Problem
Efficient data management in Microsoft Fabric is a necessity in maintaining large-scale partitioned Delta tables. In dynamic datasets with frequently generated new files, the need to ensure the removal of stale files becomes very important to prevent storage bloating. In settings with partitioned tables, where data is in a hierarchical structure (e.g., by year, month, day), this can be particularly challenging, and files must be cleaned without disrupting active data. Learn how the VACUUM operation can help optimize delta tables.
Solution
The VACUUM operation is an important feature that helps in data management by ensuring the physical deletion of obsolete data files from its storage, resulting in optimized performance and minimized costs. In this article, I will describe how the VACUUM operation in Microsoft Fabric can effectively address these challenges, enabling data engineers to efficiently manage storage while preserving the integrity of partitioned Delta tables.
Understanding VACUUM in Delta Lake
The VACUUM operation helps to handle the physical deletion of deleted files once they are no longer referenced and have exceeded their retention period. By default, Delta retains removed files for seven days. You can customize this period based on business and compliance needs to optimize delta tables.
How VACUUM Identifies Stale Files
Delta Lake determines whether a file is “stale” based on the transaction log (_delta_log), which tracks all changes to the table. The Delta transaction log (_delta_log) is a directory within the Delta table that stores metadata about table operations.
Files are categorized as:
- Active Files: Represented as AddFile entries in the log. These files are currently part of the table, i.e., they are actively referenced by the table.
- Removed Files: Represented as RemoveFile entries in the log. These files have been logically deleted but remain in storage, i.e., files that have been deleted or overwritten but are retained for time travel and versioning purposes.
A file is considered ‘stale’ and eligible for deletion by VACUUM if:
- It is marked as a RemoveFile in the _delta_log.
- The retention period (default is seven days) has passed since its deletion was recorded in the transaction log.
For example:
- A file is overwritten on Day 0.
- It is marked as RemoveFile in the log on Day 0.
- VACUUM can delete the file physically on Day 7 (after the retention period).
Inspecting the Transaction Log
You can view the _delta_log to determine the reference status of files in several ways.
Using JSON Log Files. Navigate to the _delta_log folder of your Delta table. Each transaction is stored in JSON files. See the images below on how to navigate to it.

Once you click on View files, you should be able to see the “_delta_log” folder as seen in the image below.

Next, click on the “_delta_log” folder. You should be able to see all the JSON files, as seen in the image below.

Open a JSON File for Inspection
Next, open any of the JSON files and inspect them to view operations as seen in the two images below.
For the first JSON files with all zeros (00000000000000000000.json), you could find some other information like commitIfo, metadata, and protocol sections. I won’t be talking much about these; I will only be discussing the “AddFile” entry section and “RemoveFile” entry section for this article.
The “AddFile” entry section can be seen in the image below. It is important to note that the 00000000000000000000.json file being the first file created in the delta table does not have a “RemoveFile” section as it’s purely referenced by the Delta table and no files have been removed or replaced at this stage. It reflects the data structure and partitioning applied during the initial writing.

Once the 00000000000000000000.json file is overwritten by a new file (00000000000000000001.json), the new file will contain “removeFile” sections (usually towards the bottom of the JSON file), as seen in the image below. It will appear in subsequent versions of the Delta log when files are replaced or deleted.

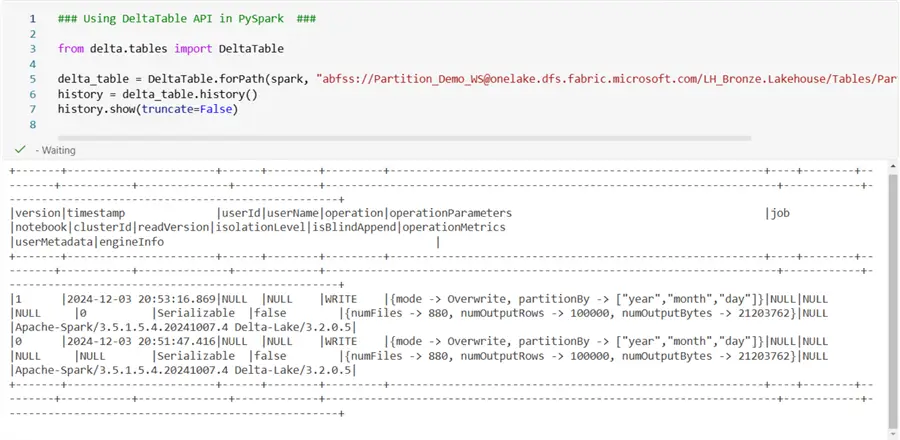
Using DeltaTable API in PySpark. This API allows you to view the table’s history, including details about added and removed files. This can be implemented using the code below.
### Using DeltaTable API in PySpark ###
from delta.tables import DeltaTable
delta_table=DeltaTable.forPath(spark, "abfss://Partition_Demo_WS@onelake.dfs.fabric.microsoft.com/LH_Bronze.Lakehouse/Tables/Partitioned_Delta_Table")
history = delta_table.history()
history.show(truncate=False)The output of the PySpark code above is seen in the image below.
Applying VACUUM to Partitioned Tables
In Microsoft Fabric, you can run a routine VACUUM operation to maintain your Delta tables using the Fabric UI as documented in this Microsoft Documentation. However, it can be challenging to remember to run these operations each month, thus it might be wise to automate the process. I will explain how the automation can be achieved via code later in this section.
Let’s look at a scenario where a table is partitioned by year, month, and day, with new files written daily. To manage storage, you want to retain only the last 14 days of files. You will only need to follow the steps in the images below to run a VACUUM operation on your table based on your retention policy of 14 days.
Click on the ellipses (…) at the end of your Delta table. Then select Maintenance and a new window will pop-up.

In the new window that opens, check the Run VACUUM command using retention threshold box, select your retention threshold accordingly, and click Run now. See the image below.

When you run VACUUM, it scans the transaction log for files marked as RemoveFile and checks their retention eligibility. If a file within a specific partition is stale, it is deleted from storage. For a file to qualify as stale, the following criteria must be met:
- They are listed in a RemoveFile entry.
- The deletionTimestamp in the log exceeds the retention period (e.g., 14 days or 336 hours).
- No active version of the table references them.
How to Verify Stale Files
It is possible to verify stale files in your Delta table by loading the metadata of the Delta table using PySpark code as follows:
### Verify Stale Files by Loading Metadata of Delta Tables ###
from delta.tables import DeltaTable
# Loading the Delta table
delta_table=DeltaTable.forPath(spark, "abfss://Partition_Demo_WS@onelake.dfs.fabric.microsoft.com/LH_Bronze.Lakehouse/Tables/Partitioned_Delta_Table")
# Get the details of removed files
removed_files = delta_table.history().select("operation","operationMetrics", "timestamp").filter("operation = 'REMOVE'")
removed_files.show(truncate=False)The code above retrieves and shows the history of a Delta table operation, specifically focusing on operations where files were removed. It does this by using the history() method of the Delta table, filtering for REMOVE operations, and then selecting the relevant fields: operation, operationMetrics, and timestamp.
The output of this code is as seen in the image below. Note that it was currently empty when I ran it. This might be due to one of the three reasons listed below. In a nutshell, it means that the “Remove” operation history has no matching entries at the time the command was run. There could be several reasons for this:
- No Removal Operations: There might not have been any REMOVE operations on the Delta table. This could happen if the VACUUM process has not yet been triggered or if the table hasn’t undergone any deletion activities.
- No File Deletions: The data might not have been removed (i.e., the Delta table is not pruning any older files). For instance, if the VACUUM process hasn’t been executed or identified any “stale” files that need deleting, the output would be empty.
- Timeframe of Log: The history view in Delta Lake is bounded by the history function, which captures operations within the configured log retention period. If the removals happened beyond this retention period, they may not appear in the output.

To explain the output,
- operation: This field indicates the type of operation that was performed. In this case, it filters for operations where the value is REMOVE, meaning these operations correspond to file deletions.
- operationMetrics: This field contains performance metrics related to the REMOVE operation, such as the number of files removed or the number of rows affected. If no metrics were available or recorded for the REMOVE operation, this might be null or empty.
- timestamp: The timestamp of the operation when the file removal occurred.
Some Challenges and Troubleshooting of VACUUM
If VACUUM does not delete stale files, consider these points:
- Retention Period Not Elapsed: Ensure the retention period specified in VACUUM has passed since the files were marked as removed.
- Files Not Marked for Removal: If a file was not correctly marked as RemoveFile in the transaction log, VACUUM won’t delete it. You can manually identify and remove orphaned files.
- Active References: A file still referenced in the Delta log as AddFile will not be deleted.
Identifying and Managing Orphaned Files
Those files that are present in the storage system, but not referenced in the Delta transaction log, are the ones referred to as Orphaned files. Orphaned files also relate to those files that were not properly cleaned up by previous operations (for example, VACUUM operations), as well as those files that are no longer referenced due to schema changes, data overwrites, data deletions, in the Delta transaction log.
Common scenarios that lead to orphaned files may include:
- Failed Deletes: This is where unreferenced files are left behind due to any interruption or misconfiguring of the VACUUM.
- Improper Partition Management: This is when old files are not cleaned up properly when partitions are updated or replaced.
- Manual Interventions: This results when there is a Manual copying or deletion of files beyond the control of the Delta table.
You can retrieve the list of active files from the Delta transaction log and compare it with the physical files in storage to isolate Orphaned files. To do this, perform the following steps.
Step 1: Get the list of all referenced files using PySpark as seen in the code below.
### List of all Referenced Active files from the Delta transaction log ###
from delta.tables import DeltaTable
from pyspark.sql.functions import input_file_name
# Loading the Delta table
delta_table = DeltaTable.forPath(spark, "abfss://Partition_Demo_WS@onelake.dfs.fabric.microsoft.com/LH_Bronze.Lakehouse/Tables/Partitioned_Delta_Table")
# Getting active files referenced in the Delta log
active_files = (
spark.read.format("delta").option("versionAsOf", delta_table.history().agg({"version": "max"}).collect()[0][0])
.load("abfss://Partition_Demo_WS@onelake.dfs.fabric.microsoft.com/LH_Bronze.Lakehouse/Tables/Partitioned_Delta_Table")
.select(input_file_name())
.distinct()
.collect()
)
# Extract the file paths
active_file_paths = [row[0] for row in active_files]
print("Active File Paths:", active_file_paths) The output of the above code should look like the image below.

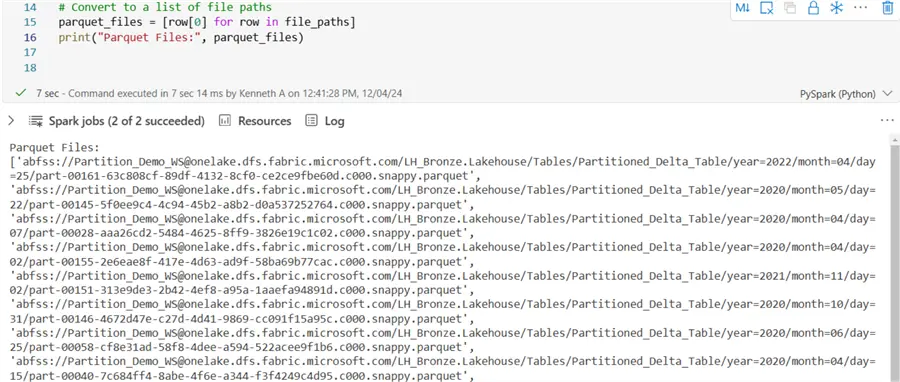
Step 2: List all physical files in your storage system for the table’s directory using PySpark, as seen in the code below.
### List of all Physical Files in Folder ###
from pyspark.sql.functions import input_file_name
# Loading the Delta table
delta_table_path = "abfss://Partition_Demo_WS@onelake.dfs.fabric.microsoft.com/LH_Bronze.Lakehouse/Tables/Partitioned_Delta_Table"
# Reading the Delta table
df = spark.read.format("delta").load(delta_table_path)
# Extract the file paths
file_paths = df.select(input_file_name()).distinct().collect()
# Convert to a list of file paths
parquet_files = [row[0] for row in file_paths]
print("Parquet Files:", parquet_files) The output of the code above should look like the image below.
Step 3: Find orphaned files by comparing the two lists. The PySpark code below can help to achieve that.
### Finding Orphaned Files by Comparing the two Lists ###
orphaned_files = set(parquet_files) - set(active_file_paths)
print(f"Orphaned files: {orphaned_files}") If the output of the above code shows as Orphaned files: set() :, this indicates that all physical files are active and referenced in the Delta log.
If the output shows as Orphaned files: {'path/to/unreferenced_file1.parquet','path/to/unreferenced_file2.parquet'} :, this means there are files in storage that are no longer used by the Delta table and should be cleaned up.
Preventing Future Issues with Orphaned Files
To avoid orphaned files in the future, do one or a combination of the following.
- Use Delta Commands for Data Management: When modifying data, always use Delta commands like OVERWRITE, MERGE, or DELETE. Do not directly delete files from the storage system without updating the Delta transaction log.
- Run VACUUM Regularly: To clean up VACUUM operations on a regular basis, you may need to schedule the process.
- Validate Transactions: To ensure that transactions are properly recorded, you may need to monitor the _delta_log transactions.
Best Practices for Using VACUUM
- Set an appropriate retention period to balance between storage cost and the need for time travel or rollback.
- Schedule regular maintenance by automating VACUUM as part of your data pipeline to keep storage optimized.
- Use partitioning wisely by partitioning data by high-cardinality fields like date or region to enable efficient file pruning and reduce stale data.
- Validate transaction logs by periodically inspecting _delta_log to ensure files are correctly tracked.
- Avoid manual file deletions by always managing data through Delta Lake operations (e.g., MERGE, DELETE, OVERWRITE). Directly deleting files may lead to inconsistencies or orphaned files.
- To ensure data accuracy and completeness, before running VACUUM, confirm no active queries or downstream processes depending on old files.
Automating the Run of VACUUM Command
As mentioned earlier, it might be good practice to automate the run of VACUUM for Delta table maintenance. This, however, depends on your environment and how your architecture is planned.
To automate the process, you simply need to write a PySpark code that will run the VACUUM command leveraging the delta.tables module in the Delta Lake library that provides tools to manage Delta tables programmatically.
### Programmatically run Vacuum command automatically for single table ###
from delta.tables import DeltaTable
# Define the table name
table_name = "partitioned_delta_table"
try:
# Accessing the Delta table
delta_table = DeltaTable.forName(spark, table_name)
# Perform VACUUM with a retention period of 14 days (336 hours)
print(f"Vacuuming table: {table_name} with a retention period of 14 days.")
delta_table.vacuum(retentionHours=336)
print(f"Vacuum operation completed for table: {table_name}\n")
except Exception as e:
print(f"Error processing table {table_name}: {str(e)}") When you run the above script, it will VACUUM only the table “partitioned_delta_table” with the specified retention policy. This approach avoids unnecessary complexity and focuses solely on the targeted table.
If you need this process to run for multiple tables at same time, you need to list all tables in the code and leverage a loop in the code, as seen in the script below.
### Programmatically run Vacuum command automatically for multiple tables ###
from delta.tables import DeltaTable
# Defining the table names
tables = [
"partitioned_delta_table",
"Partitioned_table_ByCountry"
]
# Perform Vacuum for each table
for table_name in tables:
try:
# Accessing the Delta table
delta_table = DeltaTable.forName(spark, table_name)
# Perform VACUUM with a retention period of 14 days (336 hours)
print(f"Vacuuming table: {table_name} with a retention period of 14 days.")
delta_table.vacuum(retentionHours=336)
print(f"Vacuum operation completed for table: {table_name}\n")
except Exception as e:
print(f"Error processing table {table_name}: {str(e)}") After writing and testing your code, you need to leverage Fabric Pipelines to schedule the notebook to run on a periodic basis (daily, weekly, etc).
Considerations
- Retention Period: The default retention period is seven days to protect against accidental deletion.
- Time Travel: VACUUM operations will remove files that are required for querying old table versions that exceed the retention period.
- Concurrency: To avoid conflicts during the VACUUM operations, ensure no concurrent writes or updates to the table(s).
- File-Level Operation: VACUUM operations operate at the file level. It doesn’t specifically affect the partitions but it naturally affects partitions containing obsolete data. Thus, the operation cleans up old data files that are no longer referenced by the Delta table’s metadata.
- Awareness of Partitions: A VACUUM operation will clean up any unreferenced files from partitions if you overwrite or drop specific partitions in a Delta table. Where a dynamic partitioning is used during data writes, the VACUUM operation also ensures that existing unneeded files are also cleaned across dynamically created partitions.
- Retention Rules: The retentionHours parameter is respected by the VACUUM operation; it only removes files that are older than the specified retention threshold. Where a partition is recently updated, nothing will happen to the files until the retention period is satisfied.
- Table-Level Execution: The VACUUM command can only execute at a table level. Where a table is partitioned, the command scans all the partitions and then removes any obsolete files. The VACUUM operation can be resource intensive in setups with large, partitioned tables.
Summary
In summary, I have described in this tip how the VACUUM operation can be an essential tool for the data management lifecycle in Microsoft Fabric. It can be very useful when there is a need for storage efficiency by cleaning up stale files while maintaining the integrity of Delta Lake’s powerful features like time travel. By understanding how VACUUM operation works, implementing best practices, and troubleshooting common issues, one can optimize data operations and maintain a cost-effective, high-performing data environment.
Next Steps
- Check out this efficient way to create partitioned delta tables in MS Fabric.
- Learn more about Microsoft Fabric: Use table maintenance feature to manage delta tables in Fabric.
- Read more about Delta Lake best practices: Best practices: Delta Lake.
- You can read more about data engineering in Microsoft Fabric: What is Data engineering in Microsoft Fabric?.
- See this step-by-step guide on setting up and querying data in Delta tables: Tutorial: Delta Lake.
