By: John Miner | Comments | Related: > Functions System
Problem
How do you split a string that is delimited by a character into columns? In the past, database professionals have used number tables, tally tables, common table expressions (CTE), XML functions, CLR functions and brute force iterations to accomplish this task. In this tip we will look at the new function in SQL Server 2016.
Solution
In this tip we look at a real world business problem of importing data that is not formatted in a way that is easy to import. We will look at how we can use the new STRING_SPLIT() to simplify parts of the process.
Microsoft SQL Server 2016 was released to manufacturing on June 1st. Please see this SQL Server Team BLOG for the full details. This product release contains a new function called STRING_SPLIT() that solves this business problem. The MSDN entry has full details on the function. Microsoft has adopted a cloud first release strategy. It is not surprising that this function is already available for Azure SQL Database.
Business Problem
For this example we will be using Azure, but this new function works in all versions of SQL Server 2016.
This article assumes you know how to create a Azure SQL Server and Azure SQL Database. If you are not familiar with these tasks, please see my earlier article on Azure Table Partitioning that goes over these basic steps.
Parsing web server logs for click stream information has been a common chore for data professionals. A quick search of the internet resulted in a web server LOG FILE from NASA's Kennedy Space Center. This log file has all visitor traffic for July, 1995. This file should be a good test case since it has over one million entries.
Our task is to parse the information from the file into a Azure SQL Database
using just tools that come with SQL Server Management Studio download.
Azure Objects
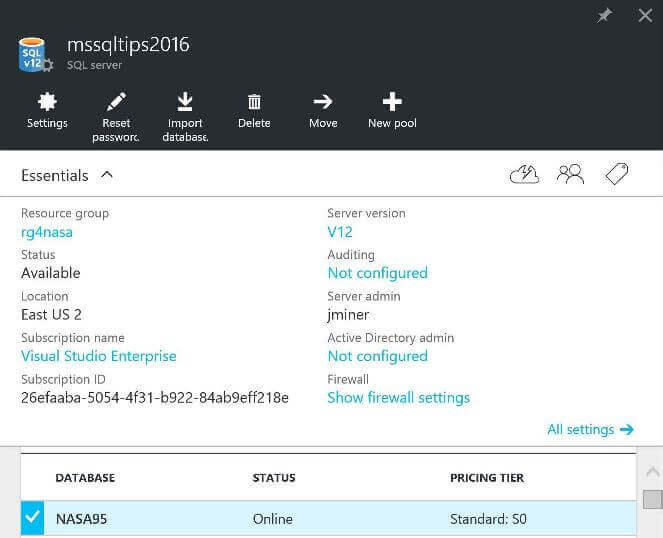
Our first task is to create a Azure SQL Server using my Visual Studio Enterprise subscription. The server is named mssqltips2016 and the administrator login name is jminer.
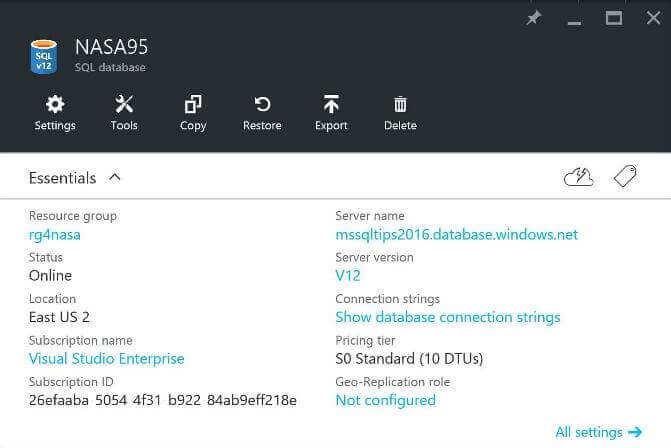
Our second task is to create a Azure SQL database named NASA95. This database resides in a resource group called rg4nasa that is located in the US EAST 2 data center. I choose the SO Standard as the database size. This gives use 10 database transaction units to perform data processing.
Simple Test Program
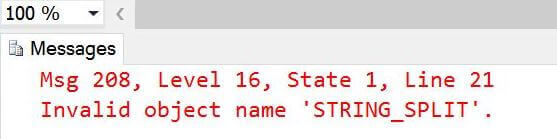
The first example use of the STRING_SPLIT() function fails since Azure SQL databases have a default compatibility level of 120 or SQL Server 2014. We need to change the level to 130 or SQL Server 2016 to use this new function. Executing a simple ALTER DATABASE statement fixes this issue.
The code below shows how to split the string containing the names of the three stooges into three columns. There are no side effects with this function. Empty columns or leading spaces or trailing spaces are not effected by calling this TABLE VALUE FUNCTION. Adding TRIM functions and a WHERE clause can eliminate these unwanted conditions.
-- -- Must be using 2016 compatibility level --
ALTER DATABASE [NASA95] SET COMPATIBILITY_LEVEL = 130 GO
-- -- Simple example using three stooges --
SELECT * FROM STRING_SPLIT('Curly Moe Larry', ' '); GO
-- -- No side effects --
SELECT * FROM STRING_SPLIT('Curly, , Moe, , Larry, ', ','); GO
-- -- Toss blank columns, remove leading & trailing spaces --
SELECT RTRIM(LTRIM(value)) as pretty_print FROM STRING_SPLIT('Curly, , Moe, , Larry, ', ',') WHERE value <> '' GO
The output from the above sample code is shown below.

Data File Preparation
The data file from NASA is in a GZIP format since it was generated on a UNIX system. The 7-zip desktop program can be used to uncompress the file. The resulting text file is ten times bigger than the compressed one. Please see image below for file details.

The actual format of the text file has to be changed before processing. UNIX files only have line feeds while WINDOWS files have line feeds (LF) and carriage returns (CR). For more details, look at the newline article on Wikipedia. The notepad++ desktop program can be used to convert easily back and forth between formats.
Now that we have our data file correctly uncompressed and formatted for loading, we can concentrate on designing a load process to transform the data into a nicely organized table.
Database Schema Design
I am going to create two schemas for the import process. The STAGE schema is used to store intermediate results and the ACTIVE schema is used to hold the final cleansed data.
-- -- Create STAGE schema --
-- Delete existing schema. IF EXISTS (SELECT * FROM sys.schemas WHERE name = N'STAGE') DROP SCHEMA [STAGE] GO
-- Add new schema. CREATE SCHEMA [STAGE] AUTHORIZATION [dbo] GO
-- -- Create ACTIVE schema --
-- Delete existing schema. IF EXISTS (SELECT * FROM sys.schemas WHERE name = N'ACTIVE') DROP SCHEMA [ACTIVE] GO
-- Add new schema. CREATE SCHEMA [ACTIVE] AUTHORIZATION [dbo] GO
Since the business problem stated that we need to use tools only included with the SQL Server Management Studio download, I am going to use the Bulk Copy Program (BCP) to load the raw data into a table named WEBLOGS. Each line of data will result in one row in this table.
The COLVALS table is where all the manipulation is going to occur. Each data row is going to be split into columns. Any transformations or cleanup will be performed in this table. The code below creates these two tables in the STAGE schema.
-- -- Create STAGE tables --
-- Delete existing table IF EXISTS ( SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[STAGE].[WEBLOGS]') AND type in (N'U')) DROP TABLE [STAGE].[WEBLOGS] GO
-- Create new table CREATE TABLE [STAGE].[WEBLOGS] ( DATA VARCHAR(MAX) );
-- Delete existing table IF EXISTS ( SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[STAGE].[COLVALS]') AND type in (N'U')) DROP TABLE [STAGE].[COLVALS] GO
-- Create new table CREATE TABLE [STAGE].[COLVALS] ( ROWID INT, COLID INT, VALUE VARCHAR(1024) );
The nice thing about having different schemas is that I can create the final table also named WEBLOGS in the ACTIVE schema. Thus, we have two tables with the same name, but contain information at different points of processing.
-- -- Create ACTIVE tables --
-- Delete existing table IF EXISTS ( SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[ACTIVE].[WEBLOGS]') AND type in (N'U')) DROP TABLE [ACTIVE].[WEBLOGS] GO
-- Create new table CREATE TABLE [ACTIVE].[WEBLOGS] ( WEB_LINE INT IDENTITY(1,1) NOT NULL CONSTRAINT PK_LINE_ID PRIMARY KEY, WEB_HOST VARCHAR(512) NULL, WEB_PART VARCHAR(512) NULL, WEB_DATE DATETIMEOFFSET(4) NULL, WEB_TYPE CHAR(1) NULL, WEB_RESULT INT NULL, WEB_BYTES INT NULL );
Loading Staging Table
I copied the NASA log file to the temporary directory named on the C drive and renamed it to make the command line invocation of BCP easier to read. The fully qualified Azure SQL Server and Azure SQL Database names are input parameters. The command line invocation of assumes that each line is terminated by a carriage return and each field is delimited by a tilde. I choose the tilde as a row delimiter since I knew there were no character matches in the input file.
Please see MSDN for the calling syntax of the BCP utility.
BCP NASA95.STAGE.WEBLOGS IN "C:\TEMP\WEBLOG.TXT"
-S mssqltips2016.database.windows.net -U JMINER -P SQLtip$2016 -t~ -r \n -m 1 -c
Since we did not set the batch commit size, it defaults to every 1000 records. We can see over 1 million records were loaded in 847 seconds. That is just over 14 minutes which is pretty good.
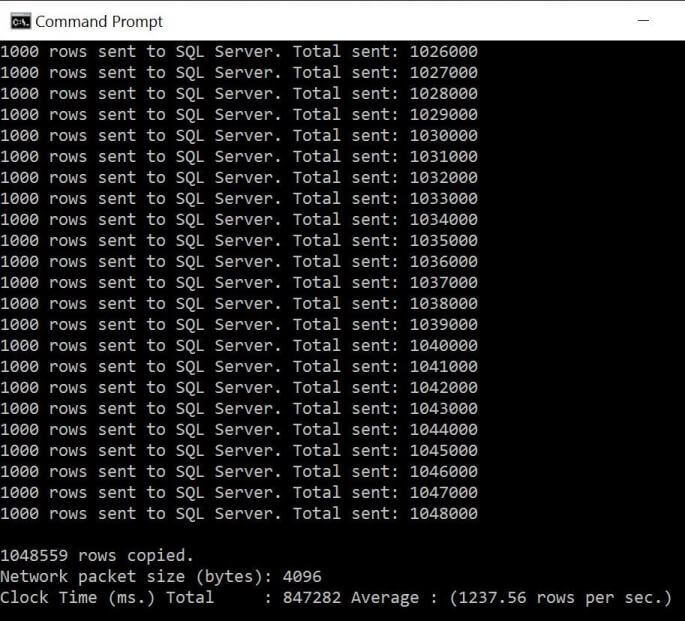
Most processes in the real world are limited by some type of bottle neck. This extract, transform and load process is no different. Using the resource utilization monitor, I noticed that the Database Transaction Units (DTU) are at 100%. Thus, the total time of this process can be reduced by increasing the database size.
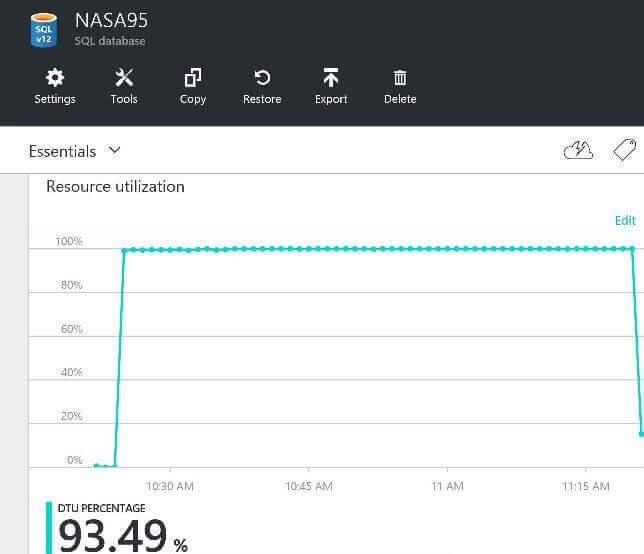
The best feature of cloud services is the ability to scale up or down resources when needed. As long as you are willing to pay some more money, we can change the database size to go faster. I decided to retry the same BCP load process using a S3 Standard size which has 10 times the processing.
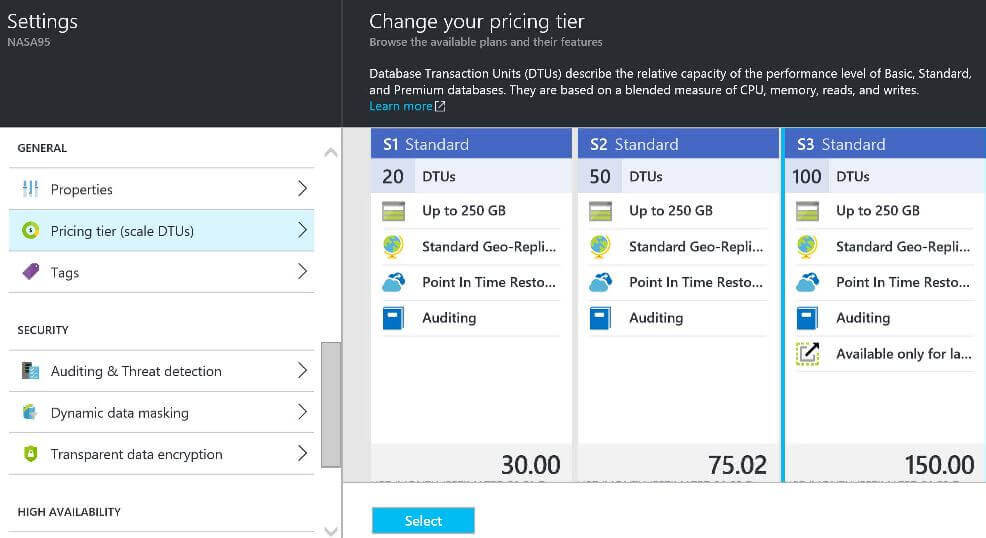
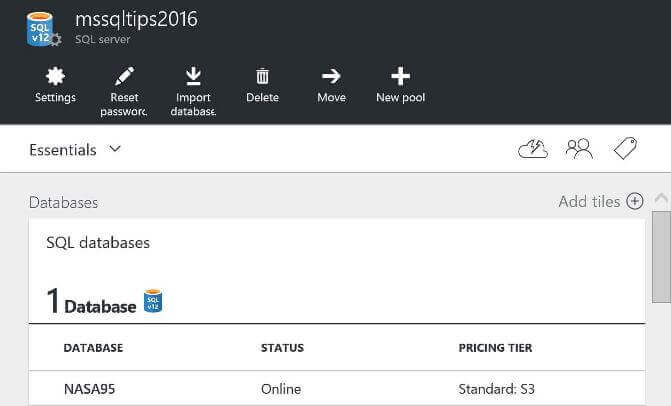
Depending upon what is changed, the requested action can take a couple minutes. Keep an eye on the notifications on the Azure Dashboard which will signal the completion of the request. Like most changes, it is always prudent to check the results of your action. The image below shows the new database size.
Again, we execute the above BCP execution from the command line. We can see over 1 million records were loaded in 317 seconds. That is just over 5 minutes which is awesome. Thus, we reduced the total time to load from file to staging table by 62.5%.
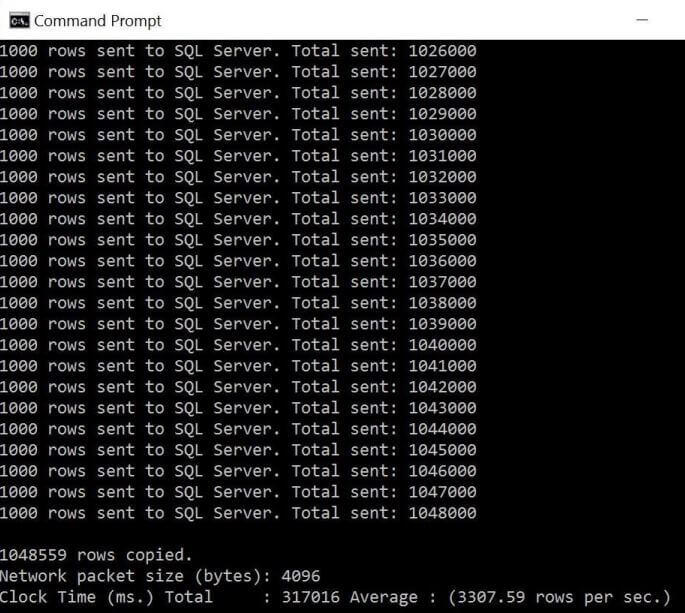
Transforming Row Data
It is usually a good idea to test your T-SQL code with a large data set that represents many different combinations. I did notice that some fields contain one or more spaces. In reality, we only want one space between characters in our data.
Jeff Moden, who is a Microsoft Data Platform MVP, publish a combinatorics technique to remove spaces using replacement patterns. Please see this blog entry for the details. I leverage this technique in the complex CTE which translates the input data into columns.
The following algorithm is used by the CTE to move data from the STAGE.WEBLOGS table to the STAGE.COLVALS table.
- Replace one or more spaces with a single space.
- Add dividers (delimiters) for column breaks.
- Add row id to final data string.
- Split the data string on delimiters and create column ids.
- Store the results in the COLVALS table.
-- -- Split data into columns --
-- Remove extra spaces WITH CTE_REMOVE_EXTRA_SPACES AS ( SELECT LTRIM(RTRIM(REPLACE(REPLACE(REPLACE(DATA,' ',' þ'),'þ ',''),'þ',''))) AS DATA FROM [STAGE].[WEBLOGS] AS W ),
-- Add dividers CTE_PLACE_DATA_DIVIDERS AS ( SELECT REPLACE(REPLACE(REPLACE(DATA, ' - - [', 'þ'), '] "', 'þ'), '" ', 'þ') AS DATA FROM CTE_REMOVE_EXTRA_SPACES AS E ),
-- Add row id CTE_ADD_ROWID AS ( SELECT ROW_NUMBER() OVER (ORDER BY (SELECT 1)) AS ROWID, D.DATA FROM CTE_PLACE_DATA_DIVIDERS AS D ),
-- Add col id and split CTE_SPLIT_DATA AS ( SELECT R.ROWID, ROW_NUMBER() OVER (PARTITION BY R.ROWID ORDER BY R.ROWID) AS COLID, S.* FROM CTE_ADD_ROWID AS R CROSS APPLY STRING_SPLIT(R.DATA, 'þ') AS S )
-- Store results to be loaded INSERT INTO [STAGE].[COLVALS] SELECT * FROM CTE_SPLIT_DATA GO
Again, I timed this transformation step using both the S0 Standard database size that took 55:29 to process and the S3 Standard database size that took 18:49 to execute. Changing the database size decrease in overall execution time by 66.0%.
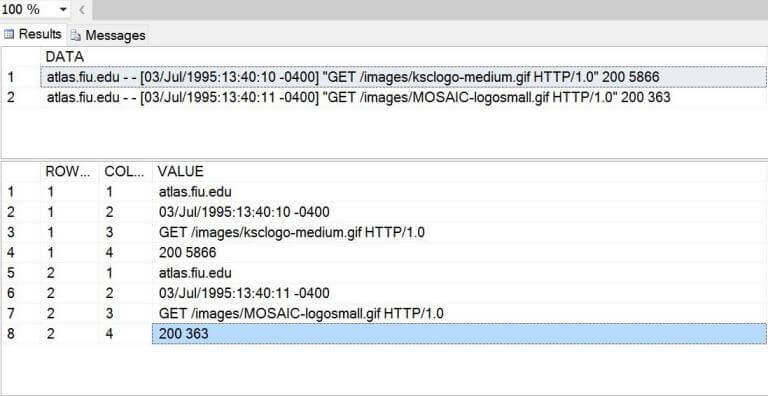
Run the following T-SQL statements to check the translation of the first two rows.
-- -- Show raw & parsed table data --
SELECT TOP 2 * FROM [NASA95].[STAGE].[WEBLOGS] SELECT TOP 8 * FROM [NASA95].[STAGE].[COLVALS] GO
It looks like most columns need a little more processing before we can insert the final results into the ACTIVE.WEBLOGS table. The nice thing about this row id, column id and column value table is the ability to insert further processing as different columns for the same row.
If each line of data parsed from the UNIX web log file was pristine, we should
have four column lines for every input line. Inspecting the data revealed this was
not the case. The image below shows a web entry without a corresponding line feed.
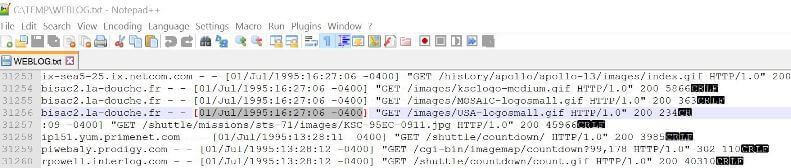
Thus the BCP program is loading two lines of data as one entry in the staging table. The first T-SQL batch below can be used to find the invalid entries and remove them from the STAGE.COLVALS table. The next T-SQL batch can be used to check records counts.
-- -- REMOVE BAD ROWS FROM TABLE --
BEGIN TRAN --SELECT * DELETE FROM STAGE.COLVALS WHERE ROWID IN ( SELECT DISTINCT ROWID FROM STAGE.COLVALS WHERE COLID >= 5 ) COMMIT GO
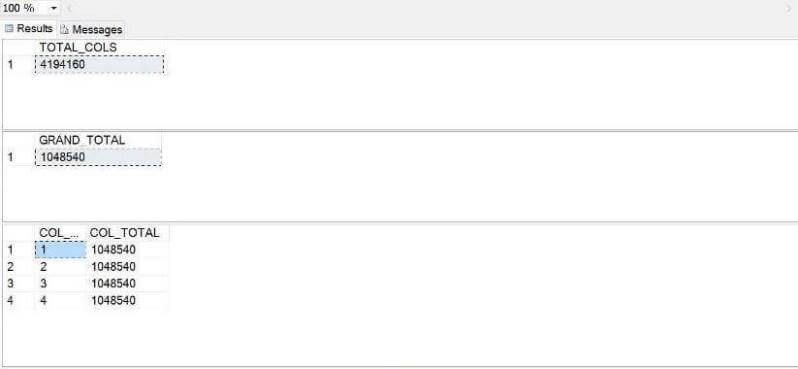
-- -- Show table counts --
SELECT COUNT(*) AS TOTAL_COLS FROM STAGE.COLVALS SELECT COUNT(DISTINCT ROWID) AS GRAND_TOTAL FROM STAGE.COLVALS GO
SELECT COLID AS COL_ID, COUNT(*) AS COL_TOTAL FROM STAGE.COLVALS GROUP BY COLID ORDER BY COLID GO
Rechecking the records counts after purging invalid records shows we now have
only pristine records ready for more processing.
Massaging Column Data
There are more transformations that need to be applied before the data can be inserted into the final table.
The forth column for each row contains both the status code of the web call and the number of bytes returned to the client. This data is delimited by a single space. We can call the STRING_SPLIT() function again to add this data as column id 5 and column id 6.
The third column contains the complete HTTP call. We want to determine if the call was a POST or a GET. This data is saved as column id 7. In addition, we want to parse out the web address without the call type and http version. This data is saved as column id 8.
The second column contains an invalid date. We want to transform and save the date in a valid format as column id 9.
The code below contains
the 4 T-SQL statements to massage the column data.
-- -- Massage data before pivoting --
-- Split HTTP Code N Bytes Returned INSERT INTO [NASA95].[STAGE].[COLVALS] SELECT C.ROWID, 4 + ROW_NUMBER() OVER (PARTITION BY C.ROWID ORDER BY C.ROWID), S.VALUE FROM [NASA95].[STAGE].[COLVALS] AS C CROSS APPLY STRING_SPLIT(C.VALUE, ' ') AS S WHERE COLID = 4 GO
-- What type of HTTP action? INSERT INTO [NASA95].[STAGE].[COLVALS] SELECT C.ROWID, 7, CASE WHEN VALUE LIKE 'GET%' THEN 'G' WHEN VALUE LIKE 'POST%' THEN 'P' ELSE NULL END AS VALUE FROM [NASA95].[STAGE].[COLVALS] AS C WHERE COLID = 3 GO
-- What web page part? INSERT INTO [NASA95].[STAGE].[COLVALS] SELECT C.ROWID, 8, REPLACE(REPLACE(REPLACE(C.VALUE, 'GET ', ''), 'POST ', ''), 'HTTP/1.0', '') AS VALUE FROM [NASA95].[STAGE].[COLVALS] AS C WHERE COLID = 3 GO
-- Format date correctly INSERT INTO [NASA95].[STAGE].[COLVALS] SELECT C.ROWID, 9, SUBSTRING(C.VALUE, 1, 11) + ' ' + SUBSTRING(C.VALUE, 13, 8) + ' ' + SUBSTRING(C.VALUE, 22, 3) + ':' + SUBSTRING(C.VALUE, 25, 2) AS VALUE FROM [NASA95].[STAGE].[COLVALS] AS C WHERE COLID = 2 GO
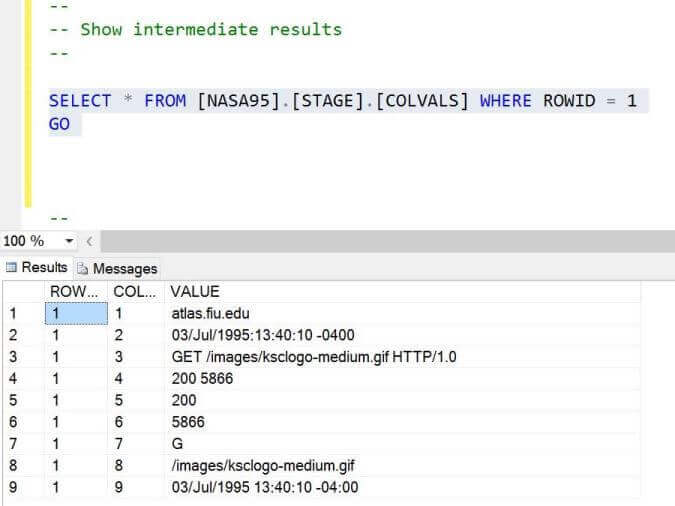
If we query the STAGE.COLVALS table for row id 1, we can see the initial
import as columns 1 to 4 and the data transformations as columns 5 to 9. Now we
have to select the columns that we want for each row and load the final target table.
Loading Active Table
The ACTIVE.WEBLOGS (target) table can be loaded by selecting the correct columns. The speed of the load process can be increased by adding a non-clustered index on row and column id.
Before loading the target table, we need to use the SET IDENTITY_INSERT statement ON so that we can supply our own row id numbers for the identity column.
The common table expression below picks up the 6 columns of data from the source table and places it into the destination table.
Before loading the target table, we need to
SET IDENTITY_INSERT statement OFF so that the identity column automatically
increments for future inserts.
-- -- Move data to final table --
-- Create index for speed CREATE NONCLUSTERED INDEX IDX_NC_ROW_N_COL ON [STAGE].[COLVALS] (ROWID, COLID) GO
-- Allow id inserts SET IDENTITY_INSERT ACTIVE.WEBLOGS ON GO
-- Convert to table format ; WITH CTE_COL1 AS ( SELECT ROWID, VALUE FROM [NASA95].[STAGE].[COLVALS] WHERE COLID = 1 ), CTE_COL2 AS ( SELECT ROWID, VALUE FROM [NASA95].[STAGE].[COLVALS] WHERE COLID = 8 ), CTE_COL3 AS ( SELECT ROWID, VALUE FROM [NASA95].[STAGE].[COLVALS] WHERE COLID = 9 ), CTE_COL4 AS ( SELECT ROWID, VALUE FROM [NASA95].[STAGE].[COLVALS] WHERE COLID = 7 ), CTE_COL5 AS ( SELECT ROWID, VALUE FROM [NASA95].[STAGE].[COLVALS] WHERE COLID = 5 ), CTE_COL6 AS ( SELECT ROWID, VALUE FROM [NASA95].[STAGE].[COLVALS] WHERE COLID = 6 ) INSERT INTO [ACTIVE].[WEBLOGS] ( WEB_LINE, WEB_HOST, WEB_PART, WEB_DATE, WEB_TYPE, WEB_RESULT, WEB_BYTES ) SELECT A.ROWID, A.VALUE, B.VALUE, C.VALUE, D.VALUE, E.VALUE, F.VALUE FROM CTE_COL1 A JOIN CTE_COL2 B ON A.ROWID = B.ROWID JOIN CTE_COL3 C ON A.ROWID = C.ROWID JOIN CTE_COL4 D ON A.ROWID = D.ROWID JOIN CTE_COL5 E ON A.ROWID = E.ROWID JOIN CTE_COL6 F ON A.ROWID = F.ROWID GO
-- Don't allow id inserts SET IDENTITY_INSERT ACTIVE.WEBLOGS OFF GO
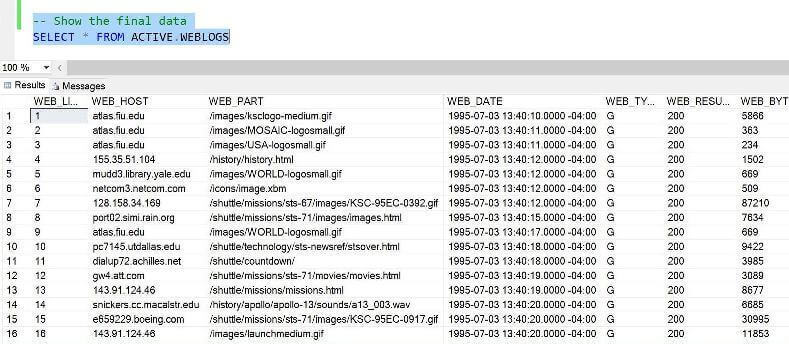
-- Show the final data SELECT * FROM ACTIVE.WEBLOGS
Executing a simple SELECT statement against the ACTIVE.WEBLOGS table shows
the NASA WEB LOG data in the final format that we wanted. In short, our business
problem is solved.
Summary
The new STRING_SPLIT() function works as advertised without any side effects. Today, we designed an ETL process to load data using the bulk copy program, massage data in a staging table and place the final results into an active table for analysis. All these steps could be bundled up into one SQL Agent Job to solve future business problems.
This solution was designed and implemented in Azure SQL Database.
The cloud is a great place to work. If your process is resource bound, just change
the database size to go faster. Of course, you will have to spend a few bucks to
do this. However, you can use PowerShell to ramp up and ramp down the database size
for intensive ETL processes.
Next Steps
- SQL Server 2016 introduced a couple more new T-SQL functions and next time, I will talk about the COMPRESS and DECOMPRESS functions.
- Check out the SQL Server 2016 tips






About the author
 John Miner is a Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
John Miner is a Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
