Problem
I heard that Microsoft is including Regex functions with the release of SQL Server 2025. Where can I get a quick refresher on Regex? What are the new SQL regex functions and what can they do?
Solution
If you are like me, Regex is one of those long-standing technologies/tools that I never quite learn enough about. You may be surprised that Regex, which stands for regular expression, actually surfaced in the 1950s during the timeframe of the development of many modern computers (Regular expression – Wikipedia). Of course, like many core tools, it has grown over the past 70 years with expanded functionality and usage.
Its usage in SQL Server has been limited to going outside of SQL Server to execute its functionality via an external service, such as using CLR procedures. Fortunately, in 2024, Microsoft finally started adding direct support, first in Azure SQL databases, and now such functionality is available in SQL Server 2025. Finally, several Regex-based functions are available for use in SQL Server and will be covered in this tip. The implementation library used by SQL Server is sourced from the RE2 library (RE2 Regular Expression Syntax).
Using Regex
Before using the Regex in SQL, let’s review some of the basic syntax expressions. Regex includes the concepts of character sets, character ranges, escape characters, character qualifiers, etc.
| RegEx Concepts | Search Patterns |
| Any single character | . |
| Any single character equal to x, y, z | [xyz] |
| Any single character not equal to x, y, z | [^xyz] |
| Any characters in range | [A-Z] |
| Any character in class | \d |
| Repetition of characters | \d{11} or \d{*} |
Any single character not equal to x, y, z [^xyz] Any characters in range [A-Z] Any character in class \d Repetition of characters \d{11} or \d{*}
The above items are just a few of the common search patterns in Regex tools.
SQL Server Regex Functions
We will take a look at these regex functions that are now part of SQL Server.
- REGEXP_COUNT
- REGEXP_INSTR
- REGEXP_LIKE
- REGEXP_REPLACE
- REGEXP_SUBSTR
- REGEXP_MATCH
- REGEXP_SPLIT_TO_TABLE
REGEXP_COUNT
The first function we will review is REGEXP_COUNT. As implied by the name, this particular function returns a count of the number of times the noted pattern appears. The returned value from the function is an integer. Additionally, the function accepts four arguments:
- String to evaluate
- Regex pattern
- Start position to begin evaluating
- Flags
This only works for data types char, nchar, varchar, and nvarchar for the string to evaluate. The start position is 1 based, so it must be greater than 1.
Finally, the function accepts four supported flags:
- i – case insensitive – True or False (default)
- m – multi-line mode – True or False (default) – determines if pattern restarts with each new line
- s – let . match \n — True or False (default)
- c – case sensitive – True or False (default)
Of course, flag i and flag c are mutually exclusive; however, if both are specified, then the last flag is used.
Now all the technicalities are out of the way, let’s run some query examples.
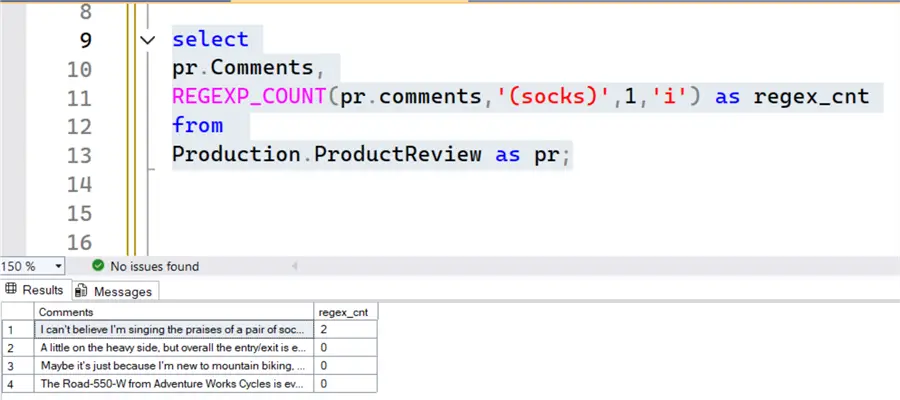
Example. The first query shown below uses the AdventureWorks Data Warehouse DB and specifically queries the Production.ProductReview table, which has a comments field. The below query uses the regexp_count function to determine the number of times the characters ‘socks’ appear in the comment text.
select
pr.Comments,
REGEXP_COUNT(pr.comments,'(socks)',1,'i') as regex_cnt
from
Production.ProductReview as pr;As shown below, we can see that in the four rows in the table, the first row contains ‘socks’ and specifically has two instances of the word socks. The remaining rows do not contain socks.
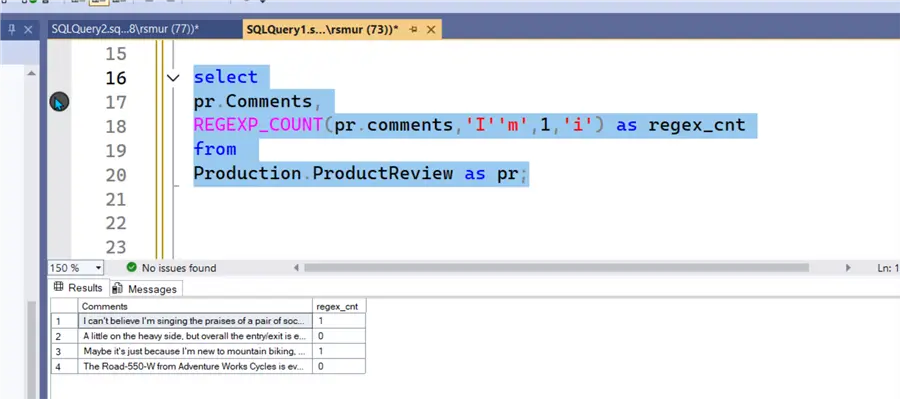
The query could easily be adjusted to reference a different character pattern; in the below example, that pattern was changed to ‘I’m’. The results show that two rows contain this pattern.
REGEXP_INSTR
The second function for our review is the REGEXP_INSTR function. This function returns the starting or ending position of the pattern. This function accepts six arguments:
- String to evaluate
- Regex pattern
- Start position to begin evaluating
- Occurrence, which is the occurrence of the pattern in the string
- Return option, with 0 being the start position and 1 being the end position
- Flags
Example. For this function, the additional arguments request more details to be specified for the search pattern.
select
pr.Comments,
REGEXP_instr(pr.comments,'(socks)',1,1,0,'i') as regex_start,
REGEXP_instr(pr.comments,'(socks)',1,1,1,'i') as regex_end,
REGEXP_instr(pr.comments,'(socks)',1,2,0,'i') as regex_start_2,
REGEXP_instr(pr.comments,'(socks)',1,2,1,'i') as regex_end_2
from
Production.ProductReview as pr;The results show the query searches for the first and then the second occurrence of the pattern ‘socks’. The results return both the starting and ending position of the value pattern.

REGEXP_LIKE
The third function for our review is the REGEXP_LIKE function. This function returns True or False based on whether the pattern is found in the input string. This function accepts three arguments:
- String to evaluate
- Regex pattern
- Flags
Example. Since this function returns a Boolean, it is often used in the where clause.
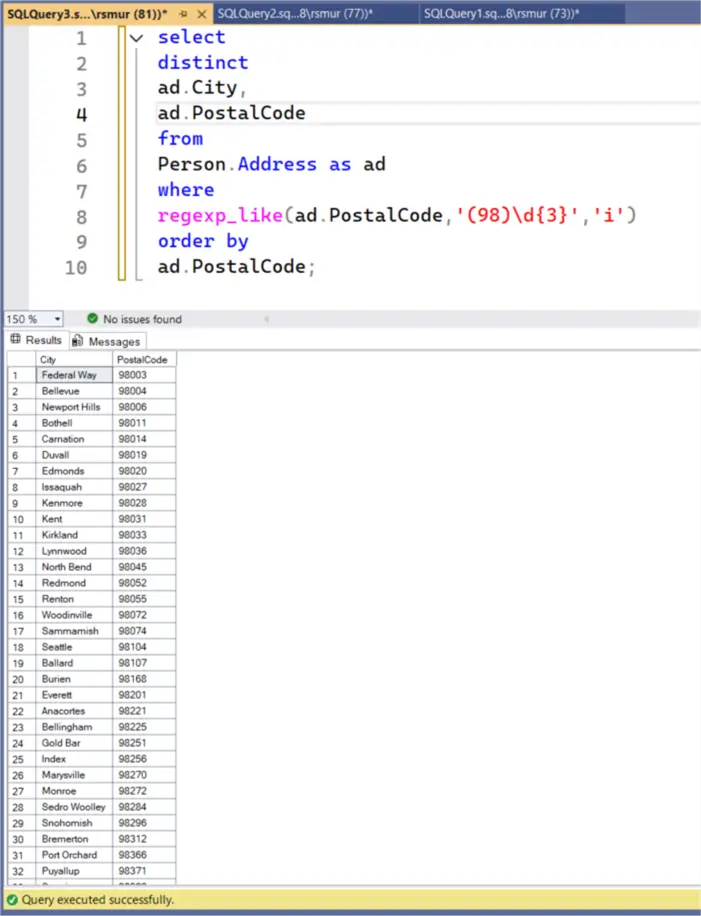
select
distinct
ad.City,
ad.PostalCode
from
Person.Address as ad
where
regexp_like(ad.PostalCode,'(98)\d{3}','i')
order by
ad.PostalCode;This query searches in the PostalCode field for the pattern of ‘98’ followed by three numeric characters. If the search were only ‘98’, the 98 could appear anywhere in the string.
The screenshot below shows the results of finding all the matching postal codes; notice that the where clause assumes that True is the desired result.
The query could be adjusted to return every row where the pattern does not match by adding “not” before the regexp_like, as displayed in the following screenshot.

REGEXP_REPLACE
Moving on to the fourth function, REGEXP_REPLACE, this function replaces the pattern string with a new set of text. This function accepts six arguments:
- String to evaluate
- Regex pattern
- String to replace with the noted pattern
- Start position to begin evaluating
- Occurrence, which is the occurrence of the pattern in the string
- Flags
For the string replacement value, this function allows for the use of \n (where n equals positions 1 to 9) to reuse the value that is being replaced.
Example. In this example, the pattern matches a 4-digit numeric value three times and then a 2-digit numeric value one time. So, the function could use \1, \2, \3 as replacements for patterns found. The example shows a 14-character credit card number, where the first 12 characters are visible with the addition of two Xs for the last two positions. Also, a dash (-) is added between every 4th position.
select
cc.CardType,
cc.CardNumber,
regexp_replace(cc.CardNumber,'(\d{4})(\d{4})(\d{4})(\d{2})','\1-\2-\3-XX') as CardNumber_Format
from
Sales.CreditCard as cc;In the screenshot below, the original and the replacement card numbers are shown.

REGEXP_SUBSTR
The REGEXP_SUBSTR function returns the characters in the matching pattern. This function accepts six arguments:
- String to evaluate
- Regex pattern
- Start position to begin evaluating
- Occurrence, which is the occurrence of the pattern in the string
- Flags
- Group, which is a fragment of the pattern to return
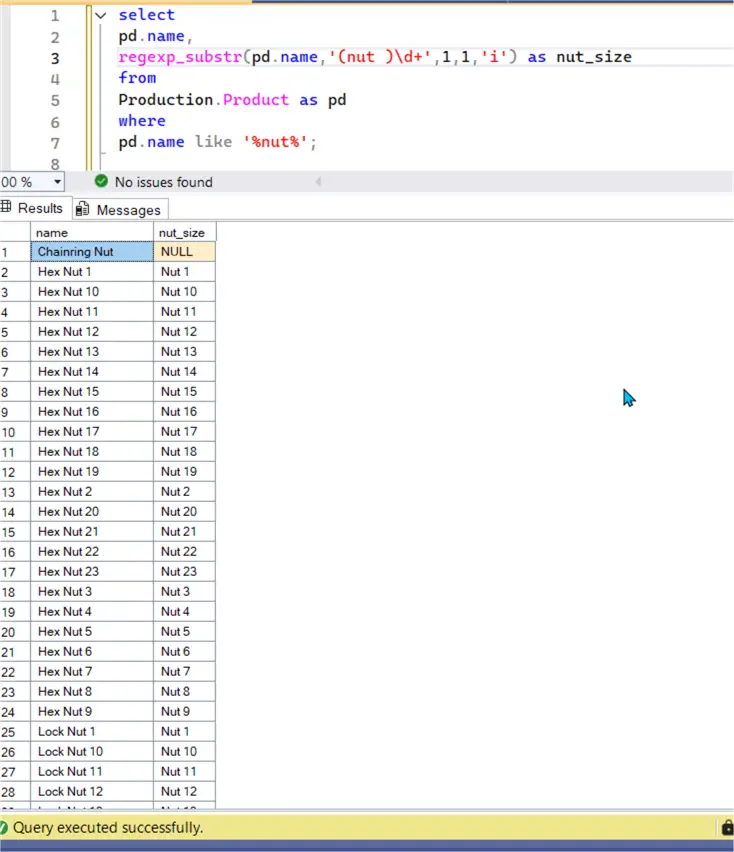
Example. As shown in the code below, we are looking for a pattern that contains ‘nut‘ plus any number of numeric values.
select
pd.name,
regexp_substr(pd.name,'(nut )\d+',1,1,'i') as nut_size
from
Production.Product as pd
where
pd.name like '%nut%';Below, the results show the pattern plus the digits after the word, which indicates the nut size.
To further this example, the below query adds the group argument (last item in function, 2), which notates the part of the pattern that the substring function should return. In this query, the group is noted as 2 or the second part of the pattern, which is the (\d+).
select
pd.name,
regexp_substr(pd.name,'(nut )(\d+)',1,1,'i',2) as nut_size
from
Production.Product as pd
where
pd.name like '%nut%';Now, the results show just the actual numeric nut size.

REGEXP_MATCH
The next function for this review is REGEXP_MATCH. This function returns a table that includes a match id, the starting and ending positions of the matched pattern, the text of the matched pattern, and a JSON text of the starting and ending positions of the matched pattern. There are three arguments for this function:
- String to evaluate
- Regex pattern
- Flags
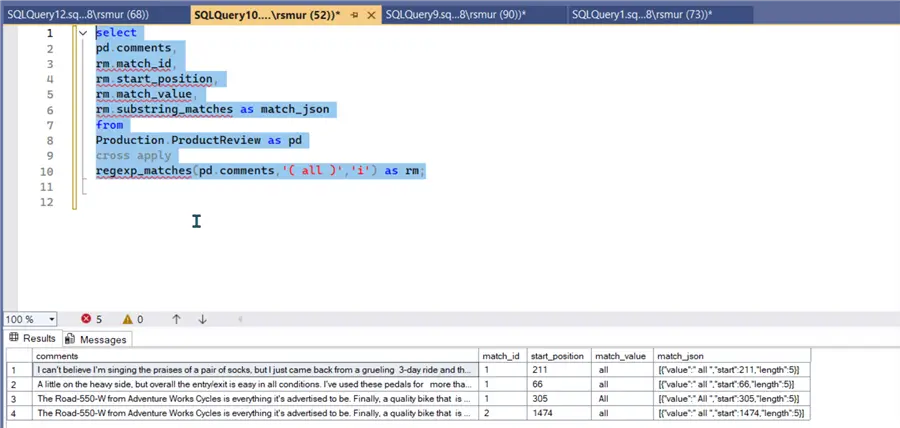
Example. Although this function has fewer arguments, you must note that it is a table-valued function, which means that you will need to execute it in the “from” clause as a table is returned. In this example, the function is cross applied against the comments field in the ProductReview table.
select
pd.comments,
rm.match_id,
rm.start_position,
rm.match_value,
rm.substring_matches as match_json
from
Production.ProductReview as pd
cross apply
regexp_matches(pd.comments,'( all )','i') as rm;The results below show that the pattern search for ‘all‘ is found four times over three rows of data. Notice in the last two rows how the match_id increments because the pattern is found twice in the same row.
REGEXP_SPLIT_TO_TABLE
The last function for this tip is REGEXP_SPLIT_TO_TABLE. This function is also a table-valued function that splits the text based on the Regex pattern delimiter. In its simplest form, this function provides an easy method to split phrases or sentences into individual words. This split could then be used as input or sources for future matching and data science techniques. There are three arguments for this function:
- String to evaluate
- Regex pattern
- Flags
Example. Again, since this is a table-valued function, the cross apply is used to join the ProductReview table with the results from the function evaluating the comments field. In the below example, the \s+ character class pattern is used to look for any whitespace character.
select
pd.comments,
rm.value,
rm.ordinal
from
Production.ProductReview as pd
cross apply
regexp_split_to_table(pd.comments,'\s+','i') as rm;The result is a quick way to extract each of the words in a long phase or paragraph; from these results. I could easily see sentiment analysis examples that could be applied.

Overall Limitations
A set of limitations on the current Regex functions:
- The functions cannot be executed against varchar(max) or nvarchar(max) fields greater than 2MB.
- If memory-optimized tables are used, Regex functions cannot be executed against such tables.
- Many of the functions are only available for SQL Server 2025.
Summary
In this tip, the new SQL Regex functions available in SQL Server 2025 were covered in detail. These functions allow the use of Regex text patterns to search for and even replace values in character-type fields.
Next Steps
- In this tip, Basic Regex Emulator for SQL Server, Sebastiaso Pereira, gives a quick preview of the SQL Server Regex functions, but more importantly, he outlines the process of creating CLR procedures to complete the aforementioned functions that were not available yet. This tip, SQL Server Regex CLR Function, by Ian Foglman, also outlines the detailed and complicated CLR procedure process needed to execute regex functions in SQL Server, prior to SQL Server 2025.
- Using REGEX in Python – Python Regex Explained with Examples
- SQL, Python, and Regex – SQL Server RegEx Capabilities Using Python
