Problem
There are numerous use cases for multi-file imports of CSV files into a SQL Server table:
- Dynamic SQL Server bulk insert loads are especially appropriate for tasks that extract content from multiple files to a SQL Server table where the source file names change between successive import jobs.
- Static bulk insert loads target scenarios where the source file names do not change between successive import jobs.
Solution
Which type of import job is best for a particular assignment can depend on the number of files being imported and the willingness to learn how to integrate bulk insert statements with dynamic SQL, file control tables, and while loops.
Static versus Dynamic Bulk Inserts
The key feature of a static bulk insert application is that each source file is directly referenced in your T-SQL code. Static bulk insert applications rely on source file names that do not change across successive loads. While the file names are the same across successive loads, the content of the files can vary between loads. For example, initial testing of a static bulk insert application can be for files with relatively small datasets. When it is determined that the code is what you ultimately need, then you can re-run the solution for all available data.

In contrast, the key feature of a dynamic bulk insert application is that a control table contains the file names to be loaded. The T-SQL code for this type of application performs the same kind of load for each file named in the file control table, but the file control table can be populated with different file names in successive runs. The ability to alter the files loaded in successive re-runs is one reason the application is dynamic. The dynamic bulk insert code sample in this tip also demonstrates the use of dynamic SQL with a bulk insert statement.
Both approaches in this tip write the file contents to the same permanent table (dbo.ticker_date_price). If you wish to preserve the permanent table’s contents from any run, you can manually rename the table. Both the static and dynamic solutions create a fresh version of a standard permanent table for every re-run of each solution.
Sample Code for the Static Solution
There are five parts to the script example for loading three CSV files via a static bulk load solution into a SQL Server table.
Part 1
In Part 1, which appears in the following screen excerpt, has three elements:
- The use statement that specifies the T-SQLDemos database as the default database for the script.
- An if statement for conditionally removing the dbo.ticker_date_price table and its primary key constraint from the default database.
- A create table statement for the dbo.ticker_date_price table. This table stores contents from each of the three CSV files in parts 2, 3, and 4.
-- Part 1
use [T-SQLDemos];
-- Drop constraint only if the table and constraint both exist
-- then unconditionally drop table
if object_id('dbo.ticker_date_price', 'U') is not null
begin
if exists (
select 1
from sys.objects
where name = 'pk_ticker_date' and type = 'PK'
)
begin
alter table dbo.ticker_date_price
drop constraint pk_ticker_date;
end
drop table dbo.ticker_date_price;
end
create table dbo.ticker_date_price (
ticker nvarchar(10),
date date,
price decimal(10,2)
constraint pk_ticker_date PRIMARY KEY (ticker, date)
);Part 2
The code for Part 2 appears below. The if statement at the top of part 2 and its trailing drop table statement conditionally remove the dbo.IWM_1993_1_22_2025_7_31 table from the T-SQLDemos database. Then, a create table statement adds a fresh copy of the dbo.IWM_1993_1_22_2025_7_31 table to the database. Next, a bulk insert statement populates the dbo.IWM_1993_1_22_2025_7_31 table with contents from the IWM_1993_1_22_2025_7_31.csv file in the C:\CSVsForSQLServer path. In other words, the dbo.IWM_1993_1_22_2025_7_31 serves as a staging table. Part 2 concludes with an insert into statement from a select statement. The list for the select statement includes a string constant (‘IWM’) and the date and price columns inserted into the dbo.IWM_1993_1_22_2025_7_31 table.
-- Part 2
-- conditionally drop dbo.IWM_1993_1_22_2025_7_31
-- then create a fresh version of dbo.IWM_1993_1_22_2025_7_31
if exists (
select 1
from sys.objects
where object_id = object_id('dbo.IWM_1993_1_22_2025_7_31')
and type = 'U'
)
drop table dbo.IWM_1993_1_22_2025_7_31;
create table dbo.IWM_1993_1_22_2025_7_31 (
date date,
price decimal(10,2)
);
-- run the bulk insert statement
-- to populate the dbo.IWM_1993_1_22_2025_7_31 table
-- from a csv file in the
-- 'C:\CSVsForSQLServer path
bulk insert dbo.IWM_1993_1_22_2025_7_31
from 'C:\CSVsForSQLServer\IWM_1993_1_22_2025_7_31.csv'
--'C:\Users\Public\Downloads\orders.txt'
with (
firstrow = 2,
fieldterminator = ',',
rowterminator = '\n',
tablock
);
-- copy data with a ticker prefix
-- to dbo.ticker_date_name
insert into dbo.ticker_date_price
select 'IWM' ticker, date, price
from dbo.IWM_1993_1_22_2025_7_31Part 3
The code for Part 3 appears next. This code adds rows to the dbo.DIA_1993_1_22_2025_7_31 table from a bulk insert statement. The input to the bulk insert statement is the DIA_1993_1_22_2025_7_31.csv file in the C:\CSVsForSQLServer path. The dbo.DIA_1993_1_22_2025_7_31 table is, in turn, used to add rows to the dbo.ticker_date_price table.
-- Part 3
-- conditionally drop dbo.DIA_1993_1_22_2025_7_31
-- then create a fresh version of dbo.DIA_1993_1_22_2025_7_31
if exists (
select 1
from sys.objects
where object_id = object_id('dbo.DIA_1993_1_22_2025_7_31')
and type = 'U'
)
drop table dbo.DIA_1993_1_22_2025_7_31;
create table dbo.DIA_1993_1_22_2025_7_31
(
date date,
price decimal(10,2)
);
-- run the bulk insert statement
-- to populate the dbo.DIA_1993_1_22_2025_7_31 table
-- from a csv file in the
-- C:\Users\Public\Downloads path
bulk insert dbo.DIA_1993_1_22_2025_7_31
from 'C:\CSVsForSQLServer\DIA_1993_1_22_2025_7_31.csv'
with (
firstrow = 2,
fieldterminator = ',',
rowterminator = '\n',
tablock
);
-- copy data with a ticker prefix
-- to dbo.ticker_date_name
insert into dbo.ticker_date_price
select 'DIA' ticker, date, price
from dbo.DIA_1993_1_22_2025_7_31Part 4
Next is the code for Part 4. This code adds rows to the dbo.SPY_1993_1_22_2025_7_31 table from a bulk insert statement with input from the SPY_1993_1_22_2025_7_31.csv table in the C:\CSVsForSQLServer path. The dbo.SPY_1993_1_22_2025_7_31 table is, in turn, used to add rows to the dbo.ticker_date_price table. After the insert into the dbo.ticker_date_price table in part 4, the dbo.ticker_date_price table is populated with data from all three CSV files.
-- Part 4
-- conditionally drop dbo.SPY_1993_1_22_2025_7_31
-- then create a fresh version of dbo.SPY_1993_1_22_2025_7_31
-- in the [T-SQLDemos] database
if exists (
select 1
from sys.objects
where object_id = object_id('dbo.SPY_1993_1_22_2025_7_31')
and type = 'U'
)
drop table dbo.SPY_1993_1_22_2025_7_31;
create table dbo.SPY_1993_1_22_2025_7_31 (
date date,
price decimal(10,2)
);
-- run the bulk insert statement
-- to populate the dbo.SPY_1993_1_22_2025_7_31 table
-- from a csv file in the
-- C:\Users\Public\Downloads path
bulk insert dbo.SPY_1993_1_22_2025_7_31
from 'C:\CSVsForSQLServer\SPY_1993_1_22_2025_7_31.csv'
with (
firstrow = 2,
fieldterminator = ',',
rowterminator = '\n',
tablock
);
-- copy data with a ticker prefix
-- to dbo.ticker_date_name
insert into dbo.ticker_date_price
select 'SPY' ticker, date, price
from dbo.SPY_1993_1_22_2025_7_31Part 5
The code for Part 5 appears next. This part displays all the rows in the dbo.ticker_date_price table in primary key order. Recall that Part 1 includes a primary key constraint for the dbo.ticker_date_price table in its create table statement.
-- Part 5
-- display data across all tickers
select *
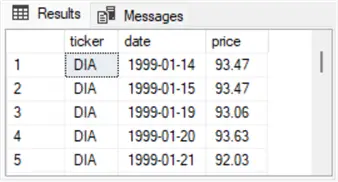
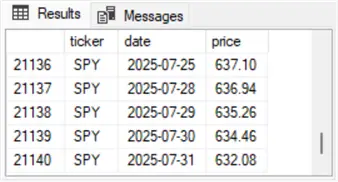
from dbo.ticker_date_priceThe following pair of screenshots displays the first five and last five data rows from the dbo.ticker_date_price table. As you can see, the first five rows are for the DIA ticker, and the last five rows are for the SPY ticker. The rows for the IWM ticker are between the last row for the DIA ticker and the first five row for the SPY ticker.
Sample Code for the Dynamic Solution
The next script contains the parts for dynamically importing a set of files into a SQL Server table. The comments within the sample script highlight important details. There are two key elements to the script:
- A temp ticker_files table holds a ticker, as well as the file path and name on each table row. The example is for financial tickers, but that is not material to the solution approach. For example, if you were attempting to track contact information for employees by department, you could replace ticker with a department identifier and file path and name with the path and file name for the employee contact information maintained by each department.
- The while loop in Part 4 of the script includes dynamic SQL that successively extracts rows from the #ticker_files table and passes values to a bulk insert statement in a dynamic SQL code segment that populates the #staging_price_data table. Then, an insert into statement, which derives values from a trailing select statement, populates the current row for the dbo.ticker_date_price table.
use [T-SQLDemos]
-- Part 1 Create a temp control table to hold tickers and file paths
-- Control table for tickers and file paths
if object_id('tempdb..#ticker_files') is not null
drop table #ticker_files;
create table #ticker_files (
ticker nvarchar(10),
filepath nvarchar(255)
);
insert into #ticker_files (ticker, filepath)
values
('IWM', 'C:\CSVsForSQLServer\IWM_1993_1_22_2025_7_31.csv'),
('DIA', 'C:\CSVsForSQLServer\DIA_1993_1_22_2025_7_31.csv'),
('SPY', 'C:\CSVsForSQLServer\SPY_1993_1_22_2025_7_31.csv');
-- Part 2 Create a consolidated table
if object_id('dbo.ticker_date_price', 'U') is not null
drop table dbo.ticker_date_price;
create table dbo.ticker_date_price (
ticker nvarchar(10),
date date,
price decimal(10,2),
constraint pk_ticker_date primary key (ticker, date)
);
-- Part 3 Create a reusable staging table
if object_id('tempdb..#staging_price_data') is not null
drop table #staging_price_data;
create table #staging_price_data (
date date,
price decimal(10,2)
);
-- Part 4 Loop through control table
declare @ticker nvarchar(10), @file nvarchar(255), @sql nvarchar(max);
while exists (select 1 from #ticker_files)
begin
select top 1 @ticker = ticker, @file = filepath from #ticker_files;
truncate table #staging_price_data;
set @sql = '
bulk insert #staging_price_data
from ''' + @file + '''
with (
firstrow = 2,
fieldterminator = '','',
rowterminator = ''\n'',
tablock
);';
exec(@sql);
insert into dbo.ticker_date_price (ticker, date, price)
select @ticker, date, price from #staging_price_data;
delete from #ticker_files where ticker = @ticker;
end
-- Part 5 Display the consolidated table
select * from [dbo].[ticker_date_price]Compute Overall Percentage Price Change by Ticker from a Designated Start Date
The following script is a basic one that hints at some of the analyses you can apply to the [dbo].[ticker_date_price] table in the [T-SQLDemos] database. The script computes the overall percentage change from a start date (2000-05-30) through to the most recent date for a ticker. For the sample data used in this tip, all three tickers have the same most recent date (2025-07-31).
use [T-SQLDemos]
-- declare @start_date
declare @start_date date = '2000-05-30'
-- percentage price change from
-- 2000-05-30 to most recent DIA date
select
cast((((select price
from [dbo].[ticker_date_price]
where
ticker = 'DIA' and
date = (
select max(date)
from [dbo].[ticker_date_price]
where ticker = 'DIA'))
/
(select price
from [dbo].[ticker_date_price]
where
ticker = 'DIA' and
date = (@start_date)))-1)*100 as decimal(6,2))
[DIA Overall Percentage Price Change]
------------------------------------------------
-- percentage price change from
-- 2000-05-30 to most recent IWM date
select
cast((((select price
from [dbo].[ticker_date_price]
where
ticker = 'IWM' and
date = (
select max(date)
from [dbo].[ticker_date_price]
where ticker = 'IWM'))
/
(select price
from [dbo].[ticker_date_price]
where
ticker = 'IWM' and
date = (@start_date)))-1)*100 as decimal(6,2))
[IWM Overall Percentage Price Change]
------------------------------------------------
-- percentage price change from
-- 2000-05-30 to most recent SPY date
select
cast((((select price
from [dbo].[ticker_date_price]
where
ticker = 'SPY' and
date = (
select max(date)
from [dbo].[ticker_date_price]
where ticker = 'SPY'))
/
(select price
from [dbo].[ticker_date_price]
where
ticker = 'SPY' and
date = (@start_date)))-1)*100 as decimal(6,2))
[SPY Overall Percentage Price Change]Following are the Result Sets
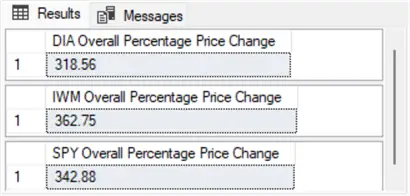
The following three result sets show that the IWM ticker has the largest percentage price change (362.75) and the DIA ticker has the smallest percentage price change (318.56). The point of showing the result sets is not to reveal which ticker has the largest or smallest percentage price change. Please look at the example to suggest an analysis framework for the types of analyses that can be performed with the data that you maintain and for which you have the responsibility of analyzing.
For example, you could be charged with reporting run times for some ETL jobs. In this case, you may want to track average run times for three or more jobs. If one of the jobs is consistently requiring longer times to complete, you can investigate sources for this, such as source files growing in size or the ETL application has been updated in ways that degrade performance.
Summary
This tip contrasts two ways of implementing bulk insert statements to import multiple CSV files to a SQL Server table. Review the code differences between the two approaches to find which one best matches your preferred coding style and how easy it is to follow how each code sample operates.
Those who learn best from hands-on experience should try adapting the code in this tip to the data with which they regularly work. For those with little or no prior experience using bulk insert statements, I recommend trying the static solution approach. The sample for this approach highlights how to successively import three CSV files to a SQL Server table where the file names do not change.
Advanced Developers
For more advanced developers who may have some prior experience with bulk insert statements, I recommend considering adapting the dynamic solution approach for importing multiple files to a single table. The file control table, dynamic SQL script, and while loop may make this approach more challenging to learn, but the dynamic solution approach is more flexible and easier to maintain – especially when the set of files to be imported changes in successive runs of the application. Additionally, as the number of files to be imported grows beyond a few, the more likely you will be able to benefit from the file control table and the dynamic SQL design elements of the dynamic solution approach.
Nice Extension
Finally, a nice extension to the dynamic solution approach would be to allow users to specify the name of the target table to be populated with multiple files. I actually evaluated some sample code for this feature, but I ultimately decided it would distract from the main points of the tip that pertain to bulk insert statements, file control tables, dynamic SQL, and while loops. If you want to see a follow-up tip that describes how to implement this feature, as well as one or two additional add-on capabilities, please leave a comment with your requests so I can consider demonstrating how to implement one or two of the add-on requests in future articles.
Next Steps
- Check out these related articles about Importing Data
