By: Koen Verbeeck
Overview
When you've created your pipelines, you're not going to run them in debug mode every time you need to transfer some data. Rather, you want to schedule your pipelines so that they run on pre-defined point in times or when a certain event happens. When using Integration Services projects, you would use for example SQL Server Agent to schedule the execution of your packages.
Scheduling
In ADF, a "schedule" is called a trigger, and there are a couple of different types:
- Run-once trigger. In this case, you are manually triggering your pipeline so that it runs once. The difference between the manual trigger and debugging the pipeline, is that with a trigger you're using the pipeline configuration that is saved to the server. With debugging, you're running the pipeline as it is in the visual editor.
- Scheduled trigger. The pipeline is being run on schedule, much like SQL Server Agent has schedules. You can for example schedule a pipeline to run daily, weekly, every hour and so on.
- Tumbling window trigger. This type of trigger fires at a periodic interval. A tumbling window is a series of fixed-sized, non-overlapping time intervals. For example, you can have a tumbling window for each day. You can set it to start at the first of this month, and then it will execute for each day of the month. Tumbling triggers are great for loading historical data (e.g. initial loads) in a "sliced" manner instead of loading all data at once.
- Event-based trigger. You can trigger a pipeline to execute every time a specific event happens. You can start a pipeline if a new file arrives in a Blob container (storage event), or you can define your own custom events in Azure Event Grid.
Let's create a trigger for the pipeline we created earlier. In the pipeline, click on Add Trigger.
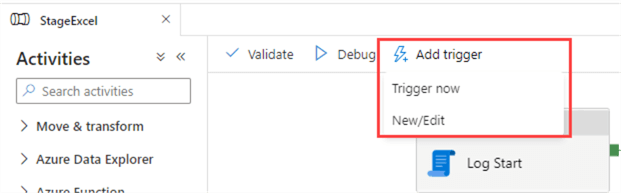
If you choose "Trigger Now", you will create a run-once trigger. The pipeline will run and that's it. If you choose "New/Edit", you can either create a trigger or modify an existing one. In the Add triggers pane, open the dropdown and choose New.
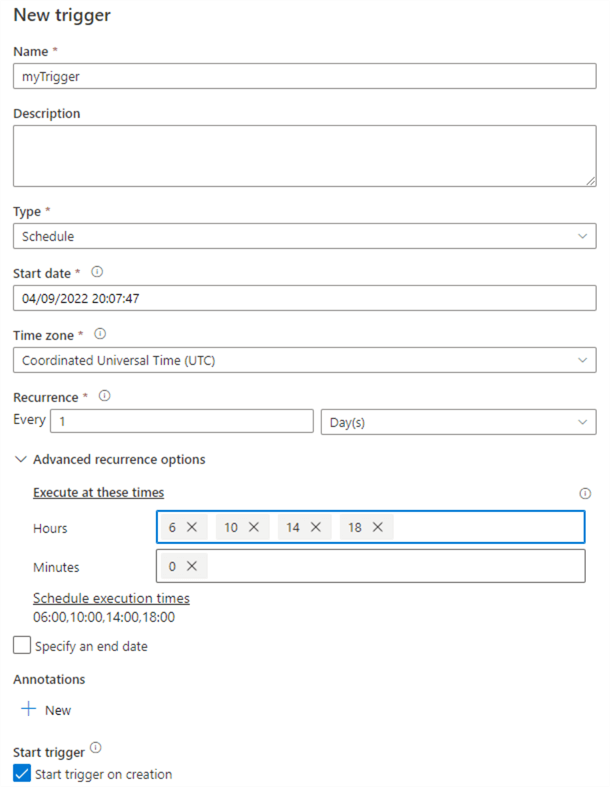
The default trigger type is Schedule. In the example below, we've scheduled our pipeline to run every day, for the hours 6, 10, 14 and 18.
Once the trigger is created, it will start running and execute the pipeline according to schedule. Make sure to publish the trigger after you've created it. You can view existing triggers in the Manage section of ADF.
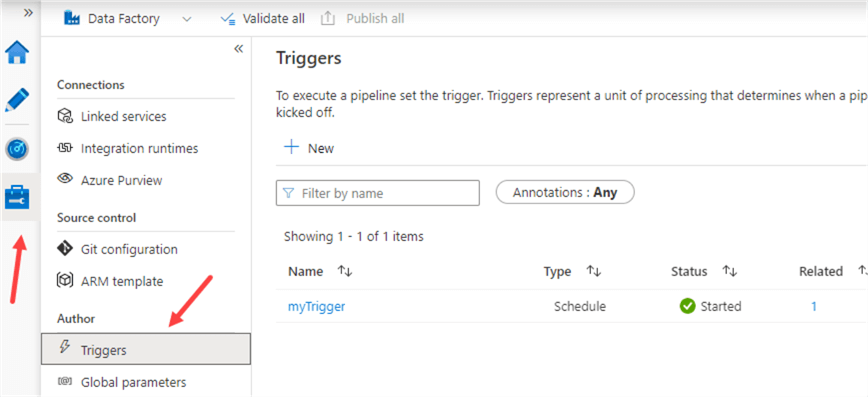
You can pause an existing trigger, or you can delete it or edit it. For more information about triggers, check out the following tips:
- Create Event Based Trigger in Azure Data Factory>
- Create Schedule Trigger in Azure Data Factory ADF
- Create Tumbling Window Trigger in Azure Data Factory ADF
ADF has a REST API which you can also use to start pipelines. You can for example start a pipeline from an Azure Function or an Azure Logic App.
Monitoring
ADF has a monitoring section where you can view all executed pipelines, both triggered or by debugging.
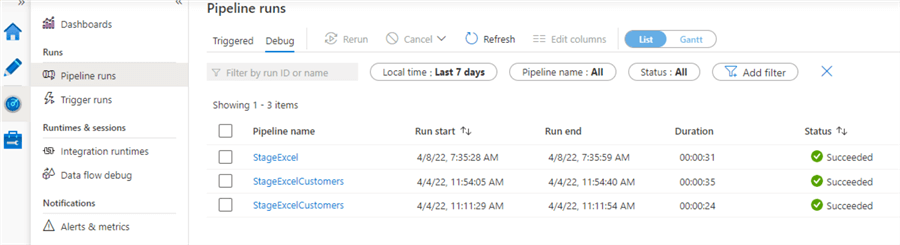
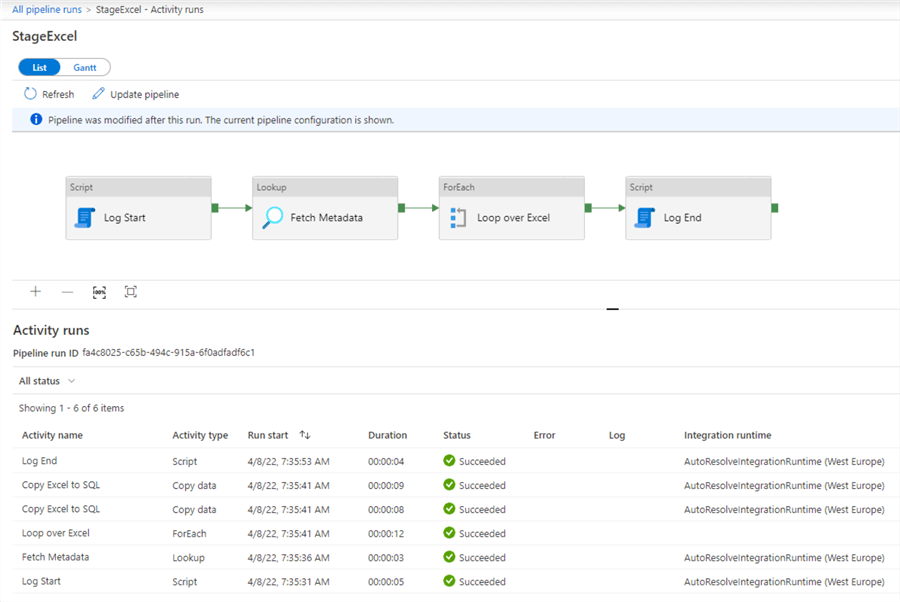
You can also view the state of the integration runtimes or view more info about the data flows debugging sessions. For each pipeline run, you can view the exact output and the resource consumption of each activity and child pipeline.
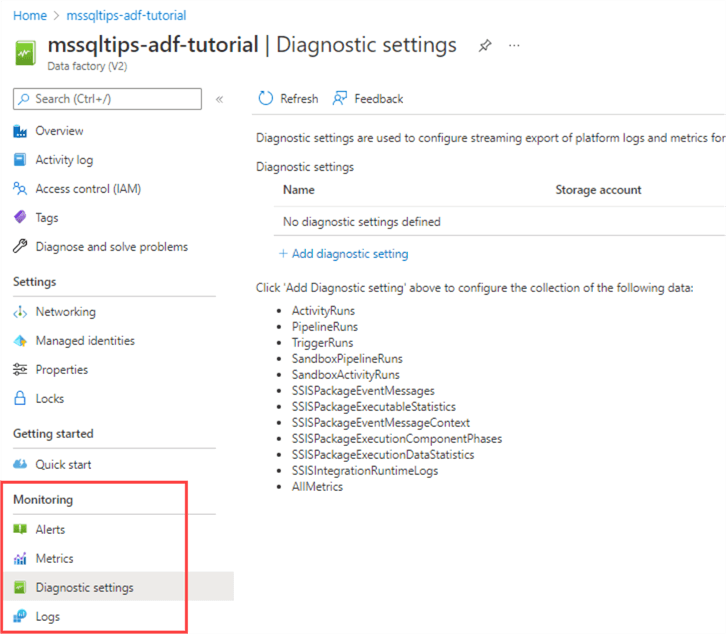
It's also possible to configure Log analytics for ADF in the Azure Portal. It's out of scope for this tutorial, but you can find more info in the tip Setting up Azure Log Analytics to Monitor Performance of an Azure Resource. You can check out the Monitoring section for the ADF resource in the Azure Portal:
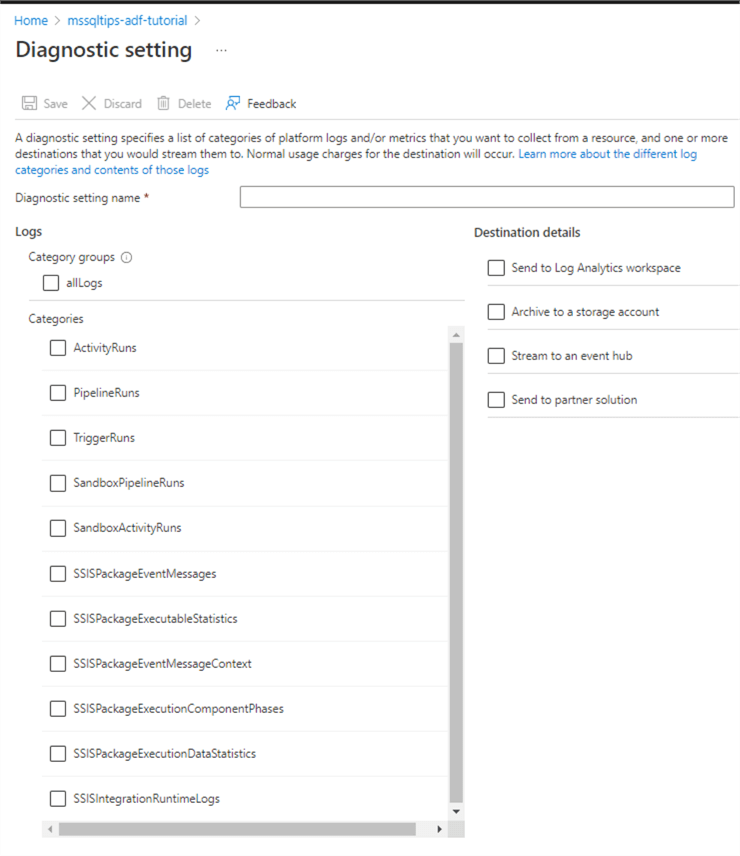
You can choose the type of events that are being logged:
Additional Information
- You can find more info on logging and error handling in the following tips:
- More info about log analytics:
