the change.
- In addition to doing this using native SQL Server backups, there are several products in the market that allow you to backup to multiple files and compress the files at the same time. This allows you to have even smaller files and therefore further decrease the time to move the files around your network.






About the author
 Greg Robidoux is the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server. He is also one of the co-founders of MSSQLTips.com. Greg has been working with SQL Server since 1999, has authored numerous database-related articles, and delivered several presentations related to SQL Server. Before SQL Server, he worked on many data platforms such as DB2, Oracle, Sybase, and Informix.
Greg Robidoux is the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server. He is also one of the co-founders of MSSQLTips.com. Greg has been working with SQL Server since 1999, has authored numerous database-related articles, and delivered several presentations related to SQL Server. Before SQL Server, he worked on many data platforms such as DB2, Oracle, Sybase, and Informix.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
